Bài toán Object Detection với Faster R-CNN
Object Detection là gì ?
Object Detection – Nhận dạng đối tượng là thuật ngữ để mô tả đến nhiệm vụ của hệ thống máy tính để định vị các đối tượng trong một hình ảnh và xác định từng đối tượng. Object Detection đã được sử dụng rộng rãi để phát hiện khuôn mặt, phát hiện biển số xe, đếm số người đi bộ và xe không người lái. Hay là trong cuộc sống bình thường 1 bức ảnh có thể bao gồm rất nhiều đối tượng và chúng ta cần biết vị trí của từng đối tượng đó và đối tượng đó là gì.
Bài toán Object Detection có thể chia làm 2 bài toán nhỏ dựa vào input đầu vào giả sử là các bức ảnh và output là vị trí của từng đối tượng đó là:
Xác định các bounding box cho từng đối tượng – là hình chữ nhật được vẽ bao quanh đối tượng để xác định được đối tượng.
Sau khi xác định được các bounding box thì ta cần phân loại xem nó thuộc label gì và phần trăm dự đoán chính xác.
Các mô hình R-CNN
Để tìm hiểu về Faster R-CNN, thì mình sẽ giới thiệu chút về mạng R-CNN (regions with CNN features) đây là một tập hợp các mô hình xác định những đặc trưng dựa trên mạng CNN. Ba mô hình chính là R-CNN, Fast R-CNN và Faster-RCNN được tạo ra để phục vụ cho bài toán object detection.
1. R-CNN (2014)
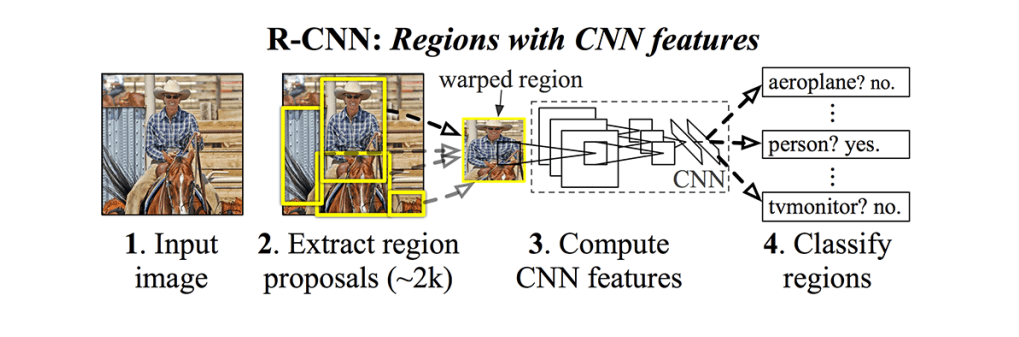
R-CNN bao gồm 3 phần chính:
Region proposal: hay còn gọi là vùng đề xuất nó là những vùng có khả năng chứa đối tượng hay những đặc điểm quan trọng của hình ảnh.
Feature Extractor: để dùng tính toán lại các feature, nhận diện hình ảnh từ các region proposal thông qua các mạng deep convolutional neural network.
Classifier: phân loại hình ảnh chứa trong region proposal về đúng label của nó.
Tuy nhiên như ở ảnh trên ta sử dụng thuật toán selective search cho tới tận 2000 region proposal, các region proposal có thể được phát hiện bởi đa dạng những thuật toán khác nhau. Nhưng điểm chung là đều dựa trên tỷ lệ IoU giữa bounding box và ground truth box. Vấn đề với R-CNN thì là do mỗi ảnh ta cần phân loại label cho 2000 proposal nên thời gian train sẽ rất lâu.
2. Fast R-CNN (2015)
Fast R-CNN được ra đời sau đó 1 năm và nó giải quyết được một số vấn đề hạn chế của người đi trước nhằm cải thiện về mặt tốc độ.
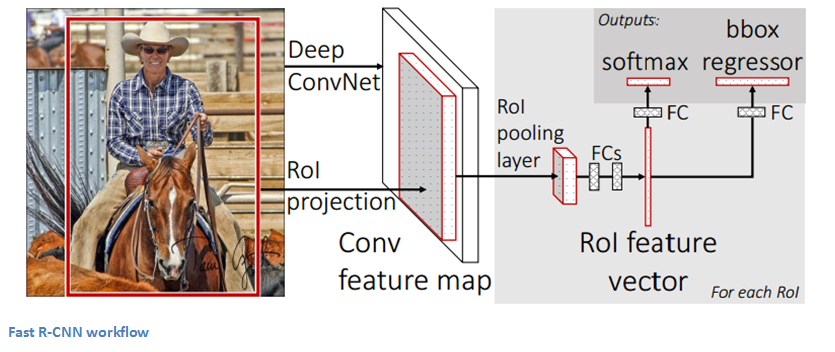
Tương tự như là R-CNN thì Fast R-CNN vẫn sử dụng selective search để lấy ra các region proposal. Điểm đột phá của Fast R-CNN là sử dụng một single model thay vì pipeline để phát hiện region và classification cùng lúc. Fast R-CNN sẽ cho cả 1 bức ảnh vào ConvNet (1 vài convolutional layer + max pooling layer) để tạo ra convolutional feature map. Sau đó từ các region proposal được lấy ra từ convolutional feature map tiếp đó ta sẽ flatten và thêm 2 fully connected layers (FCs) sau đó kết quả sẽ được chia ra làm 2 nhánh 1 là để dự đoán label của region proposal và 2 là giá trị offset values Là các tham số giúp xác định bounding box bao gồm tâm của bounding box (x, y) và chiều dài, chiều rộng (w, h). Tuy nhiên vì thời gian tính region proposal vẫn rất lâu vì thuật toán selective search vì thế ta cần thay thế nó từ đó Faster R-CNN ra đời.
3. Faster R-CNN
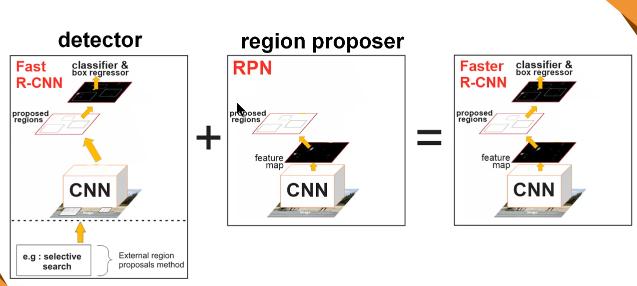
Vì là mô hình sinh sau đẻ muộn hơn 2 mô hình trên nên nó đã được cải thiện hơn nữa về cả mặt tốc độ training và cả nhận dạng hay phát hiện các đối tượng. Faster R-CNN không sử dụng thuật toán selective search để lấy ra các region proposal nữa, mà nó thêm một mạng CNN mới gọi là Region Proposal Network (RPN) để tìm ra các region proposal.
Kiến trúc này cũng là sự kết hợp của 2 modules:
Region Proposal Network.
Fast R-CNN: Mạng CNN dùng để trích xuất các features từ các region proposal và trả ra các bounding box cùng với label cho từng bounding box như đã đề cập ở trên.
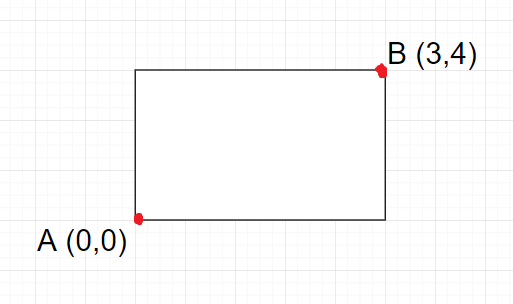
RPN input là feature map và output sẽ là regional proposal(một hình chữ nhật được xác định bằng 2 điểm ở 2 góc, ví dụ A(x_min, y_min) và B(x_max, y_max)). Khi RPN dự đoán ta phải rằng buộc x_min < x_max và y_min < y_max. Hơn nữa các giá trị x và y khi dự đoán có thể ra ngoài khỏi bức ảnh.
RPN hoạt động bằng cách đầu tiên là hình ảnh đầu vào được thay đổi kích thước sao cho cạnh ngắn nhất là 600px với cạnh dài hơn không quá 1000px. Input image được đưa qua 1 backbone CNN để thu được feature map. Sau đó một mạng con RPN dùng để lấy ra các vùng như là RoI – Region of Interest hoặc các vùng có khả năng chứa đối tượng cần tìm từ feature map của ảnh đó. Input của RPN là feature map, output của RPN bao gồm 2 phần:
- Binary object classification (để phân biệt đối tượng với background, không quan tâm đối tượng là gì) .
- Bounding box regression (để xác định vùng ảnh có khả năng chứa đối tượng), vậy nên RPN bao gồm 2 hàm loss và hoàn toàn có thể được huấn luyện riêng so với cả model.
Faster-RCNN còn định nghĩa thêm khái niệm anchor, nó là một bounding box cơ sở để xác định bounding box bao quanh vật thể dựa trên các phép dịch tâm và scale kích thước chiều dài, rộng. Mỗi loại anchor box sẽ phù hợp để tìm ra bounding box cho 1 loại vật thể đặc trưng nhất định. Sau khi đi qua RPN, ta nên sử dụng RoI Pooling (đã có từ Fast-RCNN) để thu vùng RoI về cùng 1 kích thước cố định. Sau đó ta thực hiện tách thành 2 phần ở phần cuối của model để phục vụ cho mục đích xác định label cho object và bounding box cho nó vì thế ta cần 1 cho object classification với N + 1 (N là tổng số class, +1 là background) và 2 là bounding box regression.
Anchor Box trong Faster R-CNN có ý tưởng là thay vì dự đoán 2 góc ta sẽ dự đoán điểm trung tâm (x_center, y_center) và width, height của hình chữ nhật. Như vậy mỗi anchor được xác định bằng 4 tham số (x_center, y_center, width, height). Nó được định nghĩa với 9 anchors ứng với mỗi pixel trên feature map. Việc tính toán tổng số lượng anchor là dựa trên kích thước của feature map. Giả sử chúng ta có 1 bức ảnh 400 x 600, các tâm của anchor box cách nhau 16 pixel từ đó ta tính được có (400 * 600)/(16*16) = 938 tâm. Với mỗi tâm ta lại định nghĩa 9 anchors với kích thước 64×64, 128×128, 256×256 với mỗi kích thước lại có 3 tỉ lệ tương ứng là 1:1, 1:2, 2:1, từ đó ta có được 938 * 9 = 8442 anchors.
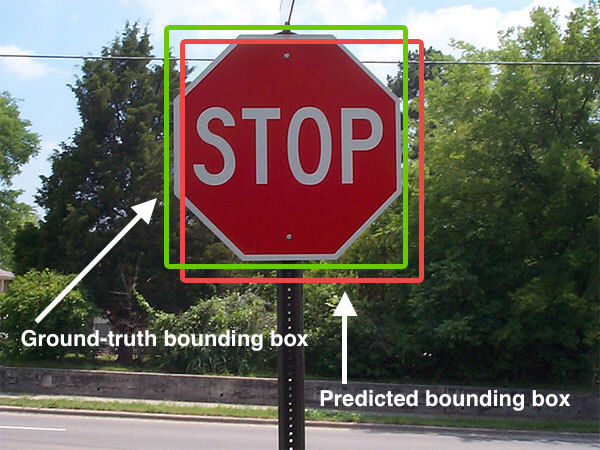
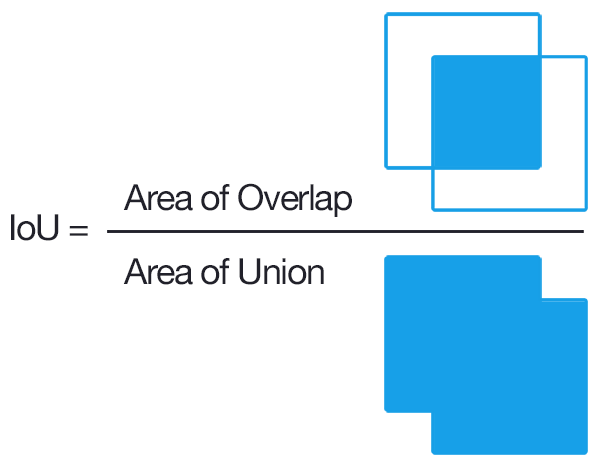
Trong hình trên, hộp màu xanh được coi là ground truth box và hộp màu đỏ được gọi là anchor box. Cách để chúng ta biết liệu anchor box có chứa đối tượng hay không là sử dụng IOU thì IOU được xử dụng trong bài toán object detection, để đánh giá xem bounding box dự đoán đối tượng khớp với ground truth thật của đối tượng. Trong đó Area of Overlap là diện tích phần giao nhau giữa predicted bounding box với grouth-truth bounding box , còn Area of Union là diện tích phần hợp giữa predicted bounding box với grouth-truth bounding box. Những bounding box được đánh nhãn bằng tay trong tập training set và test set. Nếu IOU > 0.7 thì prediction được đánh giá là positive có thể chứa vật còn ngược lại nếu IOU < 0.3 thì prediction được đánh giá là negative (không chứa vật). Và các anchor nằm trong khoảng 0.3 <= x < 0.7 sẽ được coi là neutral (trung tính) là sẽ không được sử dụng trong quá trình huấn luyện mô hình
Sau khi có đi qua mạng RPN thì chúng ta sẽ lấy output của nó là image có chứa các region proposals để làm input cho phần detector. Input là bức ảnh chứa các region proposals vào ConvNet (1 vài convolutional layer + max pooling layer) để tạo ra convolutional feature map. Sau đó từ các region proposal được lấy ra từ convolutional feature map tiếp đó ta sẽ flatten và thêm 2 fully connected layers (FCs) để dự đoán label cũng như là offset values của chúng. Ở bước này chúng ta có thể thấy rằng nó giống hệt phần Fast R-CNN.
Và đó là tất cả các mô hình đặc trưng nhất được tạo ra để phục vụ bài toán Object Detection. Trong bài viết này chúng ta biết được sự phát triển của các lớp mô hình ứng dụng trong object detection nếu có gì thiếu sót các bạn có thể góp í với mình nhé. Cảm ơn mọi người rất nhiều!
Advanced XSS methods and how to prevent – part 2
