Máy tính đang dần tác động vào các quyết định của con người!
Chúng ta thường bảo với nhau rằng Facebook, google đang nghe lén chúng ta, đang đọc suy nghĩ của chúng ta, thật vậy sao? Khi đang lướt facebook, chúng ta sẽ thường xuyên bắt gặp các quảng cáo về quán beefsteak mà chúng ta vừa mới kêu thèm với bạn bè hồi chiều, hay là hàng loạt các quảng cáo về tour du lịch, villa, khách sạn nổi lên khi bạn vừa search lịch nghỉ lễ trên google. “Nghe lén” thì không hẳn nhưng theo dõi thì chắc chắn. Tất cả các loại quảng cáo trên đều là sản phẩm của một hệ thống được gọi là “Recommendation System” được xây dựng bên trong các Ứng dụng web mà chúng ta đang sử dụng.
Khái niệm
Recommendation System hay tiếng Việt là Hệ thống gợi ý, hệ tư vấn là công cụ phần mềm và kỹ thuật cung cấp các tư vấn về các mục (item) có khả năng là hữu ích nhất với người dùng đích. Hệ tư vấn có thể xuất hiện trong rất nhiều các sản phẩm như tư vấn sách (tiki), tư vấn video (youtube) tư vấn phim (IMDB) tư vấn du lịch (tripadvisor), tư vấn sản phẩm hàng hóa (shopee),… Tuy nhiên, các hệ thống tư vấn đều tuân theo một công thức chung.
Với 1 tập item S chứa N item và một tập người dùng U có M người dùng của hệ thống:
– Mỗi mục s thuộc S chứa tập tin đặc trưng của mục,
– Mỗi người dùng u thuộc U chứa tập tin cá nhân chứa đặc trưng người dùng
– Trường hợp M, N là đủ lớn
–> Độ hữu ích p(u,s) của một mục s đối với một người dùng u được tính bằng một hàm đo độ hữu ích của s đối với u và cho một giá trị thuộc tập hữu hạn có thứ tự p(u,s) thuộc [0,P]
Khi đó ta xây dựng được một ma trận người dùng – mục kích thước MxN được dùng để xác định độ hữu ích .

Tại một thời điểm p(u,s) có thể được xác định (trực tiếp, gián tiếp) hoặc có thể chưa được xác định. Khi một người dùng u tương tác với hệ thống, hệ thống sẽ xác định tất cả các giá trị p(u,s) của tất cả sản phẩm thuộc S mà người dùng u chưa tiếp cận được. Đưa ra top k – mục hữu ích nhất đối với người dùng u. Kỹ thuật xác định giá trị p(u,s), được gọi là kỹ thuật lọc, đối với các mục s ∈ S mà u chưa tiếp cận được thường được gọi là kỹ thuật lọc và được nhóm thành năm lớp là lọc dựa trên nội dung (content-based, gọi tắt là lọc nội dung), lọc dựa trên cộng tác (collaborative based, gọi tắt là lọc cộng tác), lọc dựa trên tri thức (knowledge-based), lọc dựa trên nhân khẩu học (demographic) và lọc kết hợp (hybrid) kết hợp các kỹ thuật lọc trên đây.
Tính chất
Hệ tư vấn được xây dựng tốt được kỳ vọng là đảm bảo một số tính chất như:
- Tính liên quan: Các mục được tư vấn liên quan đến người dùng.
- Tính mới lạ: Các mục được tư vấn là các mục mà người dùng chưa tiếp cận hoặc khó tiếp cận, tránh lặp lại các mục phổ biến.
- Tính may mắn bất ngờ: Tạo ra các tư vấn mà người dùng nhận được sự ngạc nhiên trong kết quả.
- Tính đa dạng, gia tăng: Các mục tư vấn nên đa dạng, tránh cùng loại.
- Tính giải trình: Các mục tư vấn cần đi kèm thông tin vì sao lại tư vấn mục đó cho người dùng.
Các kỹ thuật lọc và kiểu hệ thống tư vấn
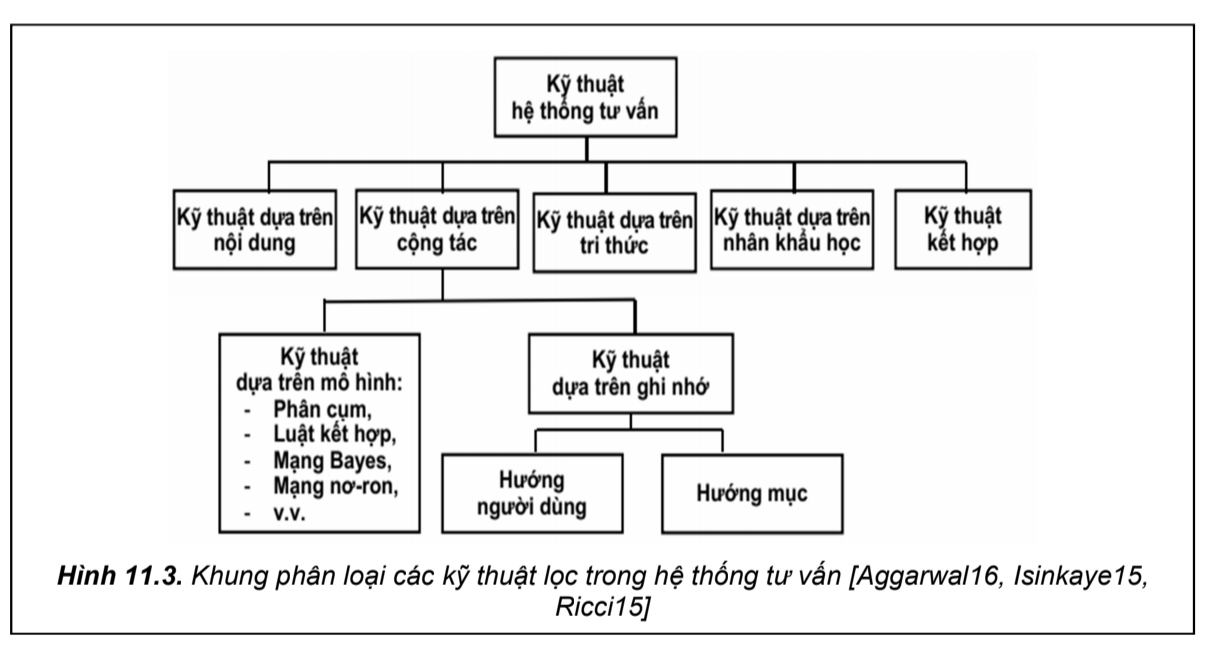
Hệ thống tư vấn có thể được phân loại dựa theo kỹ thuật lọc được sử dụng, như vậy có thể chia hệ thống tư vấn thành năm lớp chính là:
- Hệ tư vấn lọc dựa trên nội dung
- Hệ tư vấn lọc dựa trên tri thức
- Hệ tư vấn lọc dựa trên nhân khẩu học
- Hệ tư vấn kết hợp
Tuy nhiên, để gói gọn kiến thức và có một phương pháp tiếp cận dễ hiểu, trong bài blog này tôi sẽ chỉ giới thiệu về kỹ thuật lọc cộng tác.
Kỹ thuật lọc cộng tác
Kỹ thuật lọc cộng tác là kỹ thuật đơn giản, dễ thực hiện và dễ tiếp cận nhất để tìm hiểu ban đầu về Hệ tư vấn, với kỹ thuật này, từ tập người dùng, tập mục vị trí và các đăng ký của mỗi người dùng, xây dựng một ma trận người dùng – mục. Ngoài ma trận hữu ích người dùng, mục thì kỹ thuật lọc cộng tác không yêu cầu thêm bất kỳ thông tin gì khác, không cần thêm tri thức miền tư vấn do đó đây là một kỹ thuật độc lập miền.
Như sơ đồ đã đưa ra ở trên, kỹ thuật lọc cộng tác được chia thành hai nhóm con bao gồm: Kỹ thuật lọc dựa trên ghi nhớ (Hướng người dùng và hướng mục) và Kỹ thuật lọc dựa trên mô hình. Trong đó kỹ thuật lọc dựa trên ghi nhớ còn có thể gọi là kỹ thuật dựa trên láng giềng vì từ ma trận hữu ích người dùng – mục, kỹ thuật này xác định các láng giềng là các người dùng (hoặc mục) tương tự nhau và sử dụng thông tin của láng giềng để tính toán độ hữu ích. Thường kỹ thuật lọc cộng tác chia hai pha để thực hiện: pha ngoại tuyến – Tính toán các tập láng giềng để cung cấp cho người dùng; pha trực tuyến – Tính toán độ hữu ích p(u;i) của mục i đối với người dùng u và lựa chọn các mục tư vấn cho u.
Cụ thể, dưới đây là minh họa các bước thực hiện cho kỹ thuật lọc cộng tác hướng người dùng:
- Tập láng giềng của người dùng u được xác định bởi một độ đo tương tự cụ thể, ví dụ độ quan tâm của u và những người dùng khác đối với các mục.
- Với mỗi người dùng u thuộc tập U, gọi Su là tập các mục đã được người dùng u đánh giá
- Bước 1: Xác định tập k người dùng láng giềng của u
– Xem xét ma trận hữu ích người dùng – mục, vector pu hàng thứ u biểu diễn mức độ quan tâm của người dùng u đối với các mục:
pu = (p(u,1), p(u,2), …, p(u,N))
– Độ tương tự sim(u,v) của người dùng u và người dùng v được tính toán dựa trên hai vector pu và pv
– S(uv) = Su giao với Sv là tập các mục i đã được cả u và v đánh giá.
– Sau khi tính toán được độ tương tự của u với M-1 người dùng khác, tập N(u) là tập có sim(u,v) lớn nhất được xác định. - Bước 2: Tính toán độ quan tâm của người dùng u với các tập mục i mà người dùng u chưa đánh giá dựa trên tập láng giềng.
- Bước 3: Chọn các mục có p(u,i) lớn nhất để tư vấ cho u.
Lọc cộng tác hướng mục cũng tương tự với việc đối tượng xác định láng giềng của mục i và tính toán độ hữu ích của tập mục i đối với người dùng u từ các tập láng giềng của i.
Như vậy bài toán lọc cộng tác có thể được xem như là khái quát của bài toán phân lớp hồi quy. Điểm quan trọng của kỹ thuật này là tính được độ đo tương tự giữa các người dùng (hoặc các mục) để đưa ra tập k – láng giềng chính xác nhất. Để nâng cao độ chính xác của công việc này, có thể áp dụng các kỹ thuật luật kết hợp, phân cụm, cây quyết định, mạng nơron nhân tạo,…
Bảng tổng quát về các kỹ thuật lọc cộng tác
MDP: Markov decision processes,
SVD: singular value decomposition,
PCA: principal components analysis
| Thể loại | Kỹ thuật đại diện | Ưu điểm chính | Khuyết điểm chính |
| CF dựa trên bộ nhớ | – CF dựa trên láng giềng. – Tư vấn k-top đầu | – Dễ thực hiện – Dữ liệu mới có thể được thêm vào dễ dàng và tăng dần – Không cần xem xét nội dung các mục – Cho tỉ lệ tốt với các mục đồng hạng | – Phụ thuộc vào xếp hạng của con người – Giảm hiệu năng khi dl thưa – Không thể tư vấn trực tiếp cho người dùng và mục mới. – Tính mở rộng bị hạn chế với bộ dl lớn |
| CF dựa trên mô hình | – CF mạng tin cậy Bayes – CF phân cụm – CF dựa trên MDP – CF ngữ nghĩa tiềm ẩn – Phân tích nhân tử thưa – CF sử dụng kỹ thuật giảm chiều (SVD, PCA,…) | – Giải quyết tốt hơn về độ thưa thớt, khả năng mở rộng và các vấn đề khác – Cải thiện hiệu năng dự đoán. – Đưa ra một lý do trực quan cho tư vấn | – Xây dựng mô hình tốn kém – Đánh đổi hiệu năng dự đoán với khả năng mở rộng – Mất mát thông tin hữu ích cho các kỹ thuật giảm chiều |
| CF Kết hợp | – CF dựa trên nội dung – CF tăng cường nội dung – CF lai kết hợp các thuật toán CF dựa trên bộ nhớ và mô hình | – Khắc phục hạn chế của CF dựa trên nội dung và/hoặc kiểu tư vấn khác – Cải thiện hiệu năng dự đoán – Khắc phục các vấn đề của CF (thưa thớt, cừu xám,…) | – Độ phức tạp và chi phí thực hiện tăng. – Cần thông tin bê ngoài thường không có sẵn. |
Một số độ đo tương tự trong lọc cộng tác
Độ đo cosine
Độ đo cosine (Ký hiệu CV) là độ đo được sử dụng để tính toán độ tương tự giữa hai vector cùng hàng (hoặc cùng cột)
![]()
![]()
Tương tự với công thức tính độ tương tự giữa hai vector cùng cột (i,j)
Hạn chế của độ đo cosine CV trong công thức là việc không xem xét đến độ khác biệt trung bình và phương sai trong đánh giá các mục của hai người dùng u và v (hoặc các người dùng đối với hai mục i và j)
Độ tương quan Pearson
Độ tương quan Pearson (Pearson Correlation: Ký hiệu PC) được xây dựng để khắc phục hạn chế của độ đo cosine CV. Độ tương quan PC của hai người dùng u và v được xác định bằng công thức: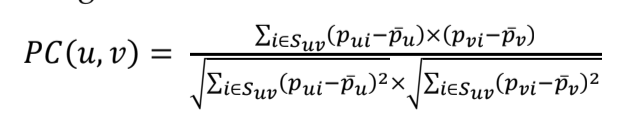
Độ tương tự Cosine điều chỉnh
Độ tương tự Cosine điều chỉnh (Adjusted Cosine: Ký hiệu AC) có độ chính xác cao hơn độ tương quan trong hệ thống lọc cộng tác được xác định theo công thức:
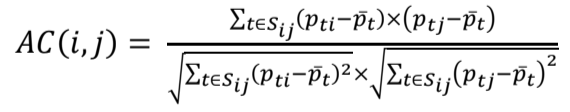
Kỹ thuật lọc cộng tác là kỹ thuật cơ bản và là hướng đơn giản nhất để tiếp cận miền tri thức về hệ tư vấn. Với những nội dung trên đây hy vọng đã giúp bạn có những cách nhìn cơ bản nhất về hệ thống tư vấn, từ đó có con đường nghiên cứu đơn giản hơn. Trong nội dung bài blog tiếp theo tôi sẽ giới thiệu một số ví dụ về kỹ thuật lọc cộng tác trong hệ thống đề xuất.
[Data-Science] Tổng quan

Data Analysis with Pandas and Python 1 – Intro, Jupyter Notebook, and pd Series

Tổng quan về NumPy
About The Author
Thai Tien Dung
Add a Comment
You must be logged in to post a comment.
Hiuhiu, nội dung học thuật quá, chưa có thực hành. :v
Thế làm tý thực hành đi anh :v