Like! — Chúng tôi từ bỏ Cache Layer như thế nào?
“Thời gian là tiền bạc”
Sáo ngữ trên thường được nói khi muốn nhắc nhở về sự quý giá của thời gian. Không ai thích phải chờ đợi, nhưng đôi khi ta thường không hình dung rõ ràng thời gian được quy đổi ra tiền như thế nào. Theo như một thống kê của Amazon và Google, họ đã phải trả chi phí vô cùng lớn cho mỗi giây phản hồi chậm trễ.
Và để tăng tốc độ phản hồi, một trong nhưng phương pháp phổ biến nhất là sử dụng Cache. Áp dụng cơ chế caching sẽ tăng trải nghiệm từ người dùng cũng như tiết kiệm tiền bạc rất lớn cho một hệ thống. Chi phí tích hợp thấp, lợi ích thu lại rõ rệt khiến cache dễ dàng phổ biến. Cache thường dùng cho các dữ liệu không hoặc ít thay đổi và được lưu trên Memory (CPU L1, L2, RAM), qua đó giảm tải hệ thống bởi những thao tác xử lý tại persistence khác có chi phí tìm kiếm đắt đỏ hơn (cụ thể như filesystem nằm trên Disk). Trong các kiến trúc truyền thống, cache thường đặt bên cạnh database để tận dụng tốc độ hay sự ổn định của cả 2 ở từng tình huống. Mô hình này thường được biết đến dưới tên gọi Cache layer hoặc Cache aside.
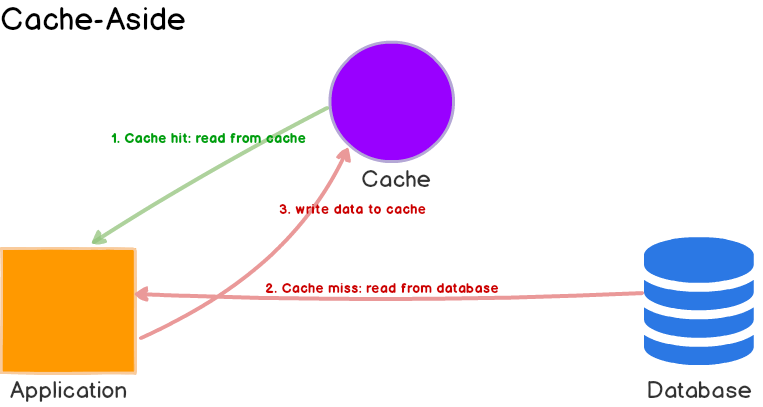
Nhưng ngoài lợi ích về tốc độ, cache cũng có vấn đề của chính mình khiến quá trình sử dụng nó gây ra không ít rắc rối, ví dụ như Cache Invalidation.
There are only two hard problems in Computer Science: Cache Invalidation and naming things. — Phil Karlton

Vậy tại sao việc này lại khó đến vậy?
https://www.quora.com/What-makes-cache-invalidation-a-deceptively-hard-problem
Như giải thích chi tiết từ Quora phía trên, nó đến từ việc có quá nhiều luồng tương tác với dữ liệu mà ta không thể quản lý được hoặc cần tốn rất nhiều công sức cho logic đọc/ghi để đảm bảo data consistency (cache inconsistency & cache coherence) cũng như tránh khỏi race condition. Nếu bạn làm việc với một hệ thống lớn, phức tạp, đặc biệt là phân tán, những khó khăn này sẽ được nhân lên gấp bội.
Được biết rằng tại Netflix đã áp dụng một cache platform là EVCache để giải quyết những hạn chế trên. EVCache đã trở thành một thành phần không thể thiếu của họ. Tuy nhiên, nhược điểm của nó là kiến trúc quá cồng kềnh, không thích hợp các hệ thống vừa và nhỏ vì đi kèm chi phí tích hợp lớn.
Bên cạnh đó, Cache nói chung và kiến trúc Cache-aside nói riêng cũng có thêm các nhược điểm như:
- Khi data tăng trưởng, bạn cũng cần nâng cấp dung lượng cho hệ thống cache của mình để duy trì chỉ số cache hit (nên tối thiểu 80%).
- Nếu hệ thống của bạn có dung lượng data lớn, phân tán trên nhiều nodethì việc phục hồi cache (đưa dữ liệu từ database vào lại RAM như trong những trường hợp system crashed) sẽ mất nhiều thời gian hơn đáng kể.
- Trong trường hợp cache management bị crashed đột ngột (hoặc đôi khi chỉ đơn giản là expired), khiến cache hit bị missed, tất cả các request sẽ đồng thời đẩy xuống database làm cho nó có thể bị spikes, mục đích tối ưu tốc độ thất bại, cũng như có thể gây những ảnh hưởng đến xử lý (thậm chí sụp đổ) của toàn ứng dụng. Hiện tượng này thường biết đến là Cache Stampede
- Khi hệ thống của bạn phát triển, sharding và clustering là nhu cầu tất yếu. Tuy nhiên, logic sharding dữ liệu là phức tạp và các cache management phổ biến thường không hỗ trợ [tốt] việc này. Bạn sẽ mất nhiều công sức để xây dựng logic này (giống như Netflix đã làm với EVCache).
Với những nhược điểm như vậy, chúng ta cần đánh giá lại vai trò của một layer cache độc lập bên cạnh database trong kiến trúc truyền thống ở trên.
In-Memory + NoSQL = Hybrid Memory DB
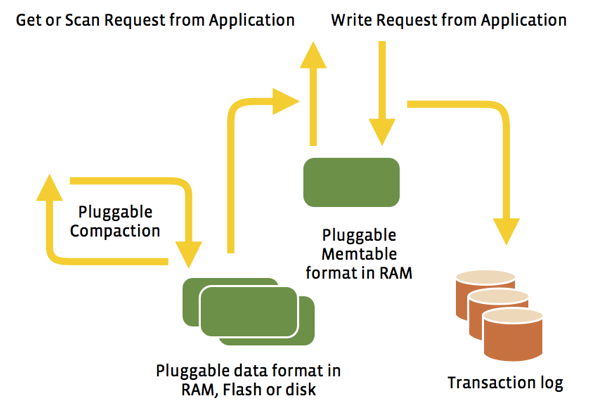
Có thể bạn sẽ thắc mắc với đề mục phía trên, “tại sao lại là NoSQL mà không phải Relational-Database Management System (RDBMS)?” — Câu trả lời đơn giản là: Một In-memory RDBMS thì vẫn chỉ là RDBMS! Nó vẫn sẽ là một mô hình dữ liệu cứng nhắc, thiếu linh hoạt. Khi bạn cần đến Cache, đồng nghĩa là bạn cần tối ưu hóa cho thao tác đọc. Và như đã nói ở trên, RAM (cũng như các bộ nhớ Flash khác) cho tốc độ đọc nhanh nhưng các RDBMS phổ biến lại chưa bao giờ được thiết kế để làm việc trên những bộ nhớ dạng này. Thêm vào đó, RDBMS sẽ gặp vấn đề về hiệu năng đọc/ghi với dữ liệu lớn nếu không được tối ưu đúng cách (Vd: Index fragmentation). Càng tệ hơn nữa khi nó nằm trong môi trường phân tán.
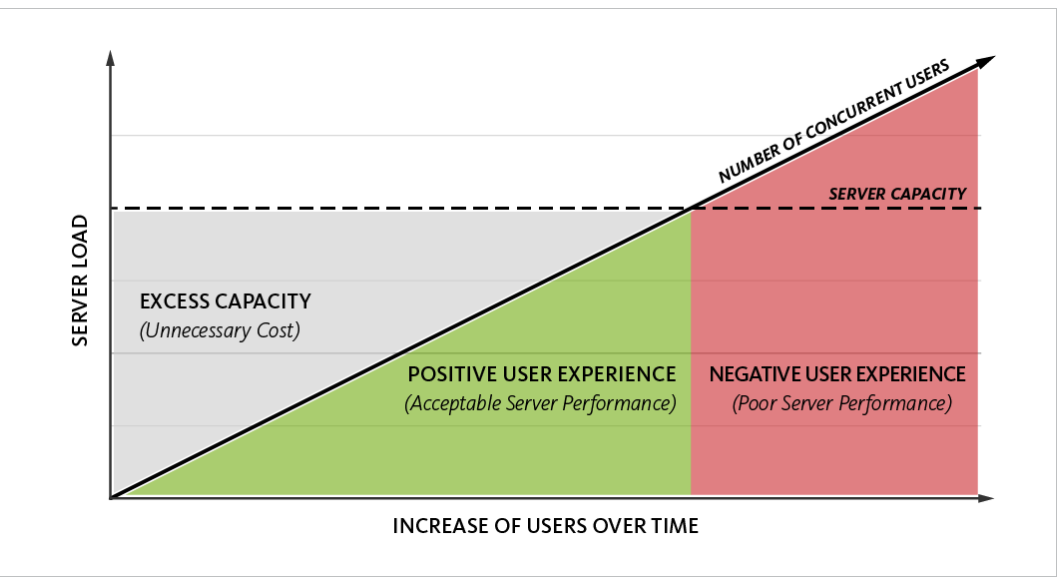
Về phía phần cứng, dù những bộ nhớ như RAM vẫn còn đắt đỏ so với Disk nhưng chúng ngày càng rẻ hơn theo thời gian, việc có ưu thế tốc độ vẫn mang lại lợi ích mà chúng ta cần tận dụng. Ngược lại, Disk mang tới sự ổn định cũng như dễ dàng scale với chi phí thấp. Vấn đề với với cache layer như chúng ta đã phân tích ở trên nằm ở việc chúng độc lập với On-disk database. Vậy để cả Memory và On-disk database phát huy hết khả năng, ta nên tích hợp chúng với nhau. Đó là lý do để các Hybrid DBMS ra đời như Aerospike, RocksDB, Apache Ignite, eXtremeDB, Altibase, Hazelcast, … Trong thực tế, ngày càng nhiều các storage (on-disk lẫn in-memory) dần đi theo con đường này.
Nhưng liệu chúng ta có cần đến RDBMS nữa không? — Tất nhiên là có, RDBMS vẫn có những ưu điểm của riêng chúng mà NoSQL không có được. Chúng ta sẽ dành cho nó một vai trò khác trong kiến trúc mới, nơi phát huy được sở trường của mình (strong consistency, transactional…).
On Like!-way
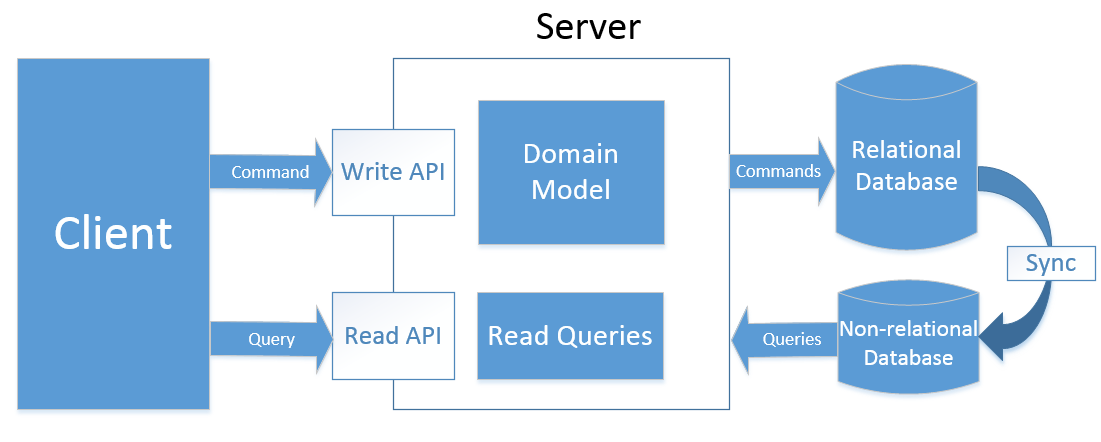
Việc phân tách quá trình đọc/ghi thành 2 hệ thống độc lập là cần thiết để loại bỏ hoàn cache layer khỏi kiến trúc của chúng tôi (có lẽ bạn đã nghe về CQRS, nhưng ta sẽ bàn đến nó sâu hơn trong một bài viết khác). Sao lại vậy?
Các cơ sở dữ liệu NoSQL thường có nhược điểm như thiếu Schema chặt chẽ, cũng như chỉ áp dụng Eventual Consistency. Đối với các hệ thống có nghiệp vụ đòi hỏi tính đúng đắn cao, dùng NoSQL như một DB chính duy nhất có thể sẽ dẫn tới những sai lệch về mặt dữ liệu không đáng có. Lúc này RDBMS phát huy vai trò của mình khi là nơi dành riêng cho việc ghi. Cùng với đó, việc chỉ sử dụng NoSQL như một Readonly-DB thì ta đã loại bỏ những nhược điểm kể trên. Hơn nữa lại tận dụng triệt để ưu điểm của chúng đó là Horizontal Scalability và High Availability.
Các NoSQL có nhiều cách để tổ chức dữ liệu để phục vụ những nhu cầu khác nhau, chia ra thành các loại chính như biểu đồ dưới đây.
Với mỗi bài toán cụ thể, chúng tôi sử dụng từng NoSQL phù hợp với nó. Ví dụ như nhu cầu load frontend ở tốc độ cao, Aerospike (In-memory Key-Value DB) được thiết kế cho bộ nhớ dạng Flash đang được sử dụng vì độ trễ thấp đáng ngạc nhiên. Còn với nhu cầu High performance(writes) và High Scalability để làm một OLAP database thì Cassandra đang là lựa chọn tốt với các đặc tính như linearly scalable, column-oriented, fault tolerance, …
Kết luận
Chúng tôi cho rằng, RDBMS đi kèm Cache Layer không còn có thể xử lý hiệu quả các thách thức về tốc độ và sự phức tạp của hệ thống ngày nay. Việc chia tách kiến trúc đọc/ghi sẽ đem lại lợi ích thay thế cho Caching cũng như tận dụng ưu điểm của các thành phần đơn lẻ. Thêm vào đó là khả năng mở rộng của hệ thống cũng tăng hơn nhiều. Hy vọng bài viết này đã đưa ra được những điểm mạnh của In-memory DB + kiến trúc mới, giúp bạn có những cân nhắc hoàn thiện hệ thống tốt hơn.
Refs:
