Tìm hiểu Pandas (Bài 2): Cấu trúc dữ liệu của Pandas

I. Numpy
a. Giới thiệu NumPy
Có thể nói, kiến thức về NumPy ndarrays cực kì có ích, vì đó là nền tảng cơ bản đối với cấu trúc dữ liệu của pandas. Ngoài ra NumPy có thể thực thi việc vector hoá trên các mảng NumPy hay như các hoạt động lặp, duyệt mảng trên Python, nhưng nhanh hơn rất nhiều. NumPy là một thư viện quan trọng cho việc tính toán trên Python. Các thuộc tính cơ bản của NumPy bao gồm:
Kiểu mảng numpy.adarray đa chiều và đồng nhất
Có thể sử dụng một số lượng lớn các hàm toán học – Đại số tuyến tính, thống kê, …
Tương thích với cả C, C++ và Fortran
Chú ý: Cấu trúc dữ liệu cơ bản của NumPy là mảng (ndarray), là một mảng đa chiều đồng nhất, nó cũng được đánh chỉ mục (index) bằng số int như những mảng bình thường. Tuy nhiên numpy.ndarray thì hoàn toàn khác so với mảng array.array cơ bản của Python (mảng của python thì ít chức năng hơn)
b. Thao tác với NumPy
Khởi tạo
import numpy as np
# 1 dimensional array
ar1=np.array([0,1,2,3])
# 2D array
ar2=np.array ([[0,3,5],
[2,8,7]])Mảng của NumPy được đánh chỉ số từ 0, giống như các ngôn ngữ phổ biến như Python, java, C++, không giống như Fortran, Matlab và Octave, bắt đầu bằng 1.
NumPy thao tác trực tiếp trên mỗi phần tử của mảng với các toán tử +, -, *, /, **
ar=np.arange(0,7) # print [ 0, 1, 2, 3, 4, 5, 6] ar=np.arange(0,7) * 5 # print [ 0, 5, 10, 15, 20, 25, 30]
Ngoài ra ta còn có thể thao tác các toán tử logic, sắp xếp, thống kê trên NumPy, …
np.random.seed(100) arr=np.random.randint(1,10, size=(4,4)) # print [[9, 9, 4, 8], # [8, 1, 5, 3], # [6, 3, 3, 3], # [2, 1, 9, 5]] np.any((arr%7)==0) # print False arr.var(axis=0) # across rows # print [ 7.1875 10.75 5.1875 4.1875] arr.sort(axis=1) # print [[4 8 9 9] # [1 3 5 8] # [3 3 3 6] # [1 2 5 9]]
II. Pandas
Pandas. đã được Web McKinney xây dựng nên vào năm 2008, nguyên do là ông đã cảm thấy quá thất vọng khi làm việc với R. Pandas được xây dựng dựa trên các thuộc tính của NumPy và cung cấp các tính năng mà trên NumPy không có, và tất nhiên là pandas cũng cấp cấu trúc dữ liệu với ưu điểm nhanh và dễ sử dụng hơn, lấp đầy khoảng cách giữa hai ngôn ngữ thống kê là Python đối với R.
Cấu trúc dữ liệu cơ bản của Pandas bao gồm: Series, DataFrame, Panel
a. Series
Series là mảng một chiều giống như mảng Numpy, nhưng nó bao gồm thêm một bảng đánh label. Series có thể được khởi tạo thông qua NumPy, kiểu Dict hoặc các dữ liệu vô hướng bình thường
import calendar as cal
import numpy as np
import pandas as pd
# From NumPy
monthNames=[cal.month_name[i] for i in np.arange(1,6)]
months=pd.Series(np.arange(1,6),index=monthNames)
# print January 1
# February 2
# March 3
# April 4
# May 5
# dtype: int64
# From dictionary
currDict={'US' : 'dollar', 'UK' : 'pound',
'Germany': 'euro', 'Mexico':'peso',
'Nigeria':'naira',
'China':'yuan', 'Japan':'yen'}
currSeries=pd.Series(currDict)
# print US dollar
# UK pound
# Germany euro
# Mexico peso
# Nigeria naira
# China yuan
# Japan yen
# dtype: object
# From scalar values
dogSeries=pd.Series('chihuahua', index=['breed', 'countryOfOrigin', 'name', 'gender'])
# print breed chihuahua
# countryOfOrigin chihuahua
# name chihuahua
# gender chihuahua
# dtype: objectSeries có các thao tác gán, logic, tính toán với các biểu thức toán học hay thống kê bình thường như đã thao tác với NumPy.
b. DataFrame
DataFrame là mảng hai chiều được gán nhãn, nhưng không giống như NumPy, kiểu dữ liệu các cột là không đồng nhất, cấu trúc dữ liệu thì giống với NumPy nhưng có khả năng thay đổi. DataFrame gồm các thuộc tính như sau:
- Có khái niệm như một Table hoặc SpreadSheet dữ liệu
- Tương tự với mảng NumPy nhưng không phải là subclass của np.ndarray
- Các cột dữ liệu là các kiểu không đồng nhất: float64, int, bool, …
- Các cột của DataFrame là cấu trúc của Series
- Nó có thể xem như một kiểu dữ liệu Dict của một cấu trúc Series nhưng cả hai cột và hàng đều được đánh chỉ mục (index)
- Kích thước table có thể thay đổi: các cột có thể thêm hoặc xoá đi
Với mỗi chiều của Series/DataFrame được đánh chỉ mục, dù bất kể là mặc định hay không. Các chỉ mục là cần thiết cho việc tim kiếm hoặc để kết nối dữ liệu phù hợp trong pandas. Các trục cần được đặt tên, ví dụ như mảng của các tháng “month” bao gôm các giá trị [Jan, Feb, … Dec]. Đây là cách DataFrame biểu diễn các chỉ mục, tên cột và tên các cột chỉ mục với các kí tự V, W, X, Y, Z:
- DataFrame được khởi tạo thông qua nhiều cách khác nhau như
- Dict của mảng một chiều, list, dic hoặc cấu trúc Series
- Mảng NumPy hai chiều
- Cấu trúc hoặc các bản ghi của ndarray
- Cấu trúc Series
- Các DataFrame khác
Các nhãn của chỉ mục hay nhãn của cột có thể chỉ định theo dữ liệu, nếu không chỉ định thì sẽ được tựd động sinh ra
# DataFrame from Dict
stockSummaries={
'AMZN': pd.Series([346.15,0.59,459,0.52,589.8,158.88],
index=['Closing price','EPS',
'Shares Outstanding(M)',
'Beta', 'P/E','Market Cap(B)']),
'GOOG': pd.Series([1133.43,36.05,335.83,0.87,31.44,380.64],
index=['Closing price','EPS','Shares Outstanding(M)',
'Beta','P/E','Market Cap(B)']),
'FB': pd.Series([61.48,0.59,2450,104.93,150.92],
index=['Closing price','EPS','Shares Outstanding(M)',
'P/E', 'Market Cap(B)']),
'YHOO': pd.Series([34.90,1.27,1010,27.48,0.66,35.36],
index=['Closing price','EPS','Shares Outstanding(M)',
'P/E','Beta', 'Market Cap(B)']),
'TWTR':pd.Series([65.25,-0.3,555.2,36.23],
index=['Closing price','EPS','Shares Outstanding(M)',
'Market Cap(B)']),
'AAPL':pd.Series([501.53,40.32,892.45,12.44,447.59,0.84],
index=['Closing price','EPS','Shares Outstanding(M)','P/E',
'Market Cap(B)','Beta'])}
stockDF=pd.DataFrame(stockSummaries)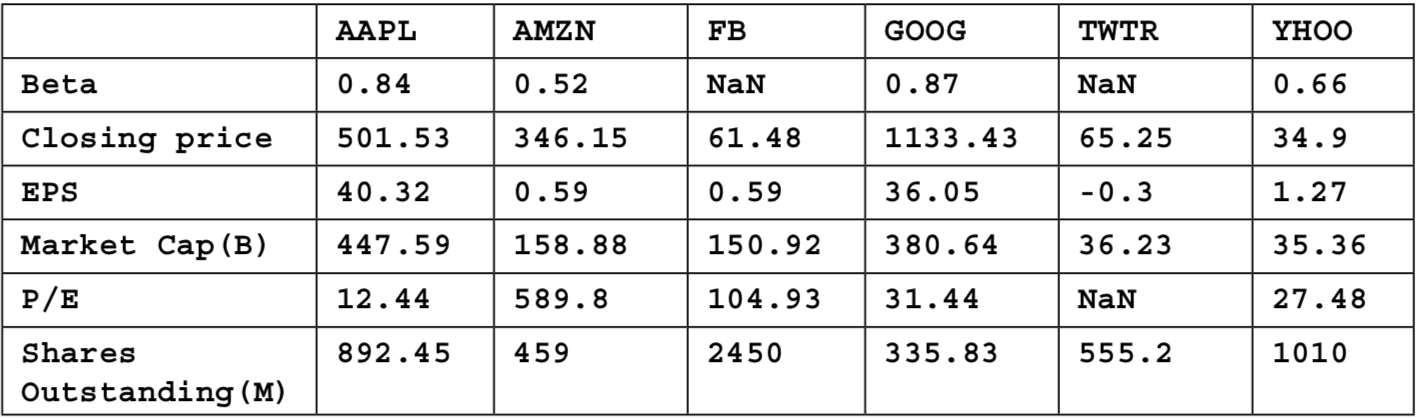
Ta có thể dễ dàng lấy ra các cột giá trị
stockDF['FB'] # print Beta NaN # Closing price 61.48 # EPS 0.59 # Market Cap(B) 150.92 # P/E 104.93 # Shares Outstanding(M) 2450.00 # Name: FB, dtype: float64
Thêm cột mới bằng cách gán
stockDF['NAP'] = 1992 # print # AMZN GOOG FB ... TWTR AAPL NAP # Beta 0.52 0.87 NaN ... NaN 0.84 1992 # Closing price 346.15 1133.43 61.48 ... 65.25 501.53 1992 # EPS 0.59 36.05 0.59 ... -0.30 40.32 1992 # Market Cap(B) 158.88 380.64 150.92 ... 36.23 447.59 1992 # P/E 589.80 31.44 104.93 ... NaN 12.44 1992 # Shares Outstanding(M) 459.00 335.83 2450.00 ... 555.20 892.45 1992
Ta cũng có thể sử dụng các toán tử để thao tác lên dữ liệu như:
np.abs(stockDF.replace(np.nan,0)) # print # AMZN GOOG FB ... TWTR AAPL NAP # Beta 0.52 0.87 0.00 ... 0.00 0.84 1992.0 # Closing price 346.15 1133.43 61.48 ... 65.25 501.53 1992.0 # EPS 0.59 36.05 0.59 ... 0.30 40.32 1992.0 # Market Cap(B) 158.88 380.64 150.92 ... 36.23 447.59 1992.0 # P/E 589.80 31.44 104.93 ... 0.00 12.44 1992.0 # Shares Outstanding(M) 459.00 335.83 2450.00 ... 555.20 892.45 1992.0
c. Panel
Panel là mảng 3 chiều. Panel thì không được sử dụng rãi như như Series hay DataFrame và nó cũng không dễ hiển thị hay trừu tượng hoá như màn một chiều và hai chiều. Cấu trúc của Panel:
- items: Đây là axis 0. Mỗi phần tử thì tương ứng với DataFrame.
- major_axis: Đây là axis 1. Mỗi phần tử tương ứng với một hàng của DataFrame
- minor_axis: Đây là axis 2. Mỗi phần tử tương ứng với một cột của DataFrame
# Panel from NumPy
stockData=np.array([[[63.03,61.48,75],
[62.05,62.75,46],
[62.74,62.19,53]],
[[411.90, 404.38, 2.9],
[405.45, 405.91, 2.6],
[403.15, 404.42, 2.4]]])
stockHistoricalPrices = pd.Panel(stockData,
items=['FB', 'NFLX'],
major_axis=pd.date_range('2/3/2014',
periods=3),
minor_axis=['open price', 'closing price', 'volume'])Ngoài ra vẫn có thể tạo Panel từ Dict của các DataFrame hay từ chính các DataFrame
III. Kết luận
Có thể thấy rằng NumPy là một cấu trúc dữ liệu nền tảng cho cấu trúc dữ liệu của Pandas. Pandas cá cấu trúc bao gồm mảng NumPy và các mảng được gán nhãn. Pandas gồm 3 cấu trúc chính là Series là các mảng một chiều, DataFrame là mảng hai chiều, và Panel là 3 chiều. Có thể nhận thấy DataFrame được sử dụng nhiều nhất do tính tương đồng với cấu trúc Table và SpreadSheet. Nhưng ở chương này không quá đi sâu vào việc thao tác với dữ liệu mà chỉ dừng lại ở mức khởi tạo để người đọc có cái nhìn so sánh tổng quan. Nhưng có thể nói Pandas và NumPy là các công cụ rất mạnh để thao tác và xử lý dữ liệu như tính toán, thống kê.

Tìm hiểu Pandas (Bài 4): Các vấn đề liên quan đến mất mát dữ liệu, xử lý chuỗi thời gian và mô hình hoá dữ liệu
Tìm hiểu Pandas (Bài 1): Giới thiệu chung
