Data Analysis with Pandas and Python 1 – Intro, Jupyter Notebook, and pd Series
Giới thiệu
Hiện nay, khi Việt Nam đang dần hoà nhập với thế giới về công nghệ và tiến tới mục tiêu gọi là “Thời đại 4.0”, số lượng người sử dụng công nghệ hiện đại hàng ngày như là internet, smartphone hay các sản phẩm của công nghệ như là Zalo, Facebook ngày càng nhiều hơn. Trong khi đó, các thiết bị công nghệ ngày càng khó trở nên đột phá hơn về mặt kĩ thuật, dẫn đến đất diễn của thế giới ảo trở nên rộng mở hơn bao giờ hết. Một trong những khái niệm lên ngôi trong những năm gần đây đó là Big Data. Big Data, dịch ra tiếng Việt là dữ liệu lớn, dùng để ám chỉ lượng dữ liệu rất dồi dào đến từ các người dùng trong thế giới ảo. Các dữ liệu này được thu thập trực tiếp từ người dùng nên độ chính xác cao, tấn suất vô cùng thường xuyên, độ lớn cũng khủng khiếp, khiến cho các cách phân tích dữ liệu truyền thống bằng cơm ngày xưa trở nên chậm chạp và lỗi thời.
Vì thế, phất lên nhiều diều gặp gió cùng Big Data đó chính là Data Analysis. Nếu dịch đơn thuần, Data Analysis nghĩa là phân tích dữ liệu. Tuy nhiên, trên thực tế thì data analysis bao gồm việc rà soát, xử lí, biến hoá, và mô hình hoá dữ liệu để tìm thông tin hữu ích, nhằm phục vụ cho việc đưa ra kết luận và quyết định. Nói về data analysis, một số tools trứ danh liên quan đến lĩnh vực này gồm có R, Matlab hoặc “nhà giàu mới nổi” Python.
- Matlab: đây là một phần mềm thương mại, được dùng chủ yếu trong phân tích số liệu và các xử lí liên quan đến toán học, ma trận
- R: có bản miễn phí, thường dùng trong lĩnh vực thống kê
- Python: ngôn ngữ lập trình dạng opensource (mã nguồn mở), có nhiều thư viện dùng cho đa dạng mục đích liên quan đến dữ liệu như numpy, pandas, scipy…
Như vậy có thể thấy, với một background là dân phát triển phần mềm thì Python là một lựa chọn vô cùng hợp lí để chúng ta bắt đầu bước chân vào con đường data analysis. Vậy nên, chào mừng mọi người đến với series “Data Analysis cùng Pandas và Python”
Cài đặt
Trong series này, mình sẽ sử dụng Anaconda, cụ thể trong đó là công cụ Jupyter Notebook để nghiên cứu về data analysis.
Để cài đặt Anaconda có rất nhiều hướng dẫn nên mình sẽ bỏ qua phần này để các bạn tự cài đặt theo mong muốn của bản thân. Dưới đây là một số link hướng dẫn cài đặt để các bạn tham khảo:
- MacOS: https://docs.anaconda.com/anaconda/install/mac-os/
- Windows: https://docs.anaconda.com/anaconda/install/windows/
- Linux: https://docs.anaconda.com/anaconda/install/linux/
Sau khi cài đặt xong, chúng ta sẽ sử dụng Terminal (trên MacOS) hoặc Anaconda Prompt (Windows) để tạo virtual environment. Về virtual environment, đây là một khái niệm của Python và nằm ngoài phạm vi của series này nên các bạn có thể đọc thêm về khái niệm này ở https://docs.python.org/3/tutorial/venv.html. Nói nôm na về virtual environment, chúng ta sẽ tạo một môi trường mới nhằm cài đặt các libraries và packages liên quan đến pandas trên môi trường này.
Kiểm tra xem Anaconda cài được chưa
(base) EVN18014-XuanMTT:~ xuan_mtt$ conda --version
conda 4.9.2Tạo virtual environment mới. Khi được hỏi Process (y/n) thì chọn y
(base) EVN18014-XuanMTT:~ xuan_mtt$ conda create --name pandas_playground
Collecting package metadata (current_repodata.json): done
Solving environment: done
## Package Plan ##
environment location: /Users/xuan_mtt/opt/anaconda3/envs/pandas_playground
Proceed ([y]/n)? y
Preparing transaction: done
Verifying transaction: done
Executing transaction: done
#
# To activate this environment, use
#
# $ conda activate pandas_playground
#
# To deactivate an active environment, use
#
# $ conda deactivateXem các virtual environment đang có. Virtual environment đang được kích hoạt sẽ có dấu (*)
(base) EVN18014-XuanMTT:~ xuan_mtt$ conda info --envs
# conda environments:
#
base * /Users/xuan_mtt/opt/anaconda3
pandas_playground /Users/xuan_mtt/opt/anaconda3/envs/pandas_playgroundChuyển sang virtual environment mới tạo và kiểm tra xem đã activate virtual environment mới thành công chưa
(base) EVN18014-XuanMTT:~ xuan_mtt$ conda activate pandas_playground
(pandas_playground) EVN18014-XuanMTT:~ xuan_mtt$ conda info --envs
# conda environments:
#
base /Users/xuan_mtt/opt/anaconda3
pandas_playground * /Users/xuan_mtt/opt/anaconda3/envs/pandas_playgroundSau khi đã activate virtual environment, cài đặt một số packages sẽ sử dụng trong series trong môi trường pandas_playground. Khi được hỏi Process (y/n) thì chọn y. Mặc dù chúng ta chỉ cài đặt 5 packages nhưng conda sẽ tự động cài thêm nhiều packages và dependencies khác nên ở phần này output khá dài và mình sẽ không show hết ở dưới.
(pandas_playground) EVN18014-XuanMTT:~ xuan_mtt$ conda install pandas jupyter bottleneck numexpr matplotlib
...
Preparing transaction: done
Verifying transaction: done
Executing transaction: doneKhi đã cài đặt xong các packages, chạy Jupyter Notebook
(pandas_playground) EVN18014-XuanMTT:~ xuan_mtt$ jupyter notebook
[I 21:16:22.393 NotebookApp] Writing notebook server cookie secret to /Users/xuan_mtt/Library/Jupyter/runtime/notebook_cookie_secret
[I 21:16:23.042 NotebookApp] Serving notebooks from local directory: /Users/xuan_mtt
[I 21:16:23.042 NotebookApp] Jupyter Notebook 6.2.0 is running at:
[I 21:16:23.042 NotebookApp] http://localhost:8888/?token=6dcb8f423ae8849fce945c7a70dc8d8b581699380745f505
[I 21:16:23.042 NotebookApp] or http://127.0.0.1:8888/?token=6dcb8f423ae8849fce945c7a70dc8d8b581699380745f505
[I 21:16:23.042 NotebookApp] Use Control-C to stop this server and shut down all kernels (twice to skip confirmation).
[C 21:16:23.051 NotebookApp]
To access the notebook, open this file in a browser:
file:///Users/xuan_mtt/Library/Jupyter/runtime/nbserver-75901-open.html
Or copy and paste one of these URLs:
http://localhost:8888/?token=6dcb8f423ae8849fce945c7a70dc8d8b581699380745f505
or http://127.0.0.1:8888/?token=6dcb8f423ae8849fce945c7a70dc8d8b581699380745f505Lúc này, một tab browser sẽ được mở ra. Đây chính là Jupyter Notebook đã được khởi động. Bản chất của Jupyter Notebook là một web app và trong trường hợp default này, Jupyter Notebook được chạy ở port 8888. Nếu trên máy các bạn mà port đó đã bị sử dụng thì… mình cũng chưa tìm hiểu xem nó sẽ thế nào nữa. Nếu ai gặp thì để lại comment giúp mình nha.
Đến lúc này mình đã có thể bắt đầu sử dụng Jupyter Notebook rồi.
Jupyter Notebook
Bên dưới là màn hình mở đầu của Jupyter Notebook. Lưu ý là vị trí folder mở đầu của các bạn có thể khác của mình, tuỳ theo config của từng người. Chúng ta có thể thấy được ở giao diện chính, cấu trúc của các folder giống như trong Finder (MacOS) và Explorer (Windows).

Để tạo một file notebook mới, bên tay trái chọn New > Python 3
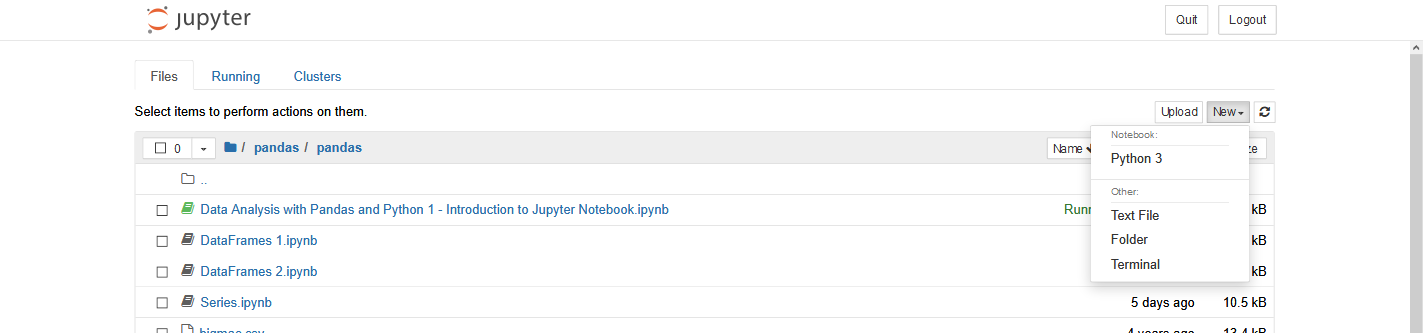
Và bây giờ chúng ta đã ở giao diện 1 notebook mới. Mình xin giới thiệu một vài mục thường dùng tại giao diện

- Tên của notebook. Khi click vào thì các bạn có thể đổi tên cho notebook. Khi notebook được save lại thì nó sẽ sử dụng tên mà các bạn đặt để save trên ổ đĩa.
- Gọi là Cell. Cell là nơi chúng ta sẽ gõ code và chạy trực tiếp code.
- Định dạng của Cell. Một Cell có thể dùng để gõ code, markdown, HTML…
Bây giờ mình sẽ test thử xem notebook có chạy không. Như trong hình, ở Cell 1 mình thử print ra chữ “HelloWorld”. Để chạy code của Cell thì sau khi gõ xong, các bạn có thể ấn Shift + Enter hoặc click vào nút Run ở trên. Tương tự Cell 2 mình thử phép + thì có thấy output của nó ngay bên dưới. Ngoài ra, mình cũng đổi tên notebook cho xịn xò một chút.

Còn khi đổi định dạng của Cell sang markdown chẳng hạn, mình có thể gõ markdown trực tiếp trên notebook luôn

Về cơ bản thì đó là những gì chúng ta cần biết về Jupyter Notebook. Trong quá trình sử dụng Jupyter Notebook, nếu có tính năng nào mới thì mình sẽ giới thiệu sau. Hoặc nếu bạn nào biết tính năng gì hay ho của Jupyter Notebook thì cũng để lại comment nha.
Hotkeys
Trong Jupyter Notebook có một số hotkeys/shortcuts khá tiện lợi để chúng ta dùng khi ở Command Mode (ấn Esc để vào Command Mode). Ở đây, mình sẽ list 1 số hotkeys mà mình thấy có ích cho mọi người tham khảo. Các bạn lưu ý là tất cả hotkeys đều có thể tìm thấy dưới dạng options trên Menu, thế nên nếu có quên thì chỉ cần tìm trên Menu cũng thấy nha.
- a: Thêm Cell ở trên Cell hiện tại (viết tắt của above)
- b: Thêm Cell ở dưới Cell hiện tại
- dd: Xoá Cell hiện tại
- x: Cut Cell
- c: Copy Cell
- Shift + v: Paste Cell ở trên Cell hiện tại
- v: Paste Cell ở dưới Cell hiện tại
- h: Hiển thị Help menu
Pandas
Khi nói về data analysis cùng Python thì pandas chắc chắn là cái tên không thể thiếu. pandas là một thư viện của Python, cung cấp nhiều tính năng liên quan đến chuyển hoá và phân tích dữ liệu. Để import pandas vào trong code, chạy câu lệnh sau:
import pandas as pdỞ đây, sau khi chạy Cell này thì sẽ không có output vì nó đơn giản chỉ là một câu import. Lưu ý một chút là pd là naming convention khi import pandas vào trong code, các bạn có thể đặt tên khác nếu thích nhưng mình sẽ follow convention để mọi người dễ hiểu. Để check xem pandas đã được import chưa:
pdSeries
(Reference: https://pandas.pydata.org/pandas-docs/stable/reference/api/pandas.Series.html)Series trong khái niệm pandas là one-dimensional array, tức là mảng một chiều, hay hiểu đơn thuần chính là một mảng. Nếu hình dung dữ liệu là một cái bảng có nhiều cột (columns) nhiều dòng (rows) thì Series là một cột (column) của bảng.
Chúng ta sẽ bắt đầu tìm hiểu về Series bằng cách sử dụng nó nhé:
import pandas as pd
# This is a List in Python
fruits = ["Banana", "Apple", "Watermelon", "Mango", "Orange"]
pd.Series(fruits)
Ở ví dụ trên, từ một List của String thì chúng ta đã có một Series mà trong Series này thì pd đã tự cho index cho từng giá trị của mình. Lưu ý: Series có giá trị là String sẽ được xác định dtype (tức data type) là object. Với các loại giá trị khác thì dtype sẽ thay đổi.
# Already import pandas, I can skip import here
ages = [18, 21, 25, 30, 46, 51]
pd.Series(ages)
finished = [True, True, False, False, True]
pd.Series(finished)
Ở trên chúng ta có thể thấy dtype là int64 đối với các số nguyên và bool đối với giá trị Boolean.
Đối với List thì chúng ta có thể dễ dàng hình dung cách Series xử lí. Vậy còn đối với dict (tức dictionary) thì sao?
# This is a Dictionary in Python
me = {"Name": "Xuan Mai",
"Slack": "xuan_mtt",
"Team": "DataGo"}
pd.Series(me)
Như vậy, khác với List là pandas tự gán index khi chúng ta convert List thành Series, pandas đã sử dụng key của dictionary làm index trong Series. Đến lúc này, chúng ta có thể thấy Series và Dict khá là giống nhau, còn có index/key và values tương ứng với index/key. Vậy thì sự khác biệt ở đâu? Sự khác biệt lớn nhất đó chính là index trong Series không cần unique, tức là các index có thể lặp lại. Còn đối với Dict thì key phải là unique.
Đến đây, có thể một số bạn sẽ thắc mắc rằng làm thế nào để chỉ định index cho Series của một List. Nếu là một Dict thì dễ quá rồi, chính là key của nó. List thì được cho index sẵn nhưng nếu chúng ta muốn chỉ định thì sao? Đừng lo, mọi chuyện đã nằm trong tính toán của pandas.
Khi chúng ta chỉ định List để convert sang Series, bản thân constructor của Series có rất nhiều parameter. Để xem được các parameter khả thi, sau khi gõ ( thì các bạn ấn Shift + Tab để hiển thị docstring của constructor.

Có thể thấy được Series trong pandas có nhiều pamaraters khác nhau. Khi chúng ta gõ pd.Series([1,2,3,4]) thì List của mình đang được hiểu là argument cho parameter đầu tiên, tức là data. Mặc định trong Python và nhiều ngôn ngữ lập trình khác là khi chúng ta không chỉ định tên parameter thì argument chúng ta truyền vào chính là dành cho parameter đầu tiên. Hai dòng code sau có ý nghĩa giống hệt nhau:
pd.Series([1,2,3,4])
pd.Series(data=[1,2,3,4])Quay lại câu hỏi về việc chỉ định index khi convert List thành Series thì dựa trên docstring mà chúng ta nhìn thấy khi Shift + Tab, parameter index chính là dùng để chỉ định index trong Series. Thử nghiệm nào
# Already imported pandas
names = ["Jack", "Adam", "Jessica", "Luke", "Brian"]
colors = ["Red", "Blue", "Yellow", "Pink", "Black"]
pd.Series(data=colors)
# Already imported pandas
names = ["Jack", "Adam", "Jessica", "Luke", "Brian"]
colors = ["Red", "Blue", "Yellow", "Pink", "Black"]
pd.Series(data=colors, index=names)
Sau khi chỉ định parameter index thì chúng ta có thể thấy rằng index trong Series đã từ 0,1,2… mà biến thành argument names được truyền vào. Như vậy là câu hỏi ban đầu của chúng ta đã được giải quyết. Và trong câu hỏi này, mình có nói đến constructor. Nếu các bạn có quên thì constructor là một method dùng để initialize hay còn gọi là khởi tạo một object. Nhân tiện nói về methods, tiếp theo mình sẽ giới thiệu về một số attributes cũng như methods của Series.
Attributes
Attributes của Series cung cấp cho chúng ta một số thông tin về Series. Attributes sẽ không làm thay đổi nội dung hay cấu trúc của Series mà chỉ đơn giản là cung cấp thông tin cho chúng ta. Series có nhiều attributes và các bạn có thể xem cụ thể danh sách ở link Reference ở trên. Ở phần này, mình sẽ giới thiệu một số attributes hữu ích của Series.
Đầu tiên, mình sẽ tạo một Series từ một List của String:
# Already imported pandas above
weekdays = ["Monday", "Tuesday", "Wednesday", "Thursday", "Friday"]
# Assign Series to a variable called "s" - horrible var name, don't do it in real life
s = pd.Series(weekdays)
s
Sau đó, mình sẽ xem một số attributes của Series s này. Lưu ý là attributes không cần parenthesis () nha.
# Display all values in Series as an array and its dtype
s.values
# Display index information (as an object called RangegIndex) of the Series
# Index starts at 0 and stops at 5 (not including 5), and the index increases by 1 every time
s.index
# dtype of O means object
s.dtype
# How big, or the size of the Series
s.size
Vậy là với một số attributes này, chúng ta có thể biết được thông tin cơ bản của Series. Tiếp đến, chúng ta sẽ xem xét tới các methods của Series nhé.
Methods
Khác với Attributes, Methods của Series cho phép chúng ta thay đổi và biến hoá dữ liệu trong Series. Series gồm rất rất nhiều Methods (xem thêm ở link Reference) nên mình chỉ điểm qua một số methods dễ hiểu của Series. Khi chúng ta sử dụng Series nhiều hơn thì chúng ta sẽ tiếp cận được rất nhiều methods phức tạp nữa.
Như thường lệ, mình sẽ tạo một Series và lần này sẽ là người chơi hệ số thập phân nha. À ngược lại với Attributes thì Methods sẽ cần parenthesis ().
bonus = [5.25, 3.94, 7.30, 12.76]
s = pd.Series(bonus)
s
# Add all values
s.sum()
# Multiply all values
s.product()
# Average of all values
s.mean()
# Return first value in the Series
s.head(1)
# Return last value in the Series
s.tail(1)
Có thể thấy rằng, Attributes chỉ trả về thông tin của Series còn Methods lại thực hiện chuyển hoá dữ liệu trong Series. Ở trên là một số methods có thể sử dụng với values có dtype là float64. Có lẽ đến đây thì các bạn cũng đã có cái nhìn sơ bộ về Series rồi. Để tăng thêm độ khó cho game thì tiếp theo mình bắt đầu áp dụng Series trên dataset thật.
Dataset 1: DotA 2 Heroes Name
- Download dataset 1 here
Ngoài lề chút, mình là một fan cứng của DotA. Dành cho những ai không biết thì đây là một trò chơi chiến thuật đối kháng theo team dạng kiểu Liên Minh Huyền Thoại hay Liên Quân. Trong DotA 2, có rất nhiều nhân vật mà người chơi có thể lựa chọn. Thế nên mình quyết định sử dụng tên của các nhân vật trong DotA 2 làm dataset cho lần này.
Về dataset này, file có định dạng .csv. CSV, viết tắt của comma-separated value, là định dạng rất phổ biến khi nói về data ở nhiều ngành nghề khác nhau. Bản chất của CSV chỉ là file text thông thường nhưng dữ liệu được phân chia bởi các dấu phẩy. Ở Flinter, CSV cũng rất phổ biến và được bắt gặp ở nhiều dự án khác nhau.
Okay, sau khi đã download xong dataset 1, các bạn nhớ save nó cùng chỗ với cái file notebook mà chúng ta sử dụng. Việc này sẽ giúp việc import file dễ dàng hơn. Việc trước tiên là mình cần đọc cái dataset này.
# dota2_heroes.csv is in the same folder as the notebook
pd.read_csv("dota2_heroes.csv")
Trong dataset này, chúng ta có tận hai cột (columns) dữ liệu. Tuy nhiên, Series chỉ là one-dimensional array, tức mảng một chiều nên Series sẽ không thể “nuốt” được file csv này. Tất nhiên pandas đã tính trước và có dành cho chúng ta một số parameter hữu ích nhằm chọn một cột (column) để convert sang Series.
(read_csv documentation: https://pandas.pydata.org/pandas-docs/stable/reference/api/pandas.read_csv.html)Để đọc cụ thể hơn về các parameter thì các bạn tham khảo ở link documentation phía trên. Còn để chọn một cột và convert sang Series thì chúng ta sẽ sử dụng hai parameters là usecols và squeeze)
# usecols = column we want to select as values
# squeeze = convert the return value to Series
pd.read_csv("dota2_heroes.csv", usecols = ["Name"], squeeze=True)
Vậy là mình đã có một Series là cột Name trong dataset của mình. Có thể các bạn đã để ý thấy output của read_csv đầu tiên và read_csv thứ hai khác nhau thì các bạn đã nhìn đúng, ở lần read_csv đầu tiên thì dữ liệu trả về là dạng DataFrame. DataFrame cũng tương tự như Series nhưng phức tạp hơn nhiều và sẽ được giới thiệu sau. Còn lần read_csv thứ hai có trả về Series nên output nhìn rất quen thuộc.
Bây giờ, hãy xem các values đầu tiên và cuối cùng của dataset này nhé
# Assign to variable for further usage
dota2 = pd.read_csv("dota2_heroes.csv", usecols = ["Name"], squeeze=True)
# On default, head returns first 5 values in Series
dota2.head()
# On default, tail also returns last 5 values in Series
dota2.tail()
Chúng ta có thể sử dụng một số built-in functions trong Python để lấy thêm thông tin về Series này.
# Return the length of the Series
len(dota2)
# Type of this Series - obviously it has a type of Series
type(dota2)
# Sort the value alphabetically
sorted(dota2)
# Return the value that has a maximum numeric value
max(dota2)
# Return the value that has a minimum numeric value
min(dota2)
Hoặc xem thêm một số Attributes của Series
# True if no values is duplicated
dota2.is_unique
# Return rows and columns - of course no columns so empty value
dota2.shape
# Return name of the Series
dota2.name
Tiếp đến, chúng ta có thể sử dụng một số methods để thay đổi dataset dota2 này. Có một lưu ý là nhiều methods sẽ trả về một Series mới mà ở đó, method chúng ta gọi đã được áp dụng vào đó. Methods nào có trả về giá trị thì chúng ta có thể sử dụng Shift + Tab hoặc xem documentation của method. Vì thế, đừng quên gán variable cho giá trị trả về nha.
# Sort values in Series - our Series is already sorted
in_order = dota2.sort_values()
in_order
# Sort values in Series descending
in_order = dota2.sort_values(ascending=False)
in_order
in_order.head()# Does original `dota2` change?
dota2
Ở đây chúng ta thấy được những methods đã không thay đổi variable dota2 gốc của mình. Tuy nhiên, nếu các bạn muốn các methods được thực thi ngay trên variable gốc thay vì trả về thì các bạn có thể sử dụng parameter inplace.
# Sort values descendingly and in place
dota2.sort_values(ascending=False, inplace=True)
dota2
Lúc này dota2 đã bị thay đổi trực tiếp. Chúng ta có thể lấy lại thứ tự ban đầu bằng 1 tip-trick là đi sort theo index.
# Sort index and in place
dota2.sort_index(ascending=True, inplace=True)
dota2
Chúng ta có thể check xem 1 value có trong Series không bằng cách này
"Drow Ranger" in dota2.valuesTrong trường hợp chúng ta check trong dota2 thì giá trị sẽ được tìm trong index của dota2
"Anti-Mage" in dota23 in dota23 in dota2.indexĐể lấy value ở một index cụ thể trong Series, về hình thức sẽ tương tự với lấy giá trị theo index trong List.
# Get value at index 4
dota2[4]
'Arc Warden'
# Get value at index 117
dota2[117]
# Get values from index 12, 14, 15, 17
dota2[[12, 14, 15, 17]]
type(dota2[[12, 14, 15, 17]])# Get values in range of index
dota2[10:15]
Khi index của Series là số thì cách thức lấy khá rõ ràng. Nhưng ngay cả khi Series có index là String thì mình cũng có thể lấy được giá trị theo String. Để xem thử ví dụ này, chúng ta sẽ cần đọc lại file csv và chỉ định giá trị của index bằng parameter index_col. Lưu ý là parameter này khác với parameter usecols ở chỗ usecols là chỉ định giá trị của values, còn index_col là chỉ định giá trị index.
# index_col = column we want to select as index
# squeeze = convert the return value to Series
dota2 = pd.read_csv("dota2_heroes.csv", index_col = ["Name"], squeeze=True)
dota2
Sau khi đã chỉ định giá trị của index thì cột còn lại trong file csv tự động biến thành giá trị của values luôn. Bây giờ chúng ta hãy lấy giá trị bằng label (tức String trong index)
# Get value by index
dota2[26]
# Get value has label "Hoodwink"
dota2["Hoodwink"]
# Get value has label "Mars"
dota2["Mars"]
# Get values using multiple label
dota2[["Invoker", "Medusa", "Bane"]]
# Get values in range of label
dota2["Mirana":"Phoenix"]
Cách dùng value1:value2 thường được gọi là slice. Khi slice thì chúng ta còn có thể chỉ định step, tức là độ lớn từng bước của mình.
# Get values in range of label with step of 3
dota2["Rubick":"Tiny":3]
dota2["Rubik":"Tiny"]Nếu chẳng may các bạn có gõ nhầm label hay chọn 1 index không tồn tại thì lỗi sẽ được trả về. Điều đó cũng rất hữu ích, nhưng mình sẽ thử gán cái giá trị trả về của việc label không tồn tại, ở đây mình sẽ dùng reindex và xem xem chúng ta có kết quả gì nha
dota2[["Abaddon","Pikachu"]]dota2.reindex(index=["Abaddon", "Pikcachu"])Vậy là chúng ta có một khái niệm mới là NaN, viết tắt của Not a Number. NaN có thể hiểu là một giá trị không tồn tại hay là null trong Series của mình. Khi đọc vào CSV, với những ô không có giá trị (giá trị là blank) thì NaN cũng được dùng để thể hiện điều này.
Ngoài cách sử dụng ngoặc vuông (square bucket) [] thì chúng ta có thể sử dụng method get để lấy giá trị qua index.
# Get value by index
dota2.get(2)
# Get value by label
dota2.get("Morphling")
dota2.get("Pikachu")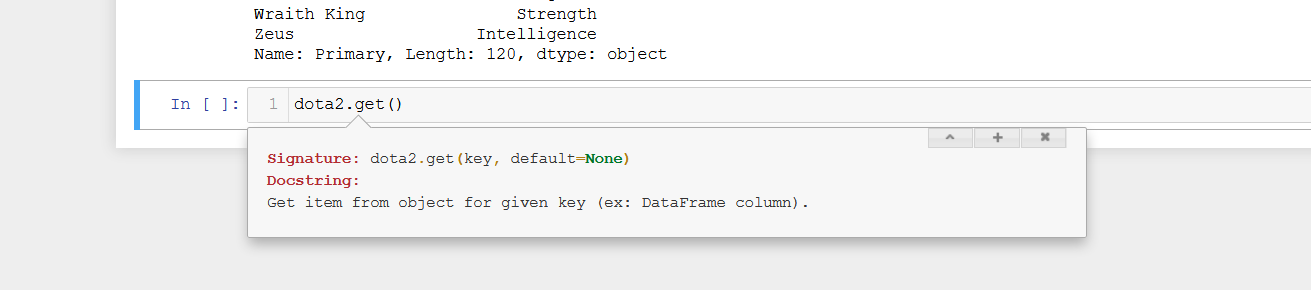
# Change `default` param
dota2.get(key="Pikachu", default="Not a DotA 2 character!")
dota2.get(key="Crystal Maiden", default="Not a DotA 2 character!")dota2.get(key=["Meepo", "Puck"], default="Not a DotA 2 character!")dota2.get(key=["Meepo", "Puck", "Pikachu"], default="Not a DotA 2 character!")dota2.get(key=[10, 20, 39], default="Not a DotA 2 character!")dota2.get(key=[10, 20, 39, 20000], default="Not a DotA 2 character!")Nếu muốn biết số lượng của các values trùng lặp thì chúng ta có thể dùng method value_counts
dota2.value_counts()Trong dataset này thì chúng ta chỉ có ba giá trị unique. Để chắc cơm thì chúng ta hãy thử sum lại xem số lượng tổng có chính xác không
dota2dota2.value_counts().sum()Vậy là cả 2 cách đều trả về tổng số là 120 giá trị. Ngoài ra, chúng ta cũng có thể sort value_counts theo số lượng từ cao xuống thấp (descending) hoặc thấp xuống cao (ascending)
dota2.value_counts(ascending=False)Đến đây chúng ta đã thấy được một số method của Series. Các methods này đã được định sẵn và chúng ta chỉ việc dùng. Nhưng nếu mình có một logic của riêng bản thân muốn áp dụng vào Series thì sao? Ví dụ, thay vì để các giá trị là Strength, Intelligence, Agility thì mình muốn dịch sang tiếng Việt, vậy có cách không? Câu trả lời là có, chúng ta có thể sử dụng method apply để áp dụng một function bất kì lên từng giá trị trong Series.
Để miêu tả việc này, mình sẽ bắt đầu bằng một function. Nếu ai đã quên hoặc không rõ, function là thuộc về Python, tức là không chỉ có pandas mới có function. Function chỉ đơn giản là nhóm các câu lệnh nhằm thực hiện một tác vụ cụ thể nào đó. Function nhận vào parameter và trả về một giá trị. Mình sẽ viết một function để dịch mấy từ tiếng Anh kia nha
# A custom function called `translate_primary` with 1 parameter `primary`
def translate_primary(primary):
if primary == "Agility":
return "Nhanh Nhẹn"
elif primary == "Intelligence":
return "Thông Minh"
else:
return "Khoẻ Mạnh"
Khi chạy code trên, các bạn sẽ không nhận được kết quả gì vì với cách viết này thì chúng ta mới chỉ định nghĩa function translate_primary chứ chưa làm gì cả. Nói một chút về cú pháp trong Python: == dùng để so sánh bằng nhau, if-elif-else là các câu điều kiện, return ám chỉ giá trị trả về của function.
Bây giờ mình sẽ áp dụng function translate_primary vào Series dota2
dota2.apply(translate_primary)Nhìn xem, giờ Series của chúng ta có hẳn tiếng Việt luôn nhá! Nói về chút về method apply này nhỉ. Ở đây mình truyền vào apply function tự viết là translate_primary. Như các bạn thấy, translate_primary có nhận vào 1 parameter. Khi kết hợp function vào trong apply, pandas tự động áp dụng translate_primary lên từng dòng dữ liệu và truyền value của từng dòng thành argument cho param primary của function translate_primary.
Mình sẽ ví dụ thêm một custom function nữa
# Add a character of "!" at the end of each `primary`
def add_exclamation(primary):
return primary + "!"
dota2.apply(add_exclamation)Function add_exclamation của mình rất đơn giản, chỉ là thêm dấu chấm cảm (!) cho parameter primary. Khi dùng cùng method apply, chúng ta có thể thấy tất cả giá trị trong Series đều được thêm dấu chấm cảm (!) vì tất cả values đều đã đi qua function add_exclamation của mình.
Với function translate_primary, các bạn sẽ cảm thấy hợp lí khi mình viết riêng ra thành một function vì logic điều kiện nó cũng tương đối vòng vèo. Còn function add_exclamation đơn giản như thế mà viết riêng ra thì quá mất công rồi. Tin vui là Python có một tính năng gọi là anonymous function. Với function bình thường, chúng ta cần đặt tên cho function và gọi nó bao nhiêu lần cũng được. Đối với anonymous function, hay trong Python gọi là lambda, các bạn không cần đặt tên cho function, thế nó mới gọi là anonymous (ẩn danh). Cụ thể hơn về lambda, các bạn có thể tìm kiếm thêm trên mạng (Reference: https://docs.python.org/3/tutorial/controlflow.html#lambda-expressions)
Bây giờ mình sẽ tạo một lambda có tác vụ y hệt như function add_exclamation và sử dụng bên trong method apply
dota2dota2.apply(lambda pri : pri + "!")Ở đây việc sử dụng lambda đem lại kết quả y hệt như khi dùng function add_exclamation mà lại ngắn hơn nhiều. Đối với các function có tác vụ đơn giản hoặc là sử dụng function trong function thì lambda là một lựa chọn rất hợp lí.
Đến hiện tại thì các methods của Series mà chúng ta sử dụng đều khá dễ hiểu. Thực tế, Series có nhiều methods rất hack não. Ví dụ một method rất hữu ích, đó là map. Đối với ai đã sử dụng map ở các ngôn ngữ khác, các bạn hãy tạm quên về cách dùng map ở các ngôn ngữ khác đi vì map trong Series không phải như vậy.
Mình sẽ mô phỏng method map bằng hai Series khác nhau.
# usecols = column we want to select as values
character_names = pd.read_csv("dota2_heroes.csv", usecols = ["Name"], squeeze = True)
character_names
# index_col = column we want to select as index
character_primary = pd.read_csv("dota2_heroes.csv", index_col = ["Name"], squeeze = True)
character_primary
Lúc này, khi chúng ta gọi method map trên Series character_names, pandas sẽ sử dụng values trong character_name (ví dụ: “Abaddon”, “Alchemist”…) và match các values này với index của Series character_primary (VD: “Abaddon” trong character_name sẽ được map với “Strength” trong character_primary)
character_names.map(character_primary)Kết quả trả về của method map vẫn giữ nguyên index của Series character_names nhưng values lúc này lại là values của giá trị tương ứng trong Series character_primary. Đối với ví dụ này, chúng ta sẽ không thấy nhiều giá trị vì cả hai đều đến từ một dataset. Nếu đây là hai Series thuộc hai dataset khác nhau và có thứ tự values khác nhau thì kết quả trả về sẽ có ý nghĩa hơn rất nhiều.
Đối với Series trong pandas, chúng ta còn rất nhiều điều lí thú khác để khám phá nhưng nếu để viết hết ra thì có lẽ bài blog này sẽ không có ai đọc nữa mất. Vì thế, mình sẽ tạm dừng phần Series ở đây. Nếu series này được viết tiếp, phần tiếp theo chúng ta sờ đến sẽ là Dataframe, tâm hồn và trái tim của pandas.
Recaps:
Keyword:
python, pandas, Anaconda, virtual environment, Jupyter Notebook, pandas Series, attribute, method, lambda
(DotA 2)TL;DR:
Ở bài này, chúng ta cài đặt Anaconda để setup môi trường python. Sau đó, chúng ta dùng Jupyter Notebook để tìm hiểu và trải nghiệm về pandas cùng một số attributes, methods trong Series của pandas.
Lời kết
Xin thú thực là mình không có kinh nghiệm về data analysis, càng không phải là một data analyst thật sự, và trên hết là mình chỉ tự học Python lúc rảnh rỗi. Thế nên bài blog này nói riêng và cả series này nói chung chỉ là những gì mình ghi chép lại trong quá trình học tập và chia sẻ cùng mọi người. Nếu các bạn có bất cứ câu hỏi gì, hi vọng mọi người comment và thảo luận sôi nổi. Bản thân mình cũng không có nhiều kiến thức về lĩnh vực này nên không đảm bảo sẽ giải đáp được hết thắc mắc của các bạn, nhưng chắc chắn việc chia sẻ sẽ giúp mỗi người chúng ta học hỏi được nhiều điều.
Bài blog này cũng có nhiều sự lan man có lẽ là dài dòng dành cho ai có kinh nghiệm rồi. Nếu ai đã biết, hãy coi như mình đang múa rìu qua mắt thợ và nếu có thiếu sót gì thi hi vọng các chuyên gia sẽ ném đá nhiệt liệt!
Happy analyzing!
Fun fact: Toàn bộ blog này được viết bằng Jupyter Notebook
Credit: Bài blog này nói riêng và series này nói chung dựa trên format của một khoá học trên Udemy (reference: https://www.udemy.com/course/data-analysis-with-pandas).


