Tìm hiểu về “đối tượng” bằng con đường ChatGPT!
Hôm trước tôi đã bị thu hút bởi một hệ thống xử lý dữ liệu thời gian thực, trong đó tôi thấy cần phải học thêm về Kafka, đây là một công nghệ mạnh mẽ để xử lý dữ liệu lớn thời gian thực và đang được xử lý rộng rãi. Tôi nói với bạn của mình “Làm sao để tôi master về kafka nhỉ?” Anh bạn của tôi cũng thể hiện sự hào hứng rực lửa khi lập tức đưa ra cho tôi một lộ trình khá là chi tiết, điều này giống như tiếp thêm cho tôi 1000% sức mạnh vậy.
Để học Kafka một cách bài bản và trở thành chuyên gia, bạn có thể đi theo lộ trình sau:
1. Hiểu Cơ Bản Về Kafka
- Kafka là gì?: Hệ thống message queue phân tán, chịu tải cao, dùng để xử lý streaming data.
- Kiến trúc Kafka: Broker, Producer, Consumer, Topic, Partition, Offset, Zookeeper.
- Cách hoạt động:
- Producer gửi message đến Kafka.
- Kafka lưu trữ message theo topic và partition.
- Consumer đọc message theo offset.
- Tài liệu tham khảo:
- Kafka Official Docs
- Sách “Kafka: The Definitive Guide” (Gwen Shapira, Todd Palino)
2. Cài Đặt và Thực Hành Kafka
- Cài đặt Kafka trên Local hoặc Docker.
- Chạy Kafka với các lệnh cơ bản (
kafka-topics.sh,kafka-console-producer.sh,kafka-console-consumer.sh). - Viết producer/consumer đơn giản bằng Python, Java, hoặc Node.js.
- Tài liệu tham khảo:
3. Kafka với Real-world Use Cases
- Xây dựng hệ thống event-driven với Kafka.
- Kafka Connect: Kết nối Kafka với databases (MySQL, PostgreSQL, MongoDB).
- Kafka Streams: Xử lý dữ liệu real-time.
- Schema Registry & Avro: Quản lý cấu trúc dữ liệu.
- Tài liệu tham khảo:
4. Kafka Trong Môi Trường Production
- Tuning Kafka Performance: Tối ưu partition, replication, retention.
- Kafka Security: SSL, ACL, SASL.
- Monitoring Kafka: Dùng Prometheus, Grafana.
- Thực hành:
- Deploy Kafka trên Kubernetes (EKS/GKE).
- Xây dựng Kafka Cluster HA với Zookeeper.
5. Master Kafka với Dự Án Thực Tế
- Dự án 1: Hệ thống log tracking với Kafka + Elasticsearch.
- Dự án 2: Hệ thống real-time analytics với Kafka + Flink.
- Dự án 3: Event-driven microservices với Kafka + Spring Boot.
Quá tuyệt vời, tôi sẽ đi cùng bạn, đầu tiên, hãy cùng tìm hiểu xem rốt cuộc Kafka “là gì”?
“Apache Kafka is a distributed streaming platform designed for building real-time data pipelines and streaming applications” vậy kafka là một platform nhằm xử lý dữ liệu streaming, mâng lậi hiệu suất cao, độ trễ thấp, có khả năng tránh lỗi và mở rộng. Kiến trúc của kafka như thế nào mà có thể đảm bảo điều đó.

- Kafka Cluster: Kafka cluster là một nhóm broker Kafka hoạt động cùng nhau để lưu trữ, xử lý, và truyền tải dữ liệu. Một cluster phân tán dữ liệu vào nhiều broker Kafka giúp cho nó có khả năng mở rộng, chịu lỗi và đảm bảo hiệu suất cao.
- Một kafka cluster có thể được xây dựng trên nhiều môi trường khác nhau, tùy theo yêu cầu về hiệu suất, tính sẵn sàng và quản lý hệ thống. Dưới đây là một số môi trường phổ biến để triển khai Kafka, tôi sẽ mô tả ngắn gọn bằng bảng sau:
| Môi trường | Khi nào nên dùng? | Cách triển khai | Nhược điểm |
|---|---|---|---|
| Bare Metal / On-Premise | – Khi có server vật lý hoặc máy ảo riêng. – Khi muốn tối ưu hiệu suất mà không phụ thuộc vào cloud. – Khi dữ liệu yêu cầu quản lý nội bộ. | – Cài đặt Kafka và Zookeeper trên nhiều server vật lý. – Sử dụng load balancer để quản lý traffic. – Dùng Ansible, Terraform để tự động hóa triển khai. | Cần quản lý tài nguyên, cấu hình, backup và xử lý lỗi thủ công. |
| Docker / Docker Compose | – Khi muốn chạy Kafka nhanh chóng mà không cần cài đặt nhiều. – Khi muốn mô phỏng môi trường cluster trên local. – Khi phát triển ứng dụng microservices. | – Dùng Docker Compose để tạo Kafka Cluster với nhiều broker. – Có thể dùng Bitnami Kafka hoặc Confluent Kafka để chạy nhanh. | Chỉ phù hợp cho môi trường phát triển, không nên dùng trên production. |
| Kubernetes (K8s) | – Khi đang chạy ứng dụng microservices trên Kubernetes. – Khi muốn tự động scale Kafka Cluster khi tải tăng cao. – Khi muốn Kafka có tính chịu lỗi. | – Dùng Strimzi hoặc Confluent Operator để cài đặt Kafka trên K8s. – Cấu hình Persistent Volume để lưu trữ dữ liệu Kafka. – Dùng Service Discovery để kết nối. | Cấu hình phức tạp, cần hiểu rõ Kubernetes và Helm. |
| Cloud (AWS, GCP, Azure) | – Khi muốn Kafka sẵn sàng trên cloud mà không cần quản lý server. – Khi cần tính sẵn sàng cao với Managed Kafka. – Khi xử lý dữ liệu real-time trên cloud. | – AWS MSK: Managed Kafka trên AWS. – Google Cloud Pub/Sub & Kafka trên GKE. – Azure Event Hubs hỗ trợ API Kafka trên Azure. | Chi phí cao, bị phụ thuộc vào cloud provider. |
2. Broker: là một máy chủ Kafka chịu trách nhiệm lưu trữ dữ liệu, xử lý yêu cầu từ producer, consumer và quản lý replication giữa các partition.
Chức năng chính của Kafka Broker
- Lưu trữ dữ liệu
- Mỗi broker lưu trữ một phần dữ liệu của các topic trong Kafka cluster.
- Dữ liệu được lưu dưới dạng partition (mỗi topic có thể có nhiều partition).
- Mỗi partition được ghi dưới dạng log segment trên disk.
- Xử lý producer và consumer
- Producer gửi dữ liệu → Broker tiếp nhận và ghi vào partition.
- Consumer đọc dữ liệu → Broker gửi dữ liệu từ partition theo offset của consumer.
- Phân phối tải trong cluster
- Nếu có nhiều broker, Kafka sẽ phân phối partition giữa các broker để cân bằng tải.
- Dùng rack-aware replication để phân phối dữ liệu giữa các máy chủ khác nhau.
Một số lưu ý khi cấu hình broker:
- Số lượng Broker tối ưu
- Kafka có thể chạy với 1 broker nhưng để đảm bảo high availability, nên có tối thiểu 3 broker.
- Số lượng broker nên là số lẻ (3, 5, 7…) để tránh tình trạng split-brain trong quá trình bầu chọn leader.
- Khuyến nghị:
- Dev/Test: 1-3 broker.
- Production: 3-7 broker tùy theo tải.
- Lưu trữ dữ liệu trên Broker
- Kafka lưu dữ liệu trên ổ cứng (disk-based) theo dạng log segment.
- Để tránh mất dữ liệu khi broker gặp lỗi, cần thiết lập log retention policy phù hợp.
- Khuyến nghị:
- Dùng SSD thay vì HDD để tăng tốc độ đọc/ghi.
- Đặt thư mục lưu trữ Kafka logs trên ổ cứng riêng biệt để tránh ảnh hưởng đến hệ điều hành.
- Cấu hình
log.retention.hoursđể giữ dữ liệu phù hợp với yêu cầu.
Ví dụ:
- log.retention.hours = 168 (giữ dữ liệu trong 7 ngày).
- log.segment.bytes = 1GB (chia nhỏ file log, tránh file quá lớn).
3. Topic: Topic trong Kafka là một kênh giao tiếp dùng để lưu trữ và phân phối dữ liệu giữa Producer và Consumer. Nó hoạt động như một message queue, nơi Producer gửi dữ liệu vào, và Consumer đọc dữ liệu từ đó.
- Mỗi topic được chia thành nhiều partition, và mỗi partition lại chứa nhiều message theo thứ tự log-based.
- Mỗi message trong partition có một offset duy nhất.
- Khi tạo một topic có thể thiết lập các thông số như: số lượng partition, số lượng bản sao, chính sách lưu trữ
- Kafka có thể lưu trữ dữ liệu trong một khoảng thời gian nhất định hoặc đến khi dung lượng đạt giới hạn.
Cách Kafka phân phối dữ liệu vào Topic
- Nếu Producer không có Key → Kafka dùng Round-Robin
- Message được phân phối đều giữa các partition.
- Mỗi partition chứa một phần dữ liệu.
- Nếu Producer có Key → Kafka dùng Hash Key
- Kafka hash Key và ánh xạ vào một partition cố định.
- Các message có cùng Key sẽ vào cùng một partition → Giúp duy trì thứ tự.
4. Partition: Partition là đơn vị lưu trữ và xử lý dữ liệu nhỏ nhất trong Kafka. Mỗi topic có thể được chia thành nhiều partition, giúp Kafka mở rộng khả năng xử lý theo chiều ngang.
Tính chất của Partition
- Chia dữ liệu thành nhiều phần nhỏ
- Dữ liệu trong Kafka không được lưu trữ dưới dạng một tệp lớn mà được chia thành nhiều partition.
- Mỗi message mới sẽ được ghi vào một partition nhất định trong topic.
- Tăng khả năng mở rộng (Scalability)
- Nhiều partition giúp Kafka phân tán dữ liệu trên nhiều broker.
- Mỗi broker có thể lưu trữ một hoặc nhiều partition, giúp hệ thống dễ dàng mở rộng khi lượng dữ liệu tăng lên.
- Ghi dữ liệu tuần tự (Append-Only Log)
- Mỗi partition hoạt động như một commit log chỉ có thể ghi dữ liệu mới vào cuối (append-only).
- Các message trong partition được lưu trữ theo offset (chỉ mục thứ tự của message trong partition).
- Tính nhất quán và khả dụng (Leader-Follower Replication)
- Mỗi partition có một Leader và nhiều Follower để đảm bảo tính sẵn sàng (high availability).
- Producer luôn gửi dữ liệu đến partition Leader.
- Nếu Leader bị lỗi, một trong các Follower sẽ trở thành Leader mới.
- Consumer đọc theo offset
- Mỗi consumer khi đọc từ partition sẽ sử dụng offset để biết đang đọc đến đâu.
- Consumer có thể đọc lại dữ liệu cũ bằng cách sử dụng offset.
Ví dụ: về cách tổ chức dữ liệu trên các partition của topic Orders: Giả sử bạn có một topic tên là orders chứa thông tin đơn hàng, bạn cấu hình topic này có 3 partition,
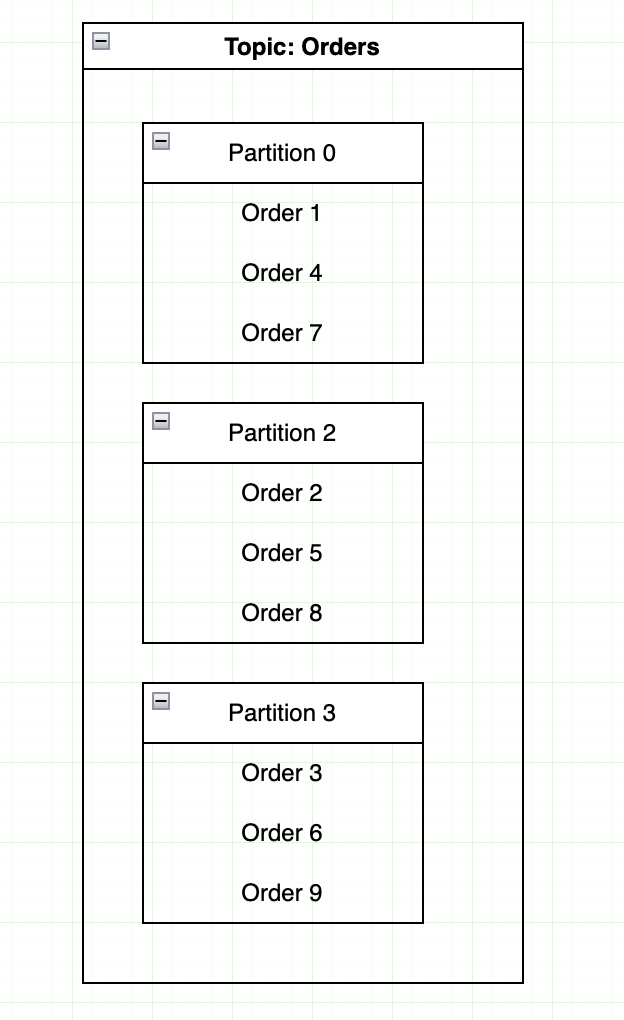
- Khi Producer gửi dữ liệu, Kafka sẽ quyết định lưu vào Partition 0, 1 hoặc 2 dựa trên Key của message hoặc Round-robin (nếu không có Key).
- Consumer Group có thể có nhiều consumer đọc dữ liệu từ các partition này song song.
- Mỗi partition được tiêu thụ bởi một consumer duy nhất, nếu consumer bị lỗi, partition sẽ được gán cho một consumer khác.
Lưu ý khi Cấu hình Partition & Replication
- Cấu hình số lượng partition hợp lý để phân tán dữ liệu tốt hơn.
- Mỗi partition chỉ có 1 leader, nên tăng số partition để tăng khả năng xử lý song song.
- Replication factor nên ≥ 2 để đảm bảo dữ liệu không bị mất khi một broker gặp sự cố.
- Khuyến nghị:
- replication.factor = 3 (ít nhất 3 bản sao dữ liệu).
- min.insync.replicas = 2 để đảm bảo dữ liệu chỉ được xác nhận khi có ít nhất 2 bản sao được cập nhật.
5. Producer: Producer trong Kafka là thành phần chịu trách nhiệm gửi dữ liệu (messages) vào Kafka topics. Nó hoạt động theo mô hình “fire and forget”, nghĩa là gửi dữ liệu mà không cần chờ phản hồi, nhưng cũng có thể yêu cầu xác nhận từ Kafka để đảm bảo dữ liệu được lưu thành công.
Chức năng chính của Producer:
Gửi dữ liệu đến Kafka
Producer có thể gửi dữ liệu đến một hoặc nhiều topic.
Có thể chỉ định key để xác định partition nào sẽ nhận dữ liệu.
- Chọn partition phù hợp (đã trình bày ở mục 3. Topic)
- Xác nhận dữ liệu đã được gửi thành công: Kafka hỗ trợ 3 chế độ xác nhận việc gửi dữ liệu thành công
acks=0: Producer không cần xác nhận từ Kafka (nhanh nhưng có thể mất dữ liệu).acks=1: Chỉ cần leader partition xác nhận (mất dữ liệu nếu leader bị lỗi).acks=all: Mọi bản sao phải xác nhận (chậm hơn nhưng an toàn nhất).
Chính sách Retry & Timeout
- Nếu một broker bị lỗi, producer có thể tự động gửi lại message.
- Kafka hỗ trợ cơ chế retry để xử lý lỗi tạm thời.
Compression – Giảm băng thông
- Kafka hỗ trợ nén message để giảm băng thông và tăng throughput.
- Các thuật toán nén:
gzip,snappy,lz4,zstd.
6. Consumer: Kafka Consumer là thành phần chịu trách nhiệm đọc dữ liệu từ Kafka topics. Nó lấy dữ liệu từ các partition của topic, xử lý và lưu trữ dữ liệu theo nhu cầu của hệ thống.
Cách hoạt động của Kafka Consumer
- Consumer kết nối đến Kafka Cluster.
- Consumer đọc dữ liệu từ các partition trong topic.
- Kafka theo dõi vị trí đọc của mỗi consumer thông qua offset.
- Consumer có thể chạy độc lập hoặc trong một Consumer Group để xử lý dữ liệu song song.
- Nếu một consumer rời khỏi nhóm hoặc thêm mới, Kafka sẽ tự động cân bằng (rebalance) để phân phối lại partition
Cấu trúc message Consumer nhận được:
- Topic: Tên topic chứa dữ liệu.
- Partition: Partition mà message thuộc về.
- Offset: Chỉ mục message trong partition.
- Key: Giá trị khóa (nếu có).
- Value: Nội dung message.
- Timestamp: Thời gian tạo message
Cách Consumer quản lý offset
- Offset là chỉ số đánh dấu message tiếp theo mà consumer cần đọc. Có 3 kiểu xử lý Offset trong kafkaa
- Auto commit (default): Kafka tự động lưu offset sau một khoảng thời gian (auto.commit.interval.ms)
- Manual commit: Consumer lưu offset bằng cách gọi hàm commit()
- At-most-one-processing: Consumer đọc dữ liệu rồi lưu offset ngay lập tức (có thể mất message nếu consumer lỗi).
- At-least-one-processing: Consumer đọc dữ liệu xong rồi mới commit offset (có thể trùng message nếu consumer restart).
- Khuyến nghị:
- Dùng manual commit (
enable.auto.commit=false) để kiểm soát offset tốt hơn. - Dùng
auto.offset.reset=earliestnếu muốn đọc từ đầu topic khi consumer mới tham gia.
- Dùng manual commit (
7. Zookeeper:
Apache Zookeeper là một hệ thống quản lý metadata và điều phối cho Kafka Cluster. Kafka sử dụng Zookeeper để:
- Theo dõi trạng thái của Kafka brokers (các broker nào đang hoạt động).
- Quản lý phân vùng (partition) và leader election.
- Lưu trữ thông tin offset của consumer groups.
Lưu ý: Từ Kafka 2.8+, Kafka hỗ trợ KRaft (Kafka Raft) để thay thế Zookeeper, giúp Kafka hoạt động độc lập mà không cần Zookeeper.
Chức năng chính của Zookeeper trong Kafka
- Quản lý Kafka Broker
- Zookeeper theo dõi danh sách broker trong cluster.
- Nếu một broker bị lỗi, Zookeeper xóa broker khỏi danh sách và Kafka sẽ thực hiện leader election.
- Leader Election (Bầu chọn Leader Partition)
- Mỗi partition có một leader và nhiều follower.
- Nếu leader bị lỗi, Zookeeper sẽ giúp Kafka bầu chọn leader mới.
- Quản lý Kafka Topic & Partition
- Zookeeper lưu trữ metadata của các topic và partition.
- Khi Kafka tạo topic, Zookeeper ghi nhận thông tin như:
- Tên topic.
- Số partition.
- Replication factor.
- Theo dõi Consumer Offset
- Trước Kafka 0.10, consumer lưu offset trong Zookeeper.
- Từ Kafka 0.10+, offset được lưu trong Kafka topic (
__consumer_offsets).
- Cấu hình & Quản lý ACL
- Zookeeper có thể lưu cấu hình bảo mật và ACL (Access Control List) của Kafka.
KRaft – Kafka thay thế Zookeeper
Từ Kafka 2.8+, Kafka hỗ trợ KRaft (Kafka Raft Metadata Mode) để loại bỏ Zookeeper.
| Yếu tố | Zookeeper | KRaft |
|---|---|---|
| Cách hoạt động | Kafka phải chạy Zookeeper để lưu trữ metadata | Kafka lưu trữ metadata trong chính bản thân nó |
| Tính phức tạp | Cần chạy thêm Zookeeper trong cluster | Đơn giản hơn, chỉ cần chạy kafka |
| Tốc độ khởi động | Chậm hơn vì cần khởi động Zookeeper | Nhanh hơn, không có độ trễ của Zookeeper |
| Tính Nhất quán | Có thể bị lỗi nếu Zookeeper mất kết nối | Ổn định hơn nhờ Raft protocol |
Trên đây là một số các khái niệm cơ bản về kafka, ở nội dung tiếp theo, tôi sẽ thực hành xây cài đặt kafka trên docker và xây dựng một ứng dụng lấy thông tin từ API sử dụng producer để gửi thông tin qua kafka. Consumer sẽ nhận dữ liệu và lưu trữ vào database.

Nhật Bản cuối cùng thì… “Bài báo của Nikke, việc thay đổi mật khẩu định kỳ rất nguy hiểm” đã trở thành một chủ đề lớn

Chúng tôi đã “DDoS” server như thế nào
