[Algorithm] Các thuật toán tìm kiếm trong AI
Xin chào mọi người! Chắc hẳn ai trong giới lập trình chúng ta cũng đều gặp các bài toán liên quan đến Tìm kiếm (search, query, sort,…), vậy trong lĩnh vực trí tuệ nhân tạo người ta sử dụng những khái niệm, những thuật toán nào? Cùng mình đi tìm hiểu thêm nhé. Có visualization để mọi người hình dung =)).
I. Phân loại
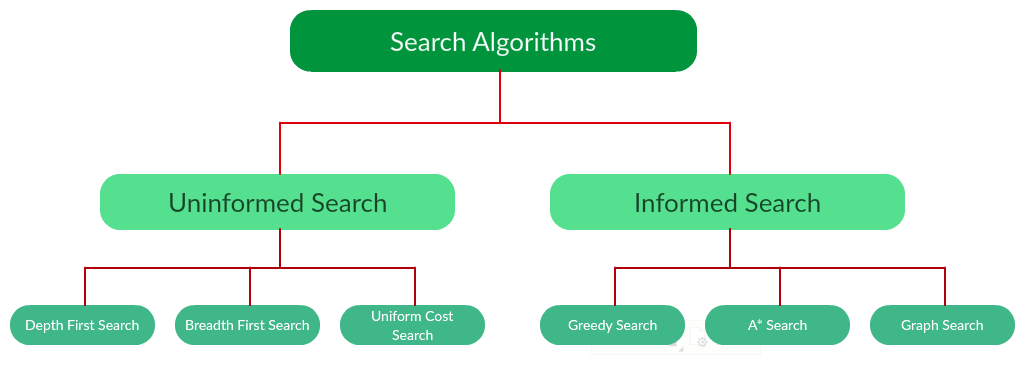
Có nhiều cách phân loại các thuật toán tìm kiếm, trong đó phổ biến hơn cả đó là chia làm 2 loại: Uninformed Search (Blind Search ?) và Informed Search (Heuristic Search ?).
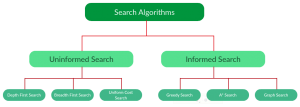
 II. Uninformed Search (Blind Search / Tìm kiếm mù)
II. Uninformed Search (Blind Search / Tìm kiếm mù)
“Kỳ thực trên mặt đất vốn làm gì có đường. Người ta đi mãi thì thành đường thôi.” – Lỗ Tấn
Uninformed Search cũng vậy! Ta chỉ biết đích đến, còn nó ở đâu, đi như nào, bao giờ đến ta đều không biết ?, chỉ được cái là đi mãi cũng đến đích thôi. Phương pháp tìm kiếm mù có khả năng thám hiểm không gian trang thái để tìm ra trạng thái đích, tuy nhiên nó rất là không hiệu quả trong hầu hết bài toán, chậm và may rủi!
Các chiến lược tìm kiếm phổ biến:
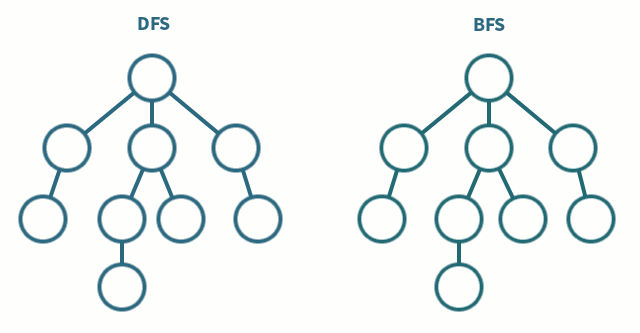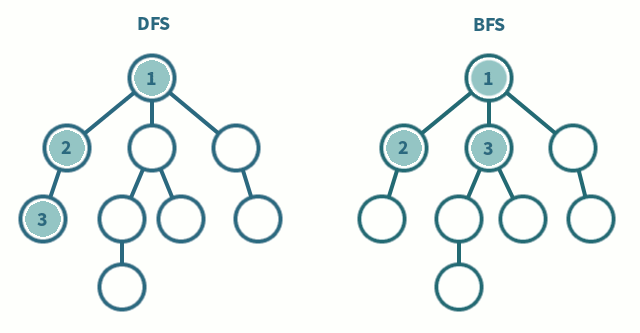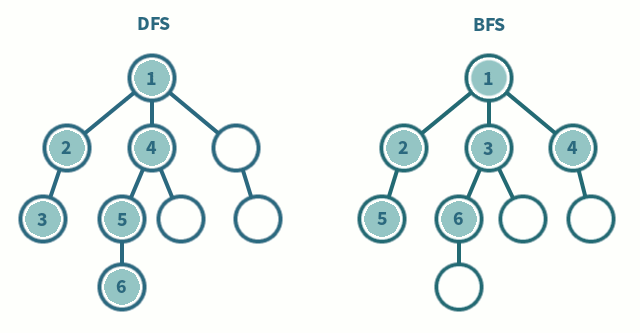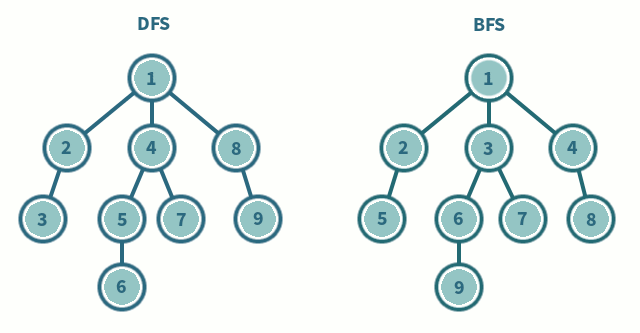
- DFS (Depth First Search): Tìm kiếm theo chiều sâu
- BFS (Breath First Search): Tìm kiếm theo chiều rộng
- UCS (Uniform Cost Search): Áp dụng thuật toán Dijkstra
Nhắc đến DFS, BFS, hay Dijkstra thì chắc hẳn chúng ta ai cũng quá quen thuộc rồi, mình xin phép không nhắc lại, UCS sẽ có so sánh visualization ở phần sau.
III. Informed Search (Heuristic Search / Tìm kiếm dựa kinh nghiệm)
Đây sẽ là phần chính của blog ngày hôm nay.
Vài khái niệm cơ bản:
- Heuristic: là các kỹ thuật dựa trên kinh nghiệm để giải quyết vấn đề, nhằm đưa ra một giải pháp mà không được đảm bảo là tối ưu (theo Wiki)
- Heuristic function: Hàm đánh giá dựa trên kinh nghiệm, dựa vào đó để xếp hạng thứ tự tìm kiếm, cách chọn hàm đánh giá quyết định nhiều đến kết quả tìm kiếm.
Ta đi vào 2 thuật toán sử dụng hàm đánh giá để hiểu hơn rõ hơn nhé: Greedy Best-First-Search và A*
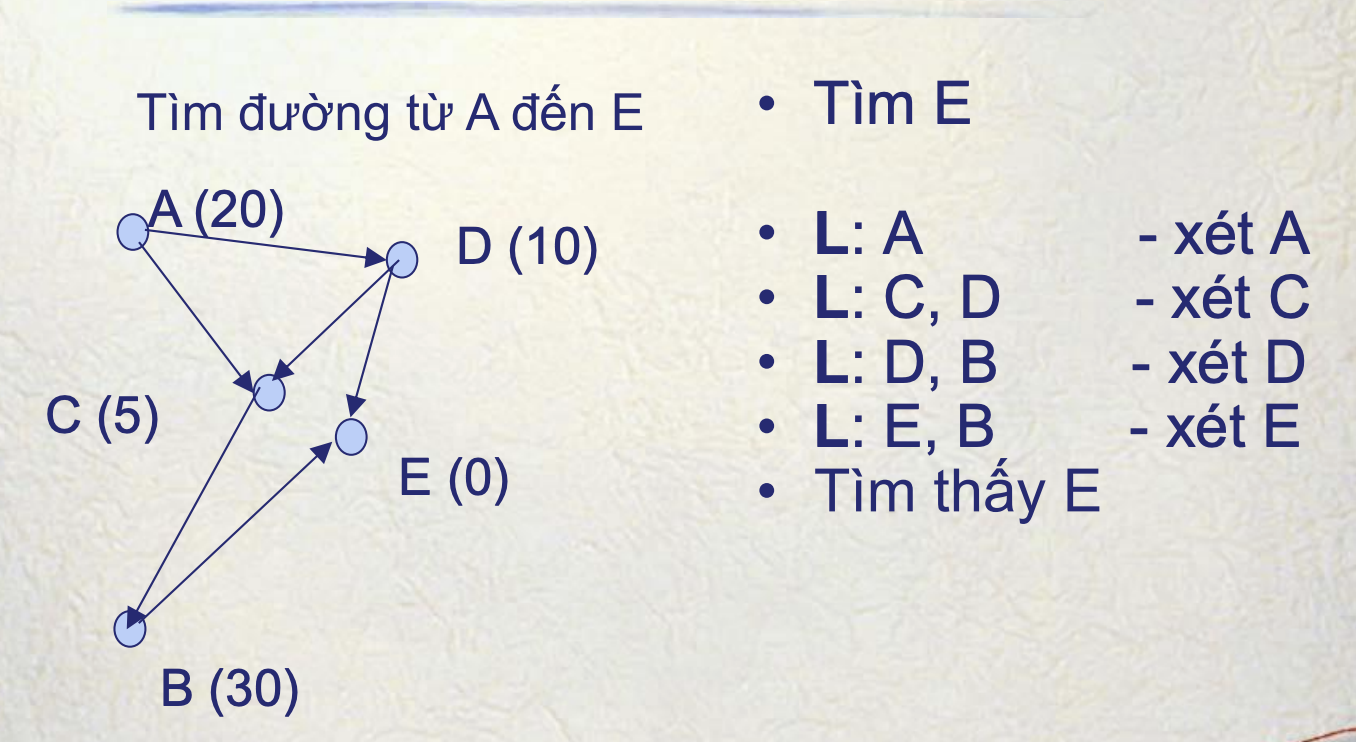 Greedy Best-First-Search:
Greedy Best-First-Search:
Chọn node kế tiếp có được đánh giá là tốt nhất
Giá trị của hàm đánh giá tại 1 điểm được ghi bên cạnh: A(20), C(5)
Nghĩa là nó đánh giá dựa vào 1 tính chất nào đó mà AE = 20, CE = 5, EE = 0 (tất nhiên)
G-BFS: A -> C -> D -> E
Một ví dụ khác:
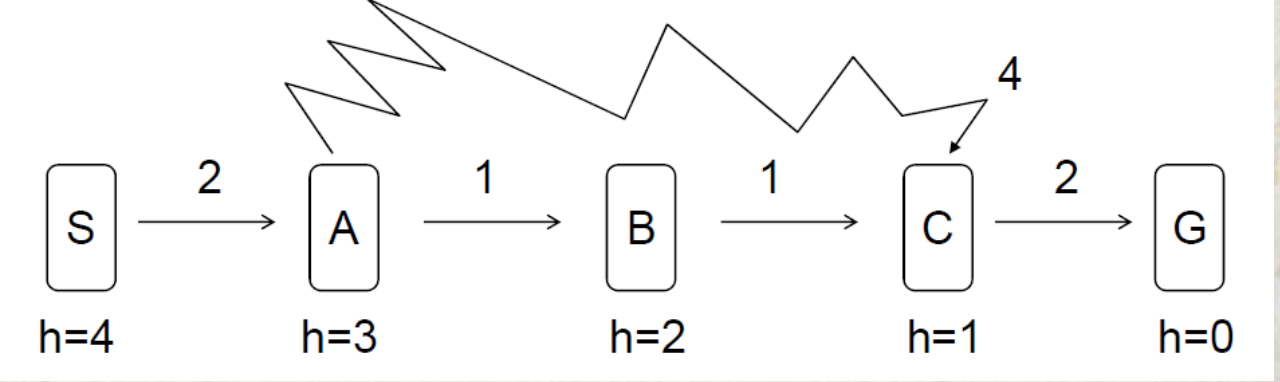 G-BFS hiệu quả nhưng thật sự chưa chắc đã tối ưu, đôi khi hơi ngớ ngẩn ?
G-BFS hiệu quả nhưng thật sự chưa chắc đã tối ưu, đôi khi hơi ngớ ngẩn ?
Hình bên, g(n) là chi phí thực tế, h(n) là ước lượng theo hàm đánh giá.
Nếu chỉ dựa theo đánh giá h(n): G-BFS: S->A->C->G (cost 8)
Trong khi đi thẳng không nghĩ ngợi: S->A->B->C->G (cost 6)
Để tránh điều đó, hàm đánh giá cần thoả mãn 2 tính chất quan trọng: admissible và consistent (mời mọi người đọc thêm).
A* Algorithm: UCS + Greedy Best-First-Search
Kết hợp tính hiệu quả(nhanh) của G-BFS, tính tối ưu(luôn tìm ra lời giải đúng) của UCS

Hàm đánh giá: f(n)=g(n) + h(n)
g(n) – Chi phí từ node hiện tại tới node n
h(n) – ước lượng khoảng cách từ node n -> đích
UCS chỉ dùng g(n) nên chậm, G-BFS chỉ dựa h(n) nên không tối ưu
f(n) – tối ưu + hiệu quả!
Visualize để mọi người dễ hình dung:
h(n) ở đây là Euclidean distance (Đường thẳng luôn là ngắn nhất đúng không nào ?)
Dưới cùng là đường đi với h(n) = 5 * Euclidean distance .


Có nhiều cách chọn hàm h(n), tuỳ cách chọn mà có thể tối ưu hoặc không.
Kết luận: Heuristic không phải lúc nào cũng tìm ra giải pháp tối ưu nhất, nhưng nó có thể tìm ra một trong những giải phát tốt nhất trong thời gian ngắn với không gian bộ nhớ nhỏ.
A* là một thuật toán rất thông minh, được Google Maps sử dụng trong bài toán tìm đường đi ngắn nhất thời gian thực!
Cảm ơn mọi người đã theo dõi!
Tham khảo: UET – AI courses, How does the algorithm of Google Maps work?

Khi AI Khiến Hiệu Suất Developer Giảm: Những Kịch Bản Thực Tế Nên Tránh

Giới thiệu về Google Colab
