Khi ChatGPT giúp một developer đang “say nắng”!
Bạn đã bao giờ nghe Câu chuyện lập trình viên và chú vịt nhựa chưa? Đây là một giai thoại quen thuộc trong giới lập trình. Khi gặp lỗi trong chương trình, một lập trình viên bế tắc đã thử giải thích từng dòng code cho một chú vịt cao su trên bàn làm việc. Điều kỳ diệu xảy ra: khi nói ra vấn đề một cách chậm rãi và có cấu trúc, anh ta bất ngờ phát hiện ra lỗi mà trước đó không nhận thấy.
Ngày nay, thay vì chỉ nói chuyện với một chú vịt vô tri, các lập trình viên có một trợ thủ mạnh mẽ hơn: ChatGPT. Không chỉ đơn thuần lắng nghe, ChatGPT còn có thể phân tích lỗi, giải thích thuật toán, đề xuất cải tiến code và thậm chí giúp tư duy lại logic của bài toán. Việc đặt câu hỏi và trao đổi với AI giúp lập trình viên tiết kiệm thời gian, tối ưu code và nâng cao hiệu suất làm việc.
Một ngày vu vơ tôi lướt trên youtube và vô tình nhìn thấy một video thú vị. Thumbnail của video mô tả kiến trúc của một hệ thống dữ liệu lớn, lĩnh vực mà tôi đang quan tâm. Tôi tò mò xem trên đó có những gì.
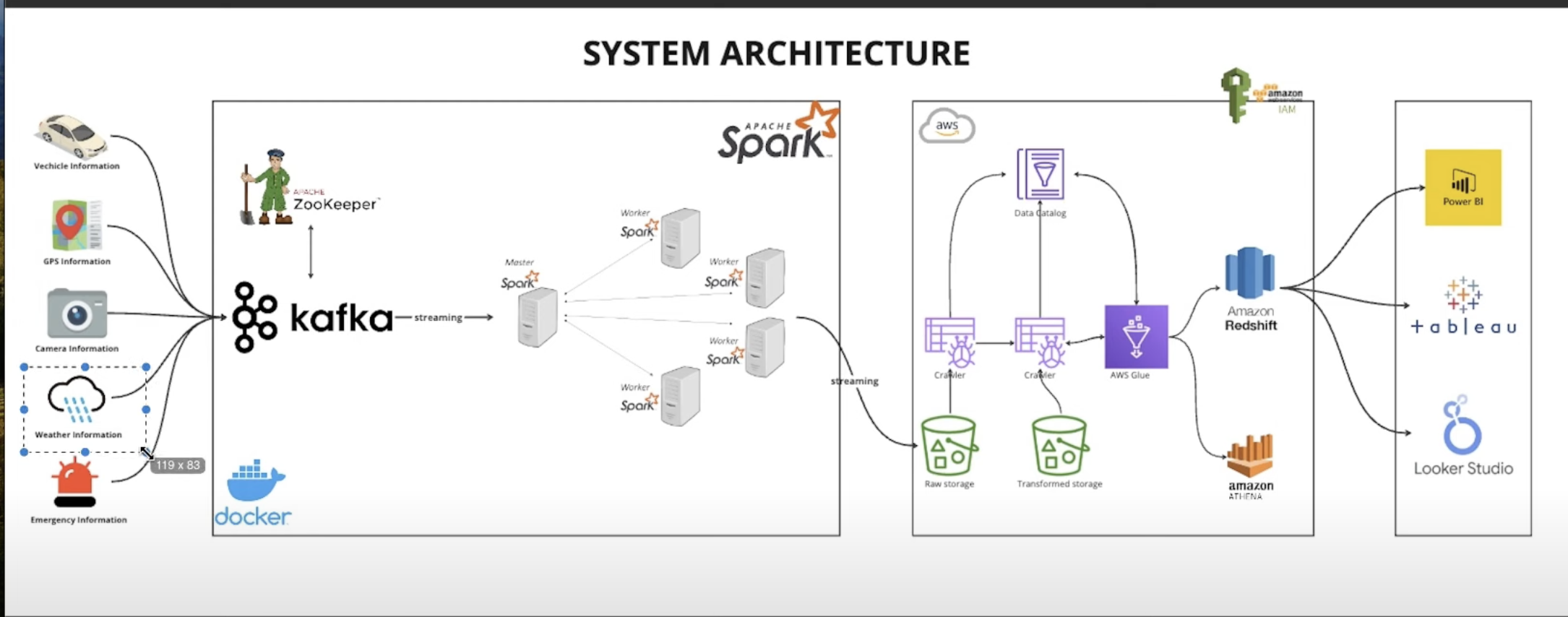
Chà, tôi thấy trên đó có logo của một số engine mà tôi biết, nhưng cũng có một số cái trông rất lạ. Có vẻ như hệ thống bắt đầu với nguồn thông tin đa dạng từ các phương tiện giao thông, dữ liệu định vị gps, thông tin từ các camera an ninh, dữ liệu thời tiết hay các dữ liệu cảnh báo khác. Nguồn dữ liệu ban đầu có vẻ như rất đa dạng về nguồn và về hình thức của dữ liệu. Phía sau đó, tôi thấy hệ thống được triển khai trên docker, rồi qua cloud với AWS platform. Cuối cùng tôi biết được Power BI và tableau là những công cụ phân tích, trực quan hóa dữ liệu vô cùng mạnh mẽ.
Quá lười để xem hết toàn bộ video, tôi đã chụp màn hình kiến trúc trên và mang đi hỏi anh bạn của tôi. “Này anh bạn, tôi muốn biết chính xác những gì đang xảy ra ở đây” và tôi nhận được câu trả lời khá chi tiết từ anh bạn của mình:
Dựa trên hình ảnh, đây là kiến trúc hệ thống sử dụng Kafka để xử lý dữ liệu theo thời gian thực (streaming). Mình sẽ phân tích từng phần:
1. Nguồn dữ liệu đầu vào (Data Sources)
- Hệ thống thu thập dữ liệu từ nhiều nguồn:
- Vehicle Information (Thông tin phương tiện)
- GPS Information (Dữ liệu GPS)
- Camera Information (Thông tin từ camera)
- Weather Information (Dữ liệu thời tiết)
- Emergency Information (Thông tin khẩn cấp)
- Những dữ liệu này có thể được gửi từ các thiết bị IoT, cảm biến, hoặc hệ thống giám sát giao thông.
2. Kafka & Apache Spark (Streaming & Processing Layer)
- Kafka đóng vai trò message broker, giúp thu thập và truyền tải dữ liệu từ các nguồn đầu vào.
- ZooKeeper được sử dụng để quản lý Kafka Cluster.
- Apache Spark thực hiện xử lý dữ liệu theo mô hình phân tán:
- Master Spark điều phối các Worker Spark.
- Các worker thực hiện xử lý dữ liệu streaming từ Kafka.
3. AWS Glue & Data Storage
- Dữ liệu từ Spark được lưu trữ trong AWS S3 với hai tầng:
- Raw Storage: Lưu trữ dữ liệu gốc.
- Transformed Storage: Dữ liệu đã qua xử lý.
- AWS Glue đóng vai trò ETL (Extract, Transform, Load):
- Crawler: Thu thập và lập chỉ mục dữ liệu.
- Data Catalog: Lưu trữ metadata của dữ liệu.
4. Data Warehouse & Querying
- Amazon Redshift và Amazon Athena cho phép truy vấn dữ liệu từ S3.
- IAM được sử dụng để quản lý quyền truy cập.
5. Visualization & Reporting
- Dữ liệu được truy vấn và phân tích thông qua các công cụ BI:
- Power BI
- Tableau
- Looker Studio
Tóm tắt quy trình
- Dữ liệu từ các thiết bị (xe, GPS, camera…) được gửi đến Kafka.
- Kafka phân phối dữ liệu cho Spark để xử lý.
- Dữ liệu sau xử lý được lưu vào S3, rồi AWS Glue thu thập thông tin.
- Amazon Redshift & Athena hỗ trợ truy vấn dữ liệu.
- Các công cụ BI hiển thị dữ liệu trên dashboards.
Ứng dụng thực tế
- Hệ thống giám sát giao thông thông minh.
- Phân tích hành vi lái xe và dự báo sự cố.
- Giám sát thời tiết và ảnh hưởng đến giao thông.
- Hệ thống cảnh báo sớm cho các phương tiện.
Chà, đọc qua những nội dung trên thì tôi đã khá là hiểu đây là một hệ thống end to end realtime data enginering. Tôi đã làm việc với data một thời gian nhưng tôi chỉ thực hiện một công đoạn trong luồng xử lý của một hệ thống lớn để đưa ra giá trị cuối cùng của dữ liệu. Tôi biết để tôi cải thiện những góc nhìn chính xác hơn về dữ liệu, tôi cần hiểu tổng quát cách một hệ thống dữ liệu lớn hoạt động. Tôi tự hỏi mình có thể tự xây dựng một hệ thống như vậy hay không. Để đạt được kết quả, cuối cùng, tôi phải đi những bước đầu tiên. Tôi đã nghe kha khá về Kafka tuy nhiên tôi chưa biết nó hoạt động như thế nào. Tôi quyết định sẽ dành thời gian để tìm hiểu về kafka và để tiết kiệm thời gian, tôi sẽ học cùng với anh bạn của mình. Chậm rãi, từng bước một, có thể tôi sẽ chia sẻ một số điều học được ở bài viết sau!
Tìm hiểu về “đối tượng” bằng con đường ChatGPT!
Giới thiệu tổng quan về data warehouse