Chúng tôi đã “DDoS” server như thế nào
Vào hồi 17h00 ngày 2021/06/24, một buổi chiều trời quang đãng, gió thổi mây trôi, khung cảnh nhìn từ tầng 24 của Discovery Tower vô cùng nên thơ lãng mạn, thì bỗng nhiên mây đen vần vũ, chớp loé liên hồi, sấm giật đùng đùng và màn hình slack hiện lên message:
Anh ơi cứu em !!! Lên tắt giúp em mấy cái job trên digdag với. Em lỡ `digdag enable` coordinator hourly, giờ nó chạy 1 đống, không tắt được.
Vội vàng đáp lại lời kêu cứu của người anh em (tạm gọi là kỹ sư T) tôi mở ngay digdag lên mồm lẩm bẩm: “hourly là chạy 24 lần 1 ngày, 1 tháng có 30 ngày, mà con này thấy cả năm nay chưa chạy lần nào, thôi b* m* rồi” . Sau đó khung cảnh đập vào mắt là(hình minh hoạ):
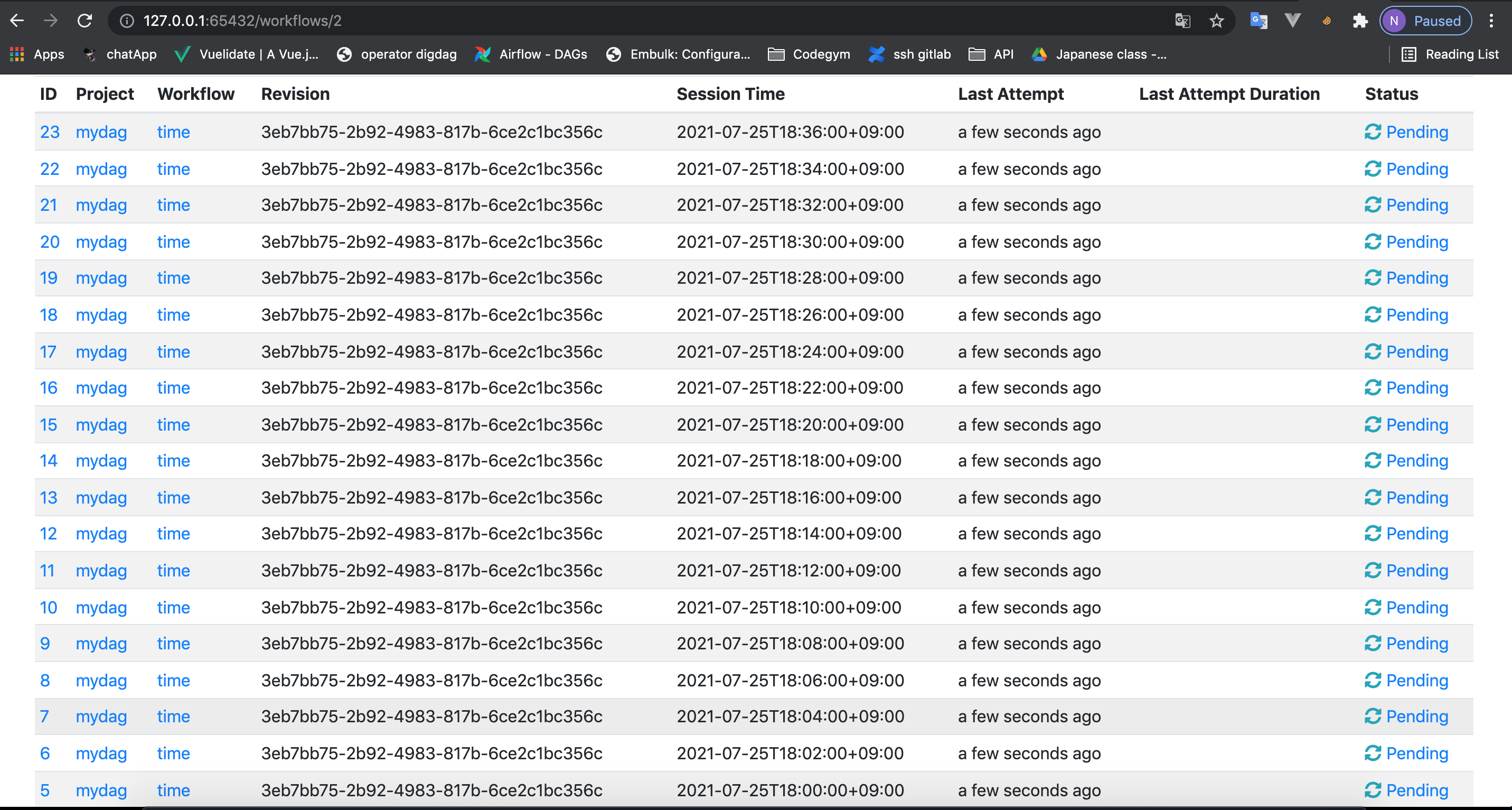
Bằng cách duy nhất có thể nghĩ ra vào lúc đó tôi click vào từng cái job và kill nó đi bằng tay =)). Tắt được tầm chục cái thì màn hình chết chóc xuất hiện: 504-Gateway Time-out. Cả team nhốn nháo: có ai vào đc digdag không, sao treo rồi, có khi nào “sập server”. Cái từ sập server vang lên nhẹ nhàng thánh thót mà tôi nghe như sét đánh giữa trời quang. Từ bé tới giờ mới chỉ có làm sập giàn mướp của mẹ vì trèo bắt chim thôi chứ có biết sập server nó thế nào đâu.
Thế là ngay lập tức báo lại tình hình cho leader, huy động anh em lên kill hộ mà cũng lực bất tòng tâm,vì không có quyền đụng vào server, cuối cùng phải nhờ các bác bên Nhật xử lý giúp. Các bác ấy đã làm như thế nào?:
- Đầu tiên là thử restart lại server -> Failure, do trạng thái các thái của wf đã đc lưu trên server , nên restart lại thì nó vẫn chạy.
- Thử cách thứ 2: Update lại các trạng thái của wf trên DB rồi restart -> Failure, các wf vẫn chạy lại.
- Cách thứ 3: Các bác quyết định rollback server về thời điểm trước khi sự cố xảy ra rồi restart —> Successssssssss!
Nếu mà được ở bên cạnh thì xin được trao cho các bác những cái ôm thắm thiết nhất. Về đến nhà vẫn tim đập chân run không biết ngày mai sống chết thế nào. Cùng lúc đó chàng kỹ sư T còn share cho tôi cái tin nhắn của leader:`không sao anh ơi, sự cố đã được khắc phục, anh chuẩn bị viết đơn xin nghỉ việc mai lên gặp bác Sato nhé` , nghe mà nẫu hết cả ruột gan ( sau mới biết đó là ông leader troll )
Từ lúc bắt đầu sự cố đến lúc được phục hồi, dev server đã trải qua 5h (18:50 ~ 23:30)không thể hoạt động do cùng lúc một lượng lớn các request được gửi đến server nên khiến cho resource bị cạn kiệt. Sau khi rollback thì các thay đổi được update từ 10h30 ~ 23h30 cùng ngày DB của dev-server bị mất. Đây là bài học vô cùng sâu sắc với cá nhân cũng như tập thể Tapiru team.
Sau đó để xử lý triệt để vấn đề team đã có 1 task điều tra về việc giới hạn số job chạy tối đa trên digdag, và kết quả là:
- Cách 1: Thêm executor.attempt_max_run vào file config digdag(chi tiết) có tác dụng giới hạn số job chạy tối đa trên digdag.
- Cách 2: Thêm skip_delayed_by parameter vào code của từng dự án (chi tiết), cách này thì có tác dụng loại bỏ các job tự động phát sinh khi enable schedules.
Kết luận:
- Lỗi ở đây không hoàn toàn là do kỹ sư T, vì trong document của digdag mô tả phần này rất sơ sài. Việc enable schedule hoàn toàn không được nhắc đến việc có thể dẫn đến chạy lại tự động các job đã bị bỏ qua.
- Việc ngay lập tức thông báo với các bên liên quan về sự cố là vô cùng cần thiết.
- Bình tĩnh đối mặt với tình huống, luôn giữ một cái đầu lạnh.
- Khi sử dụng chức năng enable schedule hoặc nút resume trên digdag thì hãy chú ý kiểm tra job chạy gần nhất là lúc nào, nếu hơi lâu rồi chưa chạy thì hãy chạy lại 1 job có session gần nhất là ok.
Cảm ơn quý vị và các bạn đã quan tâm theo dõi. Chào tạm biệt và xin chân thành cảm ơn.
