Định lượng của thông tin
1.Mở đầu
Thỉnh thoảng mình lại đọc một cái gì đó trong lúc rảnh rỗi và đọc thì … không hiểu, mà đã không hiểu thì rất bực, nó cứ dai dẳng trong tâm trí, mà đến khi tìm được đáp án thì vui thực sự. Hồi học cấp 2, giáo viên thường đưa ra những công thức mà lại không giải thích tại sao lại thế ví dụ như: x lớn nhất/nhỏ nhất của parabol = -b/2a, y lớn nhất/ nhỏ nhất = – delta/4a. Wtf ? Tại sao ra đc như thế ? Lên cấp 3, ta lại biết đến cái trò giải hệ pt bằng cách đặt D, Dx, Dy. Wtf ? Sao lại kỳ diệu đc thế nhỉ ? Giáo viên chả giải thích gì cả ? Ghét nhất cái việc phải chấp nhận những cái mà mình không hiểu ?
Nhưng thôi stop những cái đó, hôm nay mình muốn viết về Entropy, nó là một trong những cái mình muốn biết “vì sao nó lại như thế “? Nghiên cứu về thông tin hay dữ liệu là một ngành khoa học rất thú vị và từ lâu đã được đưa vào thành một môn học để giảng dạy. Rất buồn hoặc rất tiếc khi từ trước mình chưa thấy sự thú vị về nó, và có khi đơn giản chỉ coi như là một môn học, và học để qua môn. Nhiều môn đen đủi hơn thì … không qua. Đợt lâu về trước, không hiểu sao mình coi nó là một cái nhọt cần phải gỡ nó ra, và mình bắt đầu tự tìm hiểu và phải viết nó ra để đỡ quên, vì không chấp nhận đc cái việc đọc sách và coi nó là auto đúng, mình muốn biết vì sao nó lại như thế chứ không phải vì nó đơn giản là như thế =)).
2.Độ đo của thông tin
Giả sử sáng nay khi bạn đi làm, thằng cu đồng nghiệp ngồi cạnh bạn thông báo một tin cực shock: “Anh đã biết gì chưa? Sáng nay có thêm vài ca nhiễm covid-19 mới đấy”. Ờ, tin cũng hot đấy, nhưng ngày éo nào chả có người nhiễm mới, chả thú vị lắm. Sau đó con bé đồng nghiệp ngồi trên quay xuống kể: “Này, hôm qua con H ở dự án Q tỏ tình với thằng B ở đội I nhưng bị từ chối rồi, sad”. Uây, tin này hot này, trước nay cứ tưởng con H nó thích thằng T ở dự án A cơ mà nhỉ ? Không thể ngờ được.
Rõ ràng câu chuyện của thằng cu đồng nghiệp vừa nói, chả mang lại tí tẹo thông tin nào, vì đơn giản câu chuyện của nó quá dễ đoán, khả năng xảy ra cao. Nhưng thông tin con bé đồng nghiệp kia thì mang lại quá nhiều thông tin, vì đơn giản, điều đó mình hoàn toàn không đoán được. Vậy giả sử ta coi mỗi thông điệp được truyền tải mang theo một biến cố với xác suất xảy ra là p. Xác suất p càng tiệm cận đến 1, vậy thì thông tin mang lại càng ít, và ngược lại, p càng gần 0 thì thông tin mang lại càng nhiều. Nghe có vẻ mơ hồ, mà toán thì không thích mơ hồ, ta cần định lượng chính xác về thông tin.
Giả sử ta coi mọi thứ quy về một hàm y = f(x), một cách ánh xạ thú vị mà ta gặp từ hồi học cấp 2 tới giờ. với y là độ đo thông tin. x là p(E) hay được gọi là biến cố để xảy ra E (như ví dụ nãy, x là xác suất xảy ra biến cố E – sáng nay có thêm vài ca nhiễm covid-19). Ta phân tích chút nhé:
- Rõ ràng ta thấy rằng nếu x = 1 thì y = 0, nếu xác suất xảy ra, thì thông tin không có giá trị, nếu x < 1 thì y > 0, dĩ nhiên, chỉ cần có một xác suất nào đó ta không có chút hiểu biết gì về thông tin nghe được, thì thông tin đó vẫn có giá trị.
- Thêm một điểm nữa, f phải là hàm nghịch biến, vì ta thấy rõ ràng nếu x càng lớn thì thì y càng giảm, xác suất p(E) càng dễ xảy ra thì y càng nhỏ và ngược lại.
- Tiếp theo nữa, cái này quan trọng nè. Giả sử ta coi E và F là hai biến cố độc lập, x1 = p(E) và x2 = p(F), ta có y1 + y2 = f(x1.x2) hoặc là f(x1) + f(x2) = f(x1.x2). Từ từ, khó hiểu quá, lấy ví dụ nhé, giả sử E là biến cố “Ngày mai trời mưa”, F là biến cố “Ngày kia trời cũng mưa”. Vậy thì rõ ràng y1 + y2 sẽ là định lượng thông tin của thông điệp “Ngày mai và ngày kia trời mưa”. Vậy thì rõ ràng hai thông điệp này phải đồng thời xảy ra, vì nếu chỉ một trong hai xảy ra, thông điệp cần xác nhận sẽ là vô nghĩa => vậy thì gọi x là biến cố ngày mai và ngày kia trời đều mưa thì x = p(E).p(F) = x1.x2. Vậy thì công thức trên là chuẩn rồi, nhắc lại nhé f(x1) + f(x2) = f(x1.x2).
Từ tất cả các điểm trên, hàm số y = f(x) phải có dạng y = k.ln(x) thoả mãn những tính chất trên. Ta nhận thấy x = p(E) là một giá trị nằm trong khoảng [0, 1] (trường hợp 0 ta sẽ đề cập tới sau), và y phải có giá trị dương. Để thoả mãn điều đó thì nhất định k < 0. Bây giờ ta đặt k = 1/ln(b). Cuối cùng ta đã có công thức độ đo hàm lượng thông tin của một thông điệp với biến cố E như sau: y = ln(x)/ln(b) . Hay viết một cách đẹp đẽ hơn:
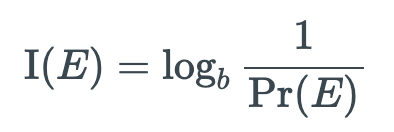
3.Entropy
Về bản chất, Entropy là trung bình thông tin của biến ngẫu nhiên rời rạc. Hay có thể nói Entropy dùng để đo độ bất xác định khi dự đoán về một biến ngẫu nhiên X. Ta ký hiệu là H(X). Đi nhanh vào công thức ta giả sử rằng, với một biến ngẫu nhiên X nhận được các giá trị rời rạc trong tập giá trị {x1, x2, …., xn}, ví dụ như tung xúc xắc ta nhận được các giá trị trong khoảng {1, 2, … 6}; tương tự ta có vector xác xuất với mỗi trạng thái là p = (p1, p2, …pn). Ta có:
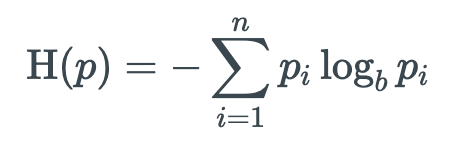
Ta đẩy dấu trừ ra ngoài để loại bỏ số 1 trong hàm log, công thức nhìn cũng gọn hơn. Trước khi đi sâu vào công thức ta có vài nhận xét như sau, H(p) là một hàm không âm, cái này dễ hiểu. Cơ số b trong công thức là đơn vị thông tin sử dụng, ví dụ: Với Entropy nhị phân thì cơ số b = 2. Như đã nói ở trên, với xác xuất p có khả năng bằng 0, mà làm log thường không xác định tại 0. Nhưng may mắn thay:
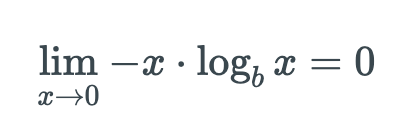
Và đặc biệt nhất hàm H(p) đạt giá trị lớn nhất khi phân bố xác suất là phân bố đều, tức là mọi giá trị đều có xác suất xảy ra là như nhau. Ví dụ khi ta tung xúc xắc, tỷ lệ ra 1, 2, 3, 4, 5, 6 là bằng bằng nhau = 1/6.
Ví dụ thực tế hơn nhé. Giả sử ta có 1 cái thùng, ta sẽ đổ một ít hoa quả vào đó, sau đó thông tin bạn nhận được là gì trong mỗi trường hợp sau đây nếu như bạn được yêu cầu bốc ra lượng hoa quả nhất định
- Bạn đặt vào 10 quả cam => Ồ, nếu toàn cam, thì bốc ra sẽ toàn cam thôi, quá dễ đoán
- Bạn đặt vào 8 quả cam, 2 quả táo => Ồ, chắc bốc ra sẽ toàn cam thôi, cam nhiều thế cơ mà
- Bạn đặt vào 5 quả cam, 5 quả táo => Hơi khó đoán, có thể bốc ra sẽ nhiều cam hơn táo, hoặc táo nhiều hơn, nói chung tỷ lệ chắc sẽ như nhau
- Bạn đặt vào 6 quả cam, 4 quả táo => Chắc vẫn bốc nhiều cam hơn, nhưng không biết được.
Đấy là về cảm quan là vậy, nhưng về công thức thì sao. Giả sử với cơ số b = 2 nhé.
- H(E) = – 1.log(1) – 0.log(0) = 0 Vì xác suất lấy được cam là 100%, táo thì là 0%
- H(E) = – 0.8.log(0.8) – 0.2.log(0.2) ~ 0.72192808 Vì xác suất lấy được cam là 80%, táo là 20%
- H(E) = – 0.5.log(0.5) – 0.5.log(0.5) ~ 1 Vì xác suất lấy được cam là 50%, táo là 50%
- H(E) = – 0.6.log(0.6) – 0.4.log(0.4) ~ 0.97095056 Vì xác suất lấy được cam là 60%, táo là 40%
Vậy là đúng rồi, Entropy càng cao thì độ bất xác định dự đoán càng cao, biến cố ấy càng khó xác định, khó đoán biết trước được, và ngược lại.
4. Ứng dụng
Ứng dụng của Entropy thì nhiều lắm, nhưng xin phép dành cho một blog khác, nếu như hôm đó tìm hiểu được cái gì đó hay ho hoặc nổi hứng viết lách cái gì đấy
5. Tham khảo
Chủ yếu trong lúc mày mò thì tìm được blog này, tự đọc và viết lại theo ý hiểu. Mục đích để viết và tự nhớ. Nếu ai muốn tìm hiểu nhiều và sâu hơn thì nên đọc tại đây. Dài hơn và chi tiết hơn, blog rất hay.
https://thetalog.com/statistics/ly-thuyet-thong-tin/

Bài toán Object Detection với Faster R-CNN
