Pandas trong Python (Bài 1): Giới thiệu chung
Python được biết đến như là một ngôn ngữ lập trình được sử dụng đông đảo bởi các lập trình viên cũng như sự đa dạng về lĩnh vực mà nó được áp dụng.
Trong nội dung bài viết hôm nay mình xin đề cập đến lĩnh vực Data Science(khoa học dữ liệu) mà cụ thể là về Pandas, một thư viện được sử dụng rất rộng rãi trong Data Science.
Pandas là gì?
Pandas là một thư viện mã nguồn mở được phát triển bởi Wes McKinney vào năm 2008. Pandas được sử dụng chủ yếu để thao tác, phân tích và dọn dẹp dữ liệu. Pandas cung cấp rất nhiều cấu trúc dữ liệu cũng như các phép tính hỗ trợ thao tác dữ liệu số và dữ liệu thời gian(time series). Pandas nhanh, mạnh và hiệu quả.
Ưu điểm của Pandas
- Nhanh và hiệu quả trong thao tác và phân tích dữ liệu.
- Có thể lấy dữ liệu từ nhiều nguồn dữ liệu khác nhau.
- Dễ dàng xử lí các dữ liệu bị thiếu(đại diện bởi : NaN).
- Kích thước linh hoạt: có thể dễ dàng insert và delete dữ liệu.
- Linh hoạt trong việc reshape và pivot dataset.
- Cung cấp các chức năng time-series cũng như các chức năng nhóm dữ liệu(group).
Bắt đầu với Pandas
Để có thể sử dụng thư viện Pandas, sau khi cài đặt trong hệ thống, bạn cần phải import thư viện trong text editor hoặc IDE để có thể sử dụng. Câu lệnh import như sau:
import pandas as pd
Trong đó pd có thể được hiểu là alias của Pandas. Sau khi import xong có thể sử dụng pd để gọi các phương thức của thư viện.
Thông thường Pandas cung cấp 2 cấu trúc dữ liệu chính để thao tác với dữ liệu là: Series và DataFrame.
Chúng ta sẽ lần lượt tìm hiểu về 2 cấu trúc này.
Series
Pandas Series là mảng một chiều được gắn label mà có thể lưu trữ bất kì kiểu dữ liệu nào(integer, string, float…) Có thể hiểu đơn giản Pandas Series giống như là 1 cột trong excel. Mỗi giá trị sẽ có một label trỏ đến chỉ mục(index) của nó, bạn có thể đặt tên cho label với đối số index. Sử dụng label để có thể truy cập đến một giá trị cụ thể

(Ảnh minh hoạ 1 series – nguồn: GeeksforGeeks)
Pandas cung cấp nhiều các phép toán để có thể thao tác với Series như: tạo mới, truy cập phần tử, các phép tính nhị phân… Tuy nhiên trong bài viết hôm nay, để nội dung không quá dài mình xin giới thiệu phép toán cơ bản nhất để đó chính là tạo một Series
Cách tạo một Series
Trong thực tế, một Pandas Series sẽ được tạo ra bằng cách lấy dữ liệu từ các kho lưu trữ dữ liệu, đó có thể là SQL Database, file CSV, file Excel…
Có nhiều cách để tạo ra một Pandas Series như là tạo từ: Lists, Dictionary hoặc thậm chí là một scalar(một giá trị đơn)… Dưới đây sẽ là một vài cách đơn giản để tạo ra một Series:
Tạo Series từ array:
Chúng ta sẽ import module numpy và sử dụng phương thức array() để tạo
import pandas as pd import numpy as np data = np.array(['f','l','i','n','t','e','r','s']) series = pd.Series(data) print(series)
Output:

Tạo series từ 1 Lists:
Để tạo 1 Series từ list thì cần phải tạo 1 list trước đó.
import pandas as pd list = ['f','l','i','n','t','e','r','s'] series = pd.Series(list) print(list)
Output:
![]()
![]()
DataFrame
Pandas DataFrame là cấu trúc dữ liệu bảng không đồng nhất, có 2 chiều và kích thước có thể thay đổi. DataFrame cũng có các labels tương ứng với các hàng và cột. Nói một cách đơn giản thì DataFrame cũng giống như 1 bảng SQL hoặc 1 spreadsheet vậy. Pandas DataFrame bao gồm 3 thành phần chính là : data, rows và columns.
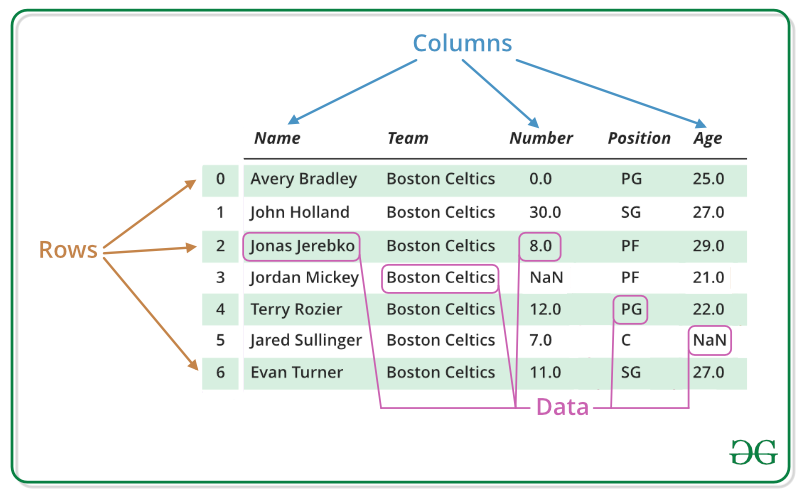
(Ảnh minh hoạ 1 dataframe – nguồn: GeeksforGeeks)
Cách tạo một DataFrame:
Cũng giống như Series, một Pandas DataFrame cũng có thể được tạo bằng cách lấy dữ liệu từ các kho dữ liệu như SQL Database, CSV file, Excel file. DataFrame cũng chấp nhận nhiều kiểu input như là : list, dictionary, một list các dictionary…
Mình xin giới thiệu một số cách tạo 1 DataFrame đơn giản:
Tạo DataFrame từ List:
Có thể sử dụng 1 list hoặc 1 list các list để làm đối số truyền vào.
import pandas as pd lst = ['Hello','Flinters','How','Are','You'] df = pd.DataFrame(lst) print(df)
Output:

Tạo từ một dictionary:
Ở đây mình sẽ truyền vào một dict các lists. Độ dài của các list cần phải giống nhau. Nếu index được truyền vào thì nó cũng phải tương ứng với độ dài của list. Còn nếu không được truyền thì kết quả sẽ mặc định lấy index theo độ dài của list.
import pandas as pd
dic = {
"one": [1,2,3,4,5],
"two": [5,4,3,2,1]
}
df = pd.DataFrame(dic, index=["a","b","c","d","e"])
print(df)Output:

Tạo từ một Numpy Arrays:
Mình sẽ truyền vào một Numpy Array tương tự như cách tạo một DataFrame với một List
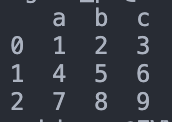
import pandas as pd import numpy as np arr = np.array([[1,2,3], [4,5,6], [7,8,9]]) df = pd.DataFrame(arr, columns = ['a','b','c']) print(df)
Output:
Tổng kết
Pandas là một thư viện Python rất thông dụng và được sử dụng rỗng rãi trong Khoa học máy tính đặc biệt là để phân tích, thao tác với dữ liệu
Qua bài viết này mình đã giới thiệu sơ qua về về khái niệm Pandas trong Python cũng như các cấu trúc dữ liệu thông dụng và cách tạo ra chúng. Để tìm hiểu sâu và chi tiết hơn thì mọi người có thể truy cập trang chủ: https://pandas.pydata.org/pandas-docs/stable/index.html cũng như các blog công nghệ. Ở các bài viết sau mình sẽ chi tiết hơn về các cách thao tác với từng cấu trúc dữ liệu của Pandas. Hi vọng mọi người thích bài viết và đóng góp ý kiến cũng như phản hồi để mình có động lực viết thêm các bài blog khác.
Xin cảm ơn!

Tìm hiểu Pandas (Bài 4): Các vấn đề liên quan đến mất mát dữ liệu, xử lý chuỗi thời gian và mô hình hoá dữ liệu

Kỹ thuật Python mà bạn nên biết: Currying
