Pro Git (P2)
1.2 Git là gì?
Ở phần trước chúng ra đã tìm hiểu qua về Version Control, nắm được một số khái niệm cơ bản, hiểu về cơ chế hoạt đông cũng như một số loại hình kiểm soát phiên bản. Trong phần này, chúng ta sẽ cùng nhau tìm hiểu sâu hơn về Git. Nắm được Git là gì và cùng tìm ra điểm mạnh, điểm yếu của Git so với các Version Control System khác. Bạn có thể tìm đọc phần 1 của loạt bài viết này tại đây.
Lịch sử ngắn của Git
Cũng như nhiều điều tuyệt vời trong cuộc sống, Git bắt đầu với một chút sáng tạo, phá hủy và sự tranh cãi nảy lửa.
Nhân Linux là một dự án phần mềm nguồn mở có phạm vi khá lớn. Trong phần lớn thời gian bảo trì hạt nhân Linux (1991 – 2002), các thay đổi đối với phần mềm được chuyển qua dưới dạng các bản vá và tệp lưu trữ. Năm 2002, dự án nhân Linux đã bắt đầu sử dụng một DVCS độc quyền có tên BitKeeper.
Năm 2005, mối quan hệ giữa cộng đồng phát triển nhân Linux và công ty thương mại phát triển BitKeeper đã bị phá vỡ và tình trạng miễn phí của công cụ đã bị hủy bỏ. Điều này đã thúc đẩy cộng đồng phát triển Linux (và đặc biệt là Linus Torvalds, người tạo ra Linux) phát triển công cụ của riêng họ dựa trên một số bài học mà họ đã học được khi sử dụng BitKeeper. Một số mục tiêu của hệ thống mới như sau:
- Tốc độ
- Thiết kế đơn giản
- Hỗ trợ mạnh mẽ cho sự phát triển phi tuyến tính (hàng ngàn nhánh song song)
- Phân phối đầy đủ
- Có thể xử lý các dự án lớn như nhân Linux một cách hiệu quả (tốc độ và kích thước dữ liệu)
Kể từ khi ra đời vào năm 2005, Git đã phát triển và trưởng thành để dễ sử dụng và vẫn giữ được những phẩm chất ban đầu này. Nó nhanh đến mức đáng kinh ngạc, nó rất hiệu quả với các dự án lớn và nó có một hệ thống phân nhánh đáng kinh ngạc để phát triển phi tuyến tính (Xem Git Branching ).
Git là gì?
Vậy, Git là gì? Điều này rất quan trọng bởi vì nếu bạn hiểu Git là gì và các nguyên tắc cơ bản về cách thức hoạt động của nó thì bạn sẽ có thể sử dụng Git hiệu quả và dễ dàng hơn. Khi bạn học Git, hãy cố gắng hiểu thật rõ ràng những điều bạn đã biết về các VCS khác, chẳng hạn như CVS, Subversion hoặc Perforce – như vậy sẽ giúp bạn tránh nhầm lẫn khi sử dụng. Mặc dù giao diện người dùng của Git khá giống với các VCS khác, Git lưu trữ và xử lí thông tin theo một cách rất khác. Hiểu về những khác biệt này sẽ giúp bạn tránh bị nhầm lẫn trong khi sử dụng.
Snapshots, Not Differences
Sự khác biệt chính giữa Git và bất kỳ VCS nào khác (Bao gồm cả các subversion và những công cụ tương tự) là cách Git làm việc với dữ liệu của nó. Về mặt khái niệm, hầu hết các hệ thống khác lưu trữ thông tin dưới dạng danh sách các thay đổi dựa trên tệp. Các hệ thống khác (CVS, Subversion, Perforce, Bazaar, v.v.) thao tác với thông tin họ lưu trữ dưới dạng tập hợp các tệp và các thay đổi được thực hiện cho từng tệp theo thời gian (điều này thường được mô tả là kiểm soát phiên bản dựa trên delta ).
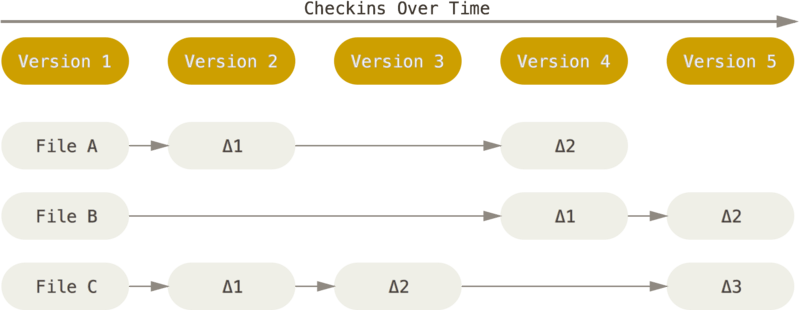
Hình 4. Lưu trữ dữ liệu khi thay đổi phiên bản cơ sở của mỗi tệp.
Git không thao tác hoặc lưu trữ dữ liệu theo cách này. Thay vào đó, Git thao tác với dữ liệu của nó giống như một loạt “snapshots” của một hệ thống tập tin thu nhỏ. Với Git, mỗi khi bạn “commit” hoặc lưu trạng thái của dự án, Git về cơ bản sẽ chụp lại các tệp tại thời điểm đó và lưu trữ một tham chiếu đến ảnh chụp nhanh đó. Để hiệu quả, nếu các tệp không thay đổi, Git không lưu trữ tệp một lần nữa, chỉ là một liên kết đến tệp giống hệt trước đó mà nó đã được lưu trữ. Git thao tác với dữ liệu của nó giống như một luồng ảnh chụp nhanh(a stream of snapshots).

Hình 5. Lưu trữ dữ liệu dưới dạng ảnh chụp nhanh của dự án theo thời gian.
Đây là một sự khác biệt quan trọng giữa Git và gần như tất cả các VCS khác. Nó khiến Git xem xét lại gần như mọi khía cạnh của kiểm soát phiên bản mà hầu hết các hệ thống khác được sao chép từ thế hệ trước. Điều này làm cho Git giống như một hệ thống tệp nhỏ với một số công cụ cực kỳ mạnh mẽ được xây dựng trên nó, thay vì chỉ đơn giản là một VCS.
Gần như mọi hoạt động là cục bộ
Hầu hết các hoạt động trong Git chỉ cần các tệp và tài nguyên cục bộ để hoạt động – nói chung không cần thông tin từ một máy tính khác trong mạng của bạn. Nếu bạn đã quen với CVCS nơi hầu hết các hoạt động đều có chi phí cho độ trễ mạng của nó, khía cạnh này của Git sẽ khiến bạn có thể nảy ra suy nghĩ rằng các vị thần tốc độ đã ban phước cho Git với sức mạnh phi thường. Vì bạn có toàn bộ lịch sử của dự án ngay trên đĩa cục bộ của mình, nên hầu hết các hoạt động dường như gần như tức thời.
Ví dụ, để duyệt lịch sử của dự án, Git không cần phải ra máy chủ để lấy lịch sử và hiển thị nó cho bạn – nó chỉ cần đọc trực tiếp từ cơ sở dữ liệu cục bộ của bạn. Điều này có nghĩa là bạn thấy lịch sử dự án gần như ngay lập tức. Nếu bạn muốn xem các thay đổi được giới thiệu giữa phiên bản hiện tại của tệp và tệp một tháng trước, Git có thể tra cứu tệp một tháng trước và thực hiện phép tính chênh lệch cục bộ, thay vì phải yêu cầu máy chủ từ xa thực hiện hoặc kéo một phiên bản cũ hơn của tệp từ máy chủ từ xa để thực hiện cục bộ.
Điều này cũng có nghĩa là có rất nhiều điều bạn có thể làm nếu bạn ngoại tuyến hoặc tắt VPN. Nếu bạn lên máy bay hoặc tàu hỏa và muốn thực hiện một công việc nhỏ, bạn có thể “commit” một cách vui vẻ (với bản sao “local” của mình) Cho đến khi bạn kết nối mạng để tải lên. Nếu bạn về nhà và VPN của bạn không hoạt động, bạn vẫn có thể làm việc. Trong nhiều hệ thống khác, những tiện ích như vậy là không thể có hoặc rất khó khăn để làm việc. Ví dụ, trong Perforce, bạn không thể làm gì nhiều khi không kết nối với máy chủ; trong Subversion và CVS, bạn có thể chỉnh sửa các tệp, nhưng bạn không thể cam kết thay đổi cơ sở dữ liệu của mình (vì cơ sở dữ liệu của bạn đang ngoại tuyến). Điều này có vẻ không phải là một “huge deal”, nhưng bạn có thể ngạc nhiên về sự khác biệt lớn mà nó có thể tạo ra.
Git có tính toàn vẹn
Mọi thứ trong Git đều được kiểm tra trước khi nó được lưu trữ và sau đó được gọi lại bằng “checksum” đó. Điều này có nghĩa là không thể thay đổi nội dung của bất kỳ tệp hoặc thư mục nào mà không có Git biết về nó. Chức năng này được tích hợp vào Git ở mức thấp nhất và không thể thiếu trong triết lý của nó. Khi bạn bị mất thông tin quá cảnh hoặc bị hỏng tập tin, Git sẽ hoàn toàn phát hiện ra điều đó.
Cơ chế mà Git sử dụng cho việc kiểm tra này được gọi là hàm băm SHA-1. Đây là một chuỗi 40 ký tự bao gồm các ký tự thập lục phân (0-9 và a-f) và được tính toán dựa trên nội dung của cấu trúc tệp hoặc thư mục trong Git. Mã băm SHA-1 trông giống như thế này:
24b9da6552252987aa493b52f8696cd6d3b00373
Bạn sẽ thấy các giá trị băm này ở khắp mọi nơi trong Git vì nó sử dụng chúng rất nhiều. Trên thực tế, Git lưu trữ mọi thứ trong cơ sở dữ liệu của nó không phải bằng tên tệp mà bằng giá trị băm của nội dung của nó.
Git thường chỉ thêm dữ liệu
Khi bạn thực hiện các hành động trong Git, gần như tất cả chúng chỉ thêm dữ liệu vào cơ sở dữ liệu Git. Thật khó để khiến hệ thống làm bất cứ điều gì không thể hoàn tác hoặc làm cho nó xóa dữ liệu theo bất kỳ cách nào. Như với bất kỳ VCS nào, bạn có thể mất hoặc làm hỏng các thay đổi bạn chưa cam kết (commit). Nhưng sau khi bạn cam kết một ảnh chụp nhanh(commit a snapshot) vào Git,nó sẽ rất khó để mất, đặc biệt là nếu bạn thường xuyên đẩy cơ sở dữ liệu của mình sang kho lưu trữ khác.
Điều này làm cho việc sử dụng Git trở thành niềm vui bởi vì chúng tôi biết rằng chúng tôi có thể thử nghiệm mà không gặp nguy hiểm khi làm hỏng mọi thứ. Để có cái nhìn sâu hơn về cách Git lưu trữ dữ liệu của nó và cách bạn có thể khôi phục dữ liệu dường như bị mất, hãy đón đọc tiếp ở những phần tiếp theo.
3 trạng thái của git
Hãy chú ý ngay bây giờ – đây là điểm chính cần ghi nhớ về Git nếu bạn muốn phần còn lại của quá trình nghiên cứu của mình diễn ra suôn sẻ. Git có ba trạng thái chính: modified, staged, and committed:
- modified có nghĩa là bạn đã thay đổi tệp nhưng chưa cam kết nó với cơ sở dữ liệu của bạn.
- staged có nghĩa là bạn đã đánh dấu một tệp đã sửa đổi trong phiên bản hiện tại của nó để đi vào “commit snapshot” tiếp theo của bạn.
- committed có nghĩa là dữ liệu được lưu trữ an toàn trong cơ sở dữ liệu cục bộ của bạn.
Điều này dẫn chúng ta đến ba phần chính của dự án Git: cây làm việc(the working tree), khu vực tổ chức(the staging area) và thư mục Git(the Git directory).
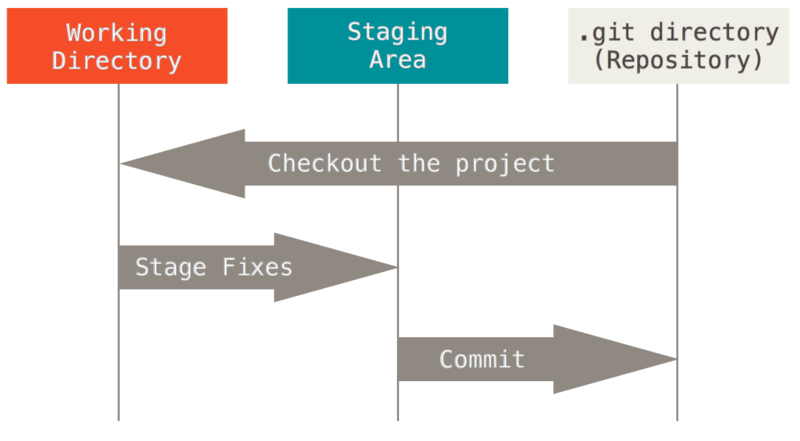
Hình 6. Cây làm việc, khu vực tổ chức và thư mục Git.
Cây làm việc là sự kiểm soát duy nhất của một phiên bản trước khi chuyển qua một phiên bản khác của dự án. Các tệp này được kéo ra khỏi cơ sở dữ liệu nén trong thư mục Git và được đặt ở đĩa để bạn sử dụng hoặc sửa đổi.
Khu vực tổ chức là một tệp, thường được chứa trong thư mục Git của bạn, lưu trữ thông tin về những gì sẽ thay đổi vào cam kết tiếp theo của bạn. Tên kỹ thuật của nó theo cách nói của Git là index , nhưng cũng có thể gọi nó với cụm từ staging area (khu vực tổ chức).
Thư mục Git là nơi Git lưu trữ cơ sở dữ liệu đối tượng và dữ liệu(metadata) cho dự án của bạn. Đây là phần quan trọng nhất của Git và nó là phần được sao chép khi bạn sao chép một kho lưu trữ từ một máy tính khác.
Quy trình công việc Git cơ bản diễn ra như sau:
- Bạn sửa đổi các tập tin trong cây làm việc của bạn.
- Bạn chọn lọc các giai đoạn đã thay đổi mà bạn muốn là một phần của cam kết(commit) tiếp theo, chỉ thêm những thay đổi đó vào khu vực tổ chức(staging area).
- Bạn thực hiện một cam kết, sẽ lấy các tệp khi chúng ở trong khu vực tổ chức(staging area) và lưu trữ ảnh chụp nhanh(snapshot) đó vào thư mục Git của bạn.
Nếu một phiên bản cụ thể của tệp nằm trong thư mục Git, nó được coi là committed. Nếu nó đã được sửa đổi và được thêm vào staging area, đó là staged. Và nếu phiên bản cụ thể của tệp đã được thay đổi kể từ khi nó được kiểm tra nhưng chưa được dàn dựng, nó đã được modified . Trong những chương sau, bạn sẽ tìm hiểu thêm về các trạng thái này và cách bạn có thể tận dụng lợi thế của chúng hoặc bỏ qua phần dàn dựng hoàn toàn.
Kết luận
Trong phần này, chúng ta đã nắm được những điểm mạnh cũng như lợi ích và sự khác biệt của Git so với những Version Control System khác. Ở phần tiếp theo, chúng ta sẽ cùng tìm hiểu các cách thức cài đặt Git trên những hệ điều hành khác nhau và bắt đầu làm quen với hệ thống Git thực tế trên máy tính của mình.
Đón đọc phần tiếp theo tại đây

Git Pro: Những thao tác cơ bản khi làm việc với Git (P2) – Commit History & Undo

Git Pro (P4)