Enterprise Cloud Computing [Part 1][Retrospective]
Giới thiệu
Gần đây tôi được suggest cuốn sách Enterprise Cloud Computing. Chủ đề Cloud Computing có vẻ không còn là mới mẻ (thuật ngữ ra đời từ năm 2007). Tuy nhiên cuốn sách giúp chúng ta nhìn nhận được sự phát triển của các kiến trúc và công nghệ Enterprise Computing qua từng thời kỳ.
Tác giả của cuốn sách là Dr.Gautam Shroff người Ấn Độ https://www.coursera.org/instructor/~137. Trong phần mở đầu tác giả có nhắc đến các sự thay đổi lớn trong thế giới IT. PC trong thập niên 80, Internet trong thập niên 90, SOA trong những năm 2000 và những năm gần đây hay nhắc tới ‘cloud computing’. Cuốn sách xoay quanh việc nói đến cloud computing technology, architectures và applications.
Trong phần đầu này chúng ta có thể chưa nhắc đến Cloud Computing và có lẽ dành chút thời gian để tìm hiểu về lịch sử ra đời của các kiến trúc enterprise computing.
Enterprise computing – a retrospective
Như tiêu đề của chapter, ở đây chúng ta sẽ cùng nhìn lại lịch sử của ‘Enterprise Computing’. Vậy Enterprise Computing là gì? Nó là một thuật ngữ “buzzword” bằng việc sử dụng công nghệ thông tin cho việc xử lý dữ liệu theo định hướng kinh doanh trong các công ty, tổ chức.
1. Kiến trúc Mainframe
Bắt đầu từ những năm 60, sử dụng máy tính cho tính toán dữ liệu trên các máy tính lớn (mainframe) với IBM System/360. Định nghĩa MainFrame: là loại máy tính có kích thước lớn được sử dụng chủ yếu bởi các công ty lớn như các ngân hàng, các hãng bảo hiểm… để chạy các ứng dụng lớn xử lý khối lượng lớn dữ liệu như kết quả điều tra dân số, thống kê khách hàng và doanh nghiệp, và xử lý các giao tác thương mại.
Dòng máy tính của IBM vẫn là phổ biến nhất với IBM z-series (chữ z nghĩa là zero-downtime)
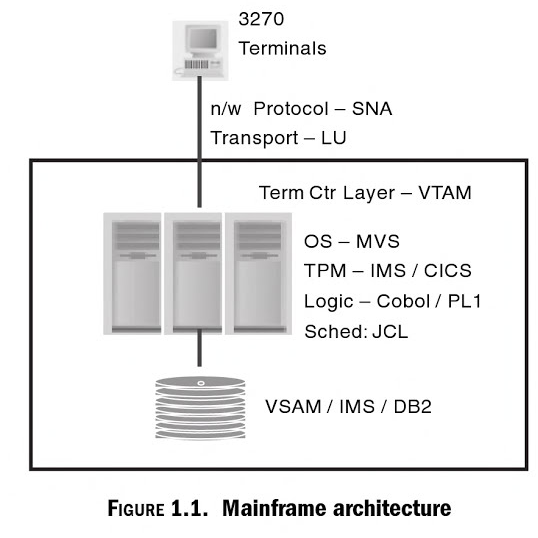
Như hình vẽ trên, một terminal-based sẽ hiển thị kết quả điều khiển bởi frame server thông qua giao thức VTAM (Virtual Telecommunications Access Method) Terminal kết nối với mainframe server qua giao thức SNA (System Network Architecture). Nhược điểm của máy tính mainframe là giới hạn của CPU power theo các tiêu chuẩn của dòng máy, do đó các ứng dụng mainframe được xây dựng theo kiến trúc batch processing để giảm thiểu utilizations của CPU trong việc ghi và lấy dữ liệu. Dữ liệu được ghi ngay xuống disk và được xử lý bởi các background programs.
Trong những kiến trúc mainframe ban đầu, dữ liệu của ứng dụng được lưu trữ trong các file có cấu trúc (structured files) hoặc database system dựa trên hierarchial hoặc network data model. Ví dụ Hierarchial IMS database của IBM. Sau đó, Relational model (RDBMS) được đưa ra từ thập niên 70 và được ra mắt thương mại vào giữa những năm 80 với sự xuất hiện của IBM’s DB2 trên máy tính mainframe và sự cài dặt của Oracle trên nền tảng Unix.
2. Kiến trúc Client Server
Những năm 80 là thời đại của cách mạng microprocessor, máy tính PC đã trở nên phổ biến trong gia đình và các doanh nghiệp. Dữ liệu xử lý được chuyển dịch từ các máy tính mainframe đắt tiền sang các máy tính desktop. Terminals trở nên khó khăn cho việc sử dụng và chủ yếu chỉ dùng trong việc xử lý data processing. Thêm vào đó, các cơ sở dữ liệu quan hệ như Oracle đã hỗ trợ trên các máy minicomputer (các dòng máy tính cỡ trung giá thành rẻ hơn mainframe). Cuối cùng, network sử dụng TCP/IP nhanh chóng trở thành 1 tiêu chuẩn cho mạng máy tính PC và minicomputers có thể chia sẻ dữ liệu.
Tất cả các việc trên dẫn tới sự ra đời của công nghệ mới. Trong hình dưới đây chỉ ra kiến trúc của hệ thống client-server.
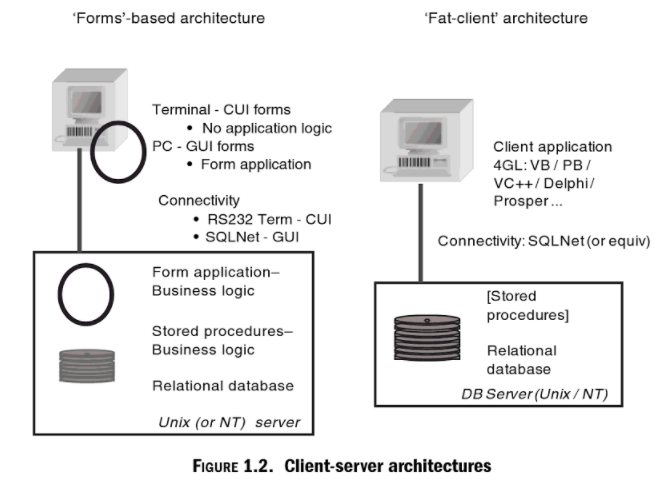
Đầu tiên, Forms-based architecture cho các dòng máy minicomputers xử lý dữ liệu. Kiến trúc này yêu cầu sử dụng terminal để truy cập vào server-side, tương tự kiến trúc mainframe. Sau này trên các dòng máy PC, các ứng dụng hỗ trợ giao diện GUI (đối lập với terminal-based character-oriented CUIs). Mô hình GUI Forms chính là kiến trúc client-server đầu tiên.
Trong kiến trúc client-server, việc xử lý logic chính nằm ở client application, ví dụ như máy tính PC. Dẫn tới kiến trúc client-server trở thành kiến trúc fat-client như hình bên phải. Các ứng dụng client (fat-client) trực tiếp truy vấn vào cơ sở dữ liệu quan hệ (sử dụng SQL) qua các giao thức mạng như SQL/NET, chạy trên mạng network TCP/IP. Xử lý nghiệp vụ logic dựa trên phía client application và người ta thường hay sử dụng “stored procedures”.
Trong những năm 90, cách mạng client-server mang lại các thành công của các sản phẩm phần mềm như SAP-R/3 (sản phẩm phần mềm ERP)
Tuy nhiên kiến trúc client-server dần dần bộc lộ ra các nhược điểm khi triển khai trong các tổ chức lớn. Việc dễ thấy nhất khi triển khai deploy trên mạng lưới rộng lớn. Kết quả là nhiều tổ chức toàn cầu bắt buộc phải tạo ra các regional data centers, và sao lưu đồng bộ chúng với nhau. Chính kiến trúc này đã biểu hiện sự bất tiện khi quản lý upgrade phần mềm trên diện rộng.
=> Mô hình client-server không thể scale
3. Kiến trúc 3-Tier architectures với TP monitors
Vì sao kiến trúc client-server lại fail khi scale cho việc xử lý transaction lớn. Không phải vì CPUs của các máy tính PC thấp kém hơn mainframes (sự thật là những năm 90, RISC CPUs đã vượt qua mainframe trong việc xử lý dữ liệu thô). Lý do chính là do không giống như mainframe, kiến trúc client-server không có Virtual Machine Layer hay Job Control System để điều khiển và giới hạn sự truy cập tài nguyên như CPU và disk.

Hình vẽ trên mô tả việc 10.000 máy clients kết nối với server sẽ tạo ra 10.000 connections, 10.000 processes, 5000 MB Ram, 100 000 open files …. => dẫn đến server-side crash.
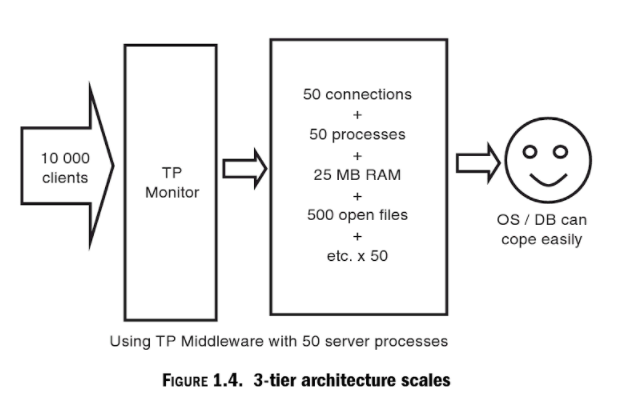
Hình vẽ trên mô tả việc sử dụng TP Monitor (Transaction Processing Monitor) để giải quyết vấn đề trên. TP monitors là các ví dụ đầu tiên về ‘middleware’, nó nằm dữa clients và database server để điều khiển việc truy cập tài nguyên server.
Trong kiến trúc TP monitor, các request được xử lý bằng queue. TP monitor model được biết đến như là kiến trúc 3-tier model, trong đó client, business và data layers được tách ra rõ ràng và thường nằm trên các máy tính riêng biệt, như hình dưới.
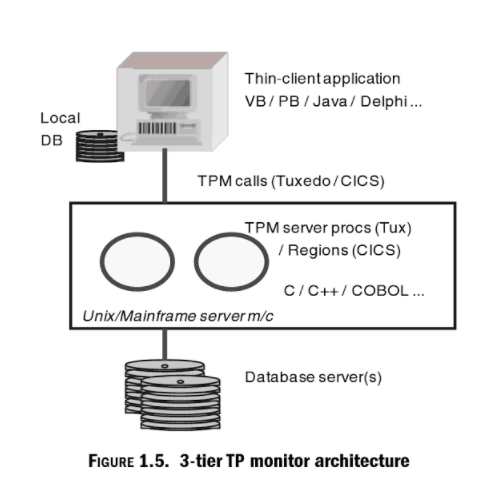
4. Tổng kết
Chúng ta đã có được cái nhìn tổng quan về kiến trúc mainframe, client-server và 3-tier. Trong bảng so sánh dưới đây sẽ giúp chúng ta tổng kết lại được những tính năng cơ bản của mỗi kiến trúc và chuẩn bị cho việc tìm hiểu đến Enterprise Cloud Computing ở phần sau.
| Comparison of Architectures | |||
| Main Frame | Client Server | 3- Tier | |
| User interface | Terminal screens controlled by the server | ‘Fat Client’ applications making database request over SQL/NET | ‘Thin Client’ desktop applications making service requests via RPC or CORBA |
| Business Logic | Batch oriented processing | Online processing in client application and stored procedures in the database | Executed on a middle tier of services published by the TP moinitor layer |
| Data store | File structures, hierarchical or network databases (later relational) | Relational databases | Relational databases |
| Programming languages | PL/1, Cobol | 4GLs: Visual Basic, Powerbuilder, (later Java) | 4GLs on client, 3GLs such as C and C++ on server |
| Server operating system | MVS, z/OS, VAX | Unix | Unix, Linux |
| Time line | 70s to date | 80s through late 90s | mid-late 90s |
| Advantages (at the times) | Reliable enterprise data processing, VIrtual machine technology, Fault tolerance | Cheaper than mainframes, leveraged desktop computing power; online transactions vs batch processing | Load balancing for scalability as compared to client-server; structuring of applicaitons into presentation and business logic layers |
| Disadvantages (at the time) | Batch oriented processing | Did not scale over wide area networks or for high transaction volumes | Lack of standards |
| User/Developer friendliness | Cryptic user interfaces and low level programming | Intuitive graphical user interaface and high-level languges | Intuitive user interfaces but more complex distributed programming |
| Key lessons for today- especially in cloud context | Virtualization and fault tolerance | Perils of distribution | Load balancing |