Flinters đang xử lý data như thế nào? (Phần 1)
Septeni, khách hàng lớn nhất của Flinters Việt Nam là một công ty kinh doanh trong lĩnh vực quảng cáo trực tuyến, là đối tác, đại lý quảng cáo của hàng loạt các media lớn như Facebook, Google, Twitter, … Để có những quyết định có lợi nhất cho khách hàng, bộ phận kinh doanh của Septeni cần một lượng lớn dữ liệu tổng hợp trong một thời gian dài và được cung cấp theo thời gian thực.
Để đáp ứng nhu cầu đó, Flinters Việt Nam đã áp dụng mô hình ELT vào để xử lý và phân tích dữ liệu. ELT là viết tắt của 3 giai đoạn (Extract, Loading, Transform) đại diện cho một chu trình xử lý dữ liệu (Data Pipeline). Đầu vào của chu trình là các dữ liệu thô được thu thập từ nhiều nguồn khác nhau và đầu ra là dữ liệu có thể được mô hình hóa dưới dạng biểu đồ thời gian thực hoặc dữ liệu phục vụ cho Machine learning hoặc AI. Ngoài ELT, ETL cũng là một chu trình thông dụng. Sự khác nhau của hai chu trình này nằm ở việc bước Loading trước hay sau. Trên thực tế, mô hình ELT tỏ ra phù hợp với nhu cầu xử lý dữ liệu của chúng tôi hơn. Vì vậy, trong bài viết này, mình chỉ tập trung trình bày về mô hình ELT. Cụ thể, ba giai đoạn của ELT bao gồm:
Extract: Thu thập dữ liệu
Loading: Tải dữ liệu đã lấy được vào kho dữ liệu (Data Warehouse – DWH)
Transform: Quá trình sửa đổi cấu trúc dữ liệu. Đó có thể là một số hoạt động cơ bản như lọc, loại bỏ các trường trùng lặp, liên kết dữ liệu từ nhiều nguồn, xác thực dữ liệu, tổng hợp dữ liệu, …
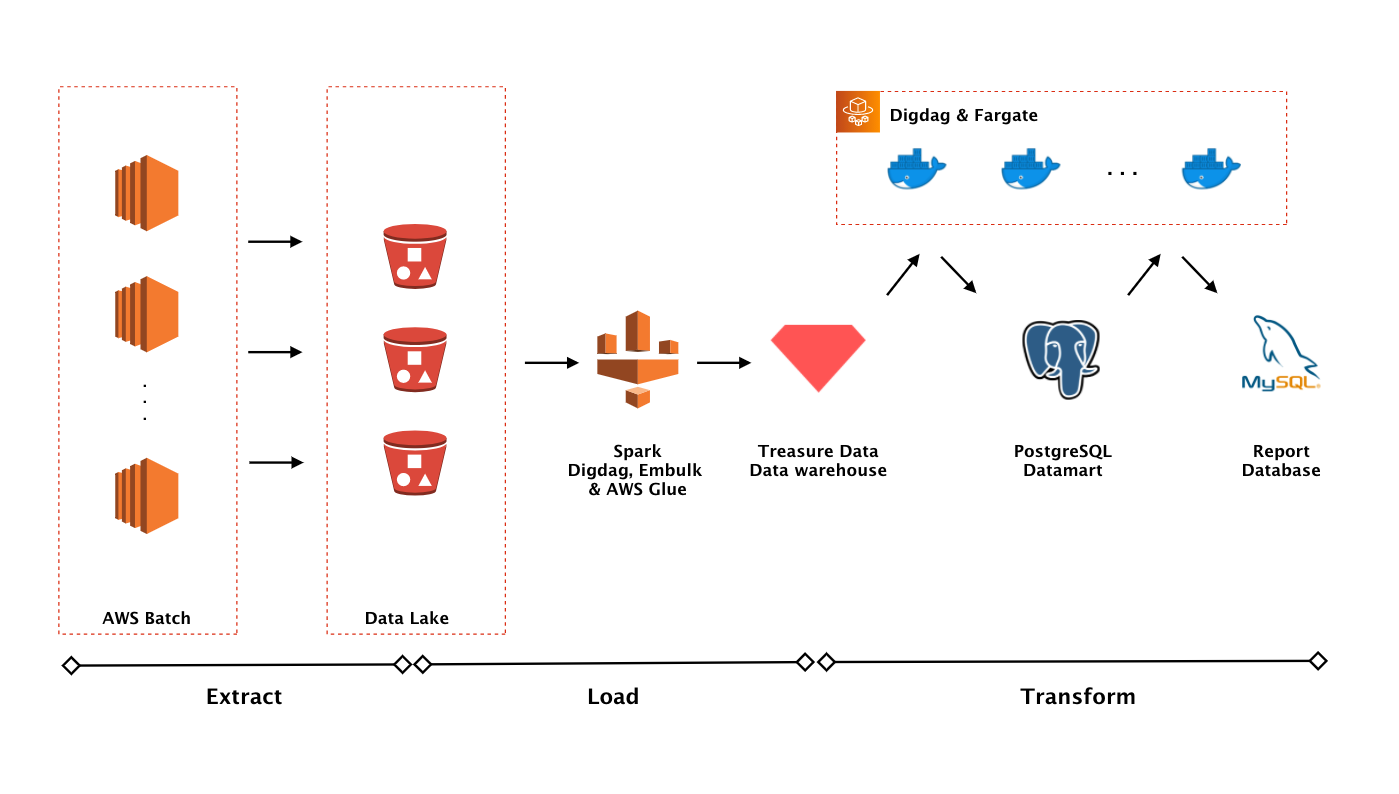
Extract, đây là giai đoạn cần phải xử lý khối dữ liệu vô cùng lớn. Trung bình hàng tháng, giai đoạn này luân chuyển một lượng dữ liệu từ 20-25TB. Sau khi cân nhắc, đội phát triển đã chọn các công nghệ như Scala, Akka streams và AWS Batch. Lý do nào đã khiến chúng tôi chọn những công nghệ này?
Đầu tiên, Scala là một ngôn ngữ rất phù hợp cho việc xử lý dữ liệu. Sử dụng JVM, Scala có thể xử lý một khối dữ liệu lớn một cách dễ dàng. Hệ thống viết bằng Scala có thể hoạt động bền bỉ. Là một ngôn ngữ TypeSafe, Scala có khả năng tối ưu tài nguyên phần cứng rất tốt. Cú pháp ngắn gọn, hỗ trợ nhiều cho functional programming là một ưu điểm nữa của Scala.
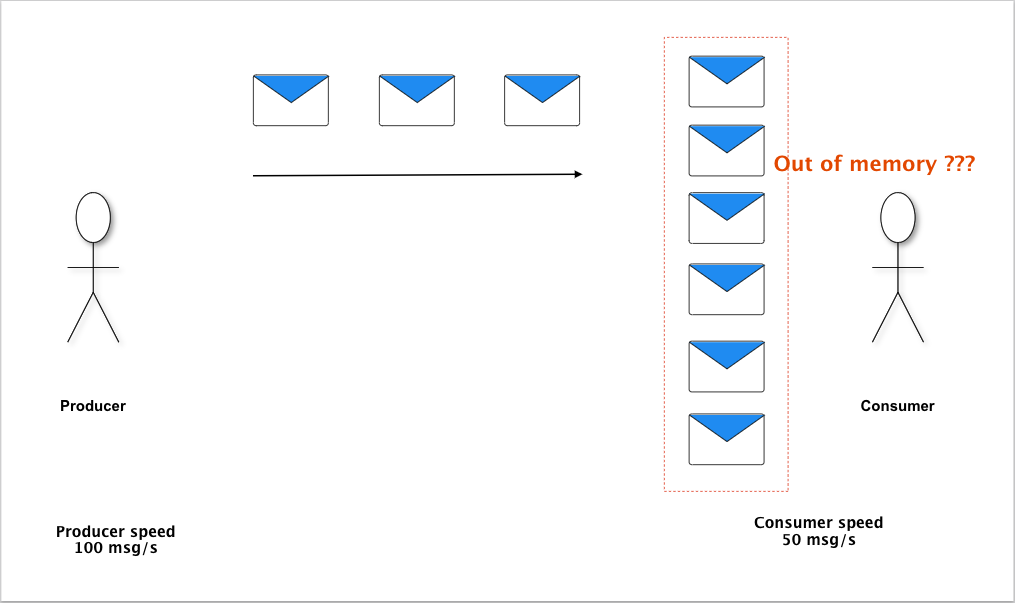
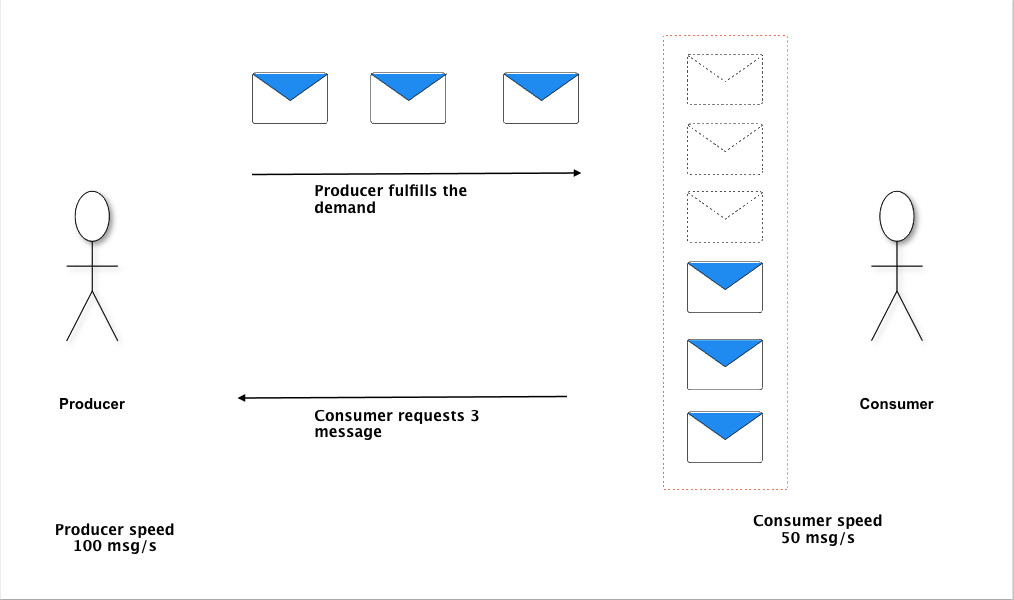
Cùng với Scala, framework Akka Streams được chọn vì những ưu điểm của nó trong quá trình xử lý một lượng lớn dữ liệu. Là một “rich stream api”, Akka Streams đưa chúng ta tới khái niệm “Reactive Stream”, một tiêu chuẩn để xử lý bất đồng bộ (asynchronous) và non-blocking. Việc xử lý các luồng dữ liệu – đặc biệt là các dữ liệu có khối lượng không xác định được trước, đòi hỏi một sự cẩn trọng nhất định trong việc xây dựng hệ thống bất đồng bộ. Bất đồng bộ là một cách cho phép hệ thống tận dụng khả năng tính toán song song của một bộ vi xử lý (CPU) đa lõi. Tuy nhiên, một hệ thống không được thiết kế tốt có thể dẫn tới hiện tượng nghẽn cổ chai (bottleneck), làm sụp đổ ý tưởng ban đầu về tận dụng tối đa tài nguyên. Akka Streams với cơ chế back-pressure là một giải pháp xử lý vấn đề trên. Back-pressure thay đổi cơ chế giao tiếp giữa thành phần cung cấp (producer) và thành phần xử lý (consumer). Consumer sẽ thông báo số lượng mình mong muốn cho Producer, và Producer sẽ đáp ứng con số đấy. Con số này sẽ phụ thuộc hoàn toàn vào Consumer tùy thời điểm.
Cuối cùng, mã nguồn Scala được chạy trên hạ tầng cung cấp bởi AWS Batch. Với AWS Batch, chúng tôi có thể tận dụng được một trong những đặc tính nổi bật nhất của điện toán đám mây, tính co giãn (elastic). Không giống như dịch vụ web, yêu cầu tính liên tục, dịch vụ xử lý hàng loạt (batch) yêu cầu một lượng tài nguyên lớn trong một khoảng thời gian nhất định. Khi cần lấy dữ liệu, một server sẽ được AWS Batch bật lên và khi việc lấy dữ liệu hoàn thành, server đó sẽ tự động được tắt đi, chi phí chỉ mất khi server chạy giúp tiết kiệm hơn nhiều so với một server chạy 24/7.
Như đã đề cập ở trên, lượng dữ liệu được xử lý là rất lớn, do vậy việc tối ưu tài nguyên đóng vai trò hết sức quan trọng. Đội phát triển đã quyết định thay vì lưu dữ liệu tạm thời trong memory sẽ lưu tạm thời lên disk, sau đó mới tải lên S3 – dịch vụ lưu trữ rất phổ biến hiện này trên AWS. Lưu trữ tạm thời dữ liệu trên disk, sau đó mới đẩy lên S3 giúp hệ thống tốn ít memory hơn, khi mà giá thành của disk rẻ hơn nhiều so với memory, dù tốc độ có chậm hơn đôi chút. Dữ liệu được đẩy lên S3 thường là dữ liệu thô, chưa qua chuyển đổi. Việc này nhằm mục đích đảm bảo tính nguyên vẹn nhất cho dữ liệu. Nếu quá trình biến đổi sau này có gặp lỗi, chúng ta vẫn sẽ có một dữ liệu nguyên thủy nhất.
Tuy vậy, không có công nghệ nào là “chén thánh” để giải quyết mọi vẫn đề. Sau một thời gian triển khai, một số khuyết điểm đã được chúng tôi ghi nhận. Đầu tiên, giao diện của AWS Batch khi có một lượng lớn các job không trực quan, khó theo dõi trạng thái các job. Điều này dẫn tới hệ quả đội phát triển phải xây dựng riêng một giao diện web để theo dõi và tổng hợp kết quả chạy. AWS Batch có công nghệ lõi là EC2 – dịch vụ cho thuê server từ Amazon và Auto Scaling Group – tính tăng tự động thêm server khi cần và tắt đi khi công việc hoàn thành. Khi một job được bắt đầu, luôn có độ trễ lên tới vài phút để server EC2 có thể được cấp phát và khởi động. Điều này gây ra độ trễ nhất định cho các job và khó khăn trong việc xây dựng các job chạy tuần tự. Auto Scaling Group tự động chọn lựa cấu hình server không tối ưu, đôi khi chọn cấu hình vượt lên nhiều so với yêu cầu. Việc API của các media thay đổi phiên bản thường xuyên cũng là một thách thức trong việc thiết kế phần mềm. Dù có nhược điểm, nhưng những công nghệ kể trên đã hoàn thành tốt các tiêu chí đặt ra ban đầu và đáp ứng được nhu cầu sử dụng trong hiện tại.
Trên đây, mình đã trình bày giai đoạn đầu tiên trong một chu trình ELT. Phần sau chúng ta sẽ tiếp tục với hai giai đoạn còn lại cũng như tổng quan ưu nhược điểm trong quá trình vận hành.
Tài liệu tham khảo:
https://anuprawka.medium.com/akka-streams-our-journey-for-fast-data-processing-30cff2ed941c
https://docs.aws.amazon.com/batch/latest/userguide/what-is-batch.html
https://cloud.google.com/solutions/migration/dw2bq/dw-bq-data-pipelines#elt

Có thể xảy ra Incompatible-parameters ở RDS mặc dù không có vấn đề gì về parameters

Giới thiệu về AWS S3
