Applying Airflow to build a simple ETL workflow
Introduction
In my last blog, I have given a quick guide on how to use Airflow in the most basic way. In today’s blog, I will be guiding you through the process of creating a simple ETL workflow from local database to data warehouse, using Airflow as the backend.
E-T-L & Airflow
Extract – Transform – Load is a three-step process commonly seen in the context of data-centric projects. It is the process of aggregating data from various source to a centralized data warehouse so that the data can be analyzed later on. It is a crucial first part of the two parts featured in our LiMDa project (the second one being data refinement). Airflow is said to be built with ETL in mind, so it is a good candidate for ETL workflows of any scale.
Scenario
Given a database FL_Business with several tables that is used for the business of the client company. For simplicity, the scenario here is limited to operations on one table only: The client wishes to synchronize data from selected columns from the table orders, first to Google Cloud Storage bucket then to BigQuery. The client wants the system to run on Airflow 1.10.x. In this blog, firstly we deal with the full load problem, that is, to extract and load the whole table content to the data warehouse. The incremental load problem (daily synchronization) will be discussed in later blogs. Here’s the screenshot of the order table.
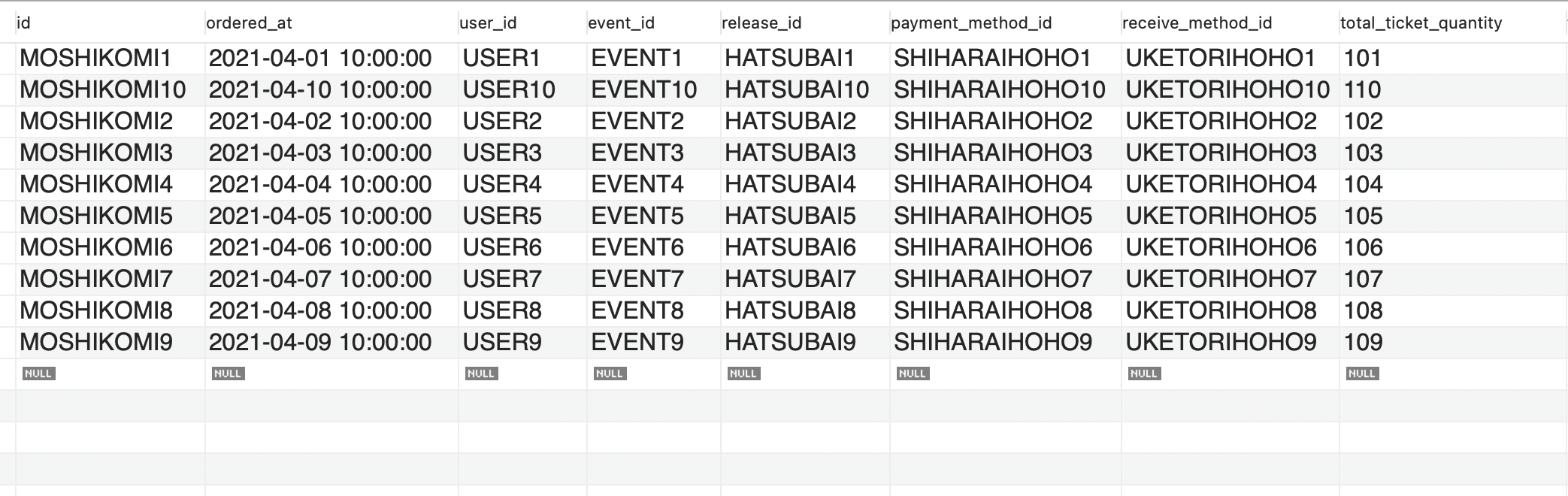
The columns to be synchronized are:
- id
- ordered_at
- user_id
- event_id
- release_id
- payment_method_id
- receive_method_id
- total_ticket_quantity
- temp_lot_status
- lot_status
- fixed_total_price
- payment_status
- payment_expire_at
- payed_at
- cancel_flg
- canceled_at
- created_at
- updated_at
Finding suitable operators
From the client’s demand, we can synchronize each meaningful table following a common series of tasks:
- Query meaningful columns from the table.
- Push the query result as a file to the pre-defined Google Cloud Storage bucket.
- Load the file as data to BigQuery.
In Airflow, to build a workflow, suitable operators must be used and upstream/downstream relationships must be specified. After researching, our team decided to compact the workflow to 2 steps:
- MySQL to Google Cloud Storage (Query + push result to GCS) (Extract/Transform)
- Google Cloud Storage to BigQuery (Load GCS to BQ) (Load)
The updated workflow allowed the team to use predefined operators from the package airflow.contrib.operators, removing the need to test operators as those operators are official and have been well-tested before release. Now the workflow graph should look like following:
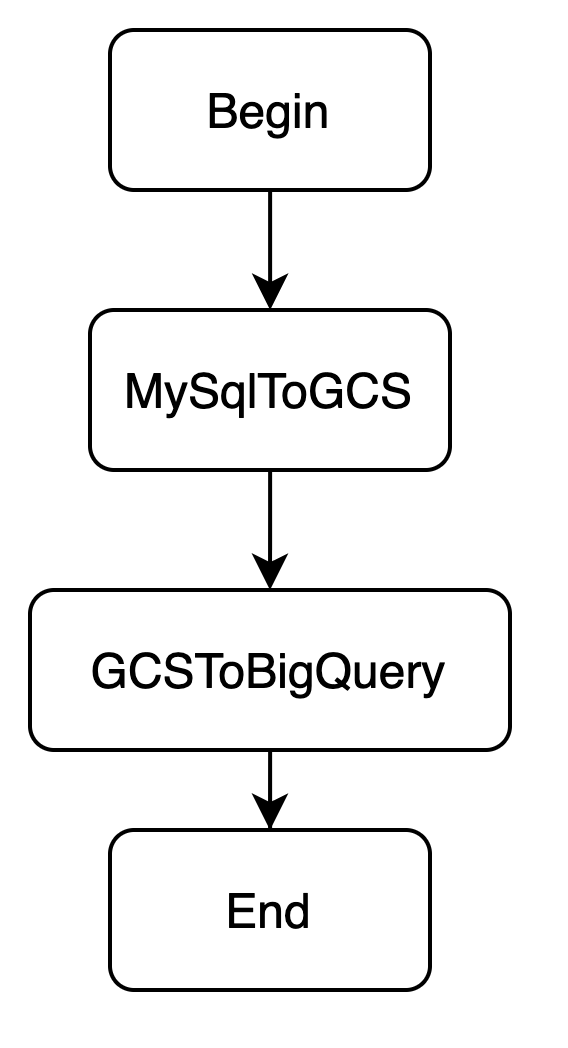
Let’s code the DAG!
Now that we have the idea of how to solve this problem, let us get on to coding! First thing to do is to add Airflow connections for database, Google Cloud Platform and BigQuery:

Create a DAG file named etl_single_dag.py at the dag_folder as seen in my previous blog: Apache Airflow & DAGs by examples.
Here’s the SQL query:
query = """SELECT `id`, `ordered_at`, `user_id`,
`event_id`, `release_id`, `payment_method_id`,
`receive_method_id`, `total_ticket_quantity`, `temp_lot_status`,
`lot_status`, `fixed_total_price`, `payment_status`,
`payment_expire_at`, `payed_at`, `cancel_flg`, `canceled_at`,
`created_at`, `updated_at`
FROM `orders`;"""Define the dag object for the file. Kindly set the start_date to be the current date and the schedule_interval to None so that the DAG does not reschedule itself:
import datetime
from airflow.models import dag
default_args = {
"start_date": datetime.datetime(2021, 4, 13)
}
with dag.DAG(
dag_id="fl_orders_db_sync",
schedule_interval=None,
default_args=default_args
) as _dag:Let’s create the tasks inside the with dag statement. First is MySQLToGCS:
from airflow.contrib.operators.mysql_to_gcs import MySqlToGoogleCloudStorageOperator
from airflow.models import Variable
bucket = "limda_dev"
file_name = "fl/orders.csv"
export_format = "csv"
fl_order_mysql_to_gcs = MySqlToGoogleCloudStorageOperator(
task_id="fl_order_mysql_to_gcs",
mysql_conn_id="fl_business_db",
sql=query,
bucket=bucket,
filename=file_name,
export_format=export_format
)Then to GCSToBigQuery:
from airflow.contrib.operators.gcs_to_bq import GoogleCloudStorageToBigQueryOperator
destination_project_dataset_table = "livand.limda_dev.fl_orders"
# define the BigQuery schema
schema_fields = [
{"name": "id", "type": "STRING", "mode": "REQUIRED"},
{"name": "ordered_at", "type": "TIMESTAMP", "mode": "NULLABLE"},
{"name": "user_id", "type": "STRING", "mode": "REQUIRED"},
{"name": "event_id", "type": "STRING", "mode": "REQUIRED"},
{"name": "release_id", "type": "STRING", "mode": "REQUIRED"},
{"name": "payment_method_id", "type": "STRING", "mode": "REQUIRED"},
{"name": "receive_method_id", "type": "STRING", "mode": "REQUIRED"},
{"name": "total_ticket_quantity", "type": "INT64", "mode": "REQUIRED"},
{"name": "temp_lot_status", "type": "STRING", "mode": "REQUIRED"},
{"name": "lot_status", "type": "STRING", "mode": "REQUIRED"},
{"name": "fixed_total_price", "type": "INT64", "mode": "REQUIRED"},
{"name": "payment_status", "type": "STRING", "mode": "REQUIRED"},
{"name": "payment_expire_at", "type": "TIMESTAMP", "mode": "NULLABLE"},
{"name": "payed_at", "type": "TIMESTAMP", "mode": "NULLABLE"},
{"name": "cancel_flg", "type": "STRING", "mode": "REQUIRED"},
{"name": "canceled_at", "type": "TIMESTAMP", "mode": "NULLABLE"},
{"name": "created_at", "type": "TIMESTAMP", "mode": "NULLABLE"},
{"name": "updated_at", "type": "TIMESTAMP", "mode": "NULLABLE"}
]
fl_order_gcs_to_bq = GoogleCloudStorageToBigQueryOperator(
task_id="fl_order_gcs_to_bq",
bucket=bucket,
source_objects=[file_name],
source_format=export_format,
skip_leading_rows=1, # csv heading row
destination_project_dataset_table=destination_project_dataset_table,
schema_fields=schema_fields,
create_disposition="CREATE_IF_NEEDED",
write_disposition="WRITE_TRUNCATE",
google_cloud_storage_conn_id="fl_gcp",
bigquery_conn_id="fl_gcp"
)Don’t forget to create a begin and an end task:
from airflow.operators.dummy_operator import DummyOperator
begin = DummyOperator(task_id="begin")
end = DummyOperator(task_id="end")Finally, remember to set the relationship of the tasks:
begin >> fl_order_mysql_to_gcs >> fl_order_gcs_to_bq >> endNow we can run the DAG in Airflow. Open the Airflow Web UI and fire up the Airflow Scheduler, then enable the DAG. You will have to manually trigger the DAG, however that shall not take too much effort and you should see the tasks run and succeed shortly.

Afterwards, the data is successfully synchronized to the data warehouse (BigQuery):
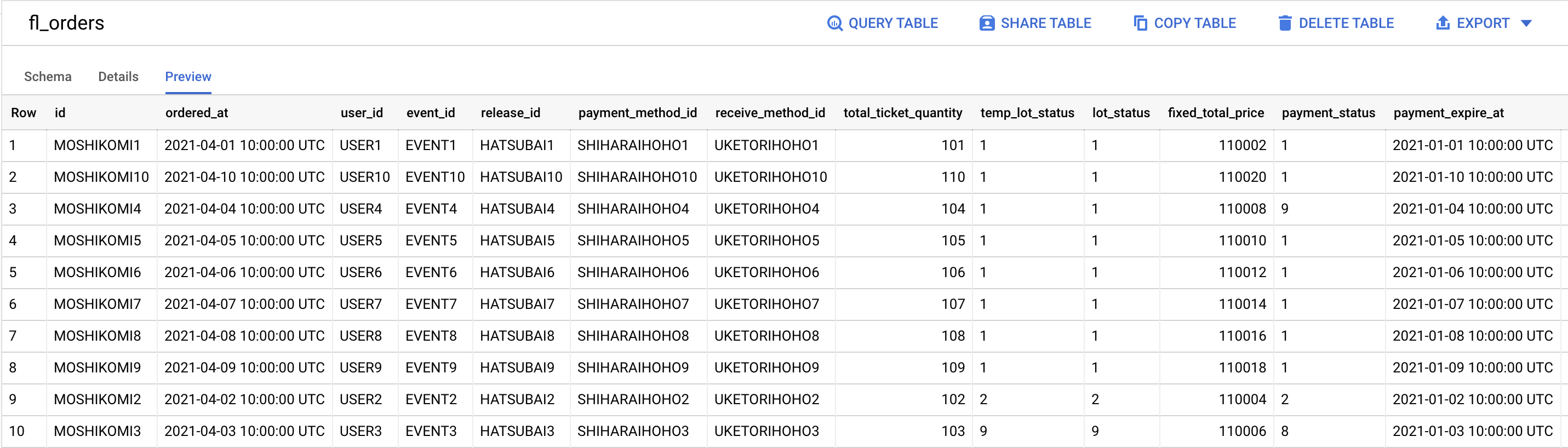
Conclusion
In today’s blog, I have guided you through the process of setting up a simple DAG in an single-table ETL non-scheduled workflow. See you in later blogs about Airflow!
References
https://towardsdatascience.com/airflow-schedule-interval-101-bbdda31cc463


