[ML – 02] How to minimize cost function
Tiếp nối nội dung trong bài viết trước, hôm nay các bạn sẽ cùng tôi đi sâu vào tìm hiểu cách thức Machine Learning (ML) học hỏi từ dữ liệu. Như đã giới thiệu trong bài viết trước, để máy có thể học hỏi được từ dữ liệu chúng ta cần
– Tập dữ liệu để máy học từ đó, chính là các cặp (input, output) hay (x, y = f(x)))
– Xây dựng một mô hình hay hàm số h(x) (hypothesis: giả thuyết)
– Xây dựng một hàm số đánh giá sự sai khác (cost function hay error function) giữa h(x) và f(x): J(θ) (θ: là những tham số được đưa vào trong h(x) và có thể thay đổi được).
– Thay đổi các tham số θ sao cho J(θ) nhỏ nhất khi đó ta có h(x) gần với f(x) nhất.
J(θ) cũng là một hàm số nên để nó có giá trị nhỏ nhất ta sẽ nhắc lại một chút về cách tìm cực đại cực tiểu của hàm số.
1. Đạo hàm và phương pháp tìm cực đại, cực tiểu của hàm số:
- Độ dốc của một đường thẳng (slope hay gradient):
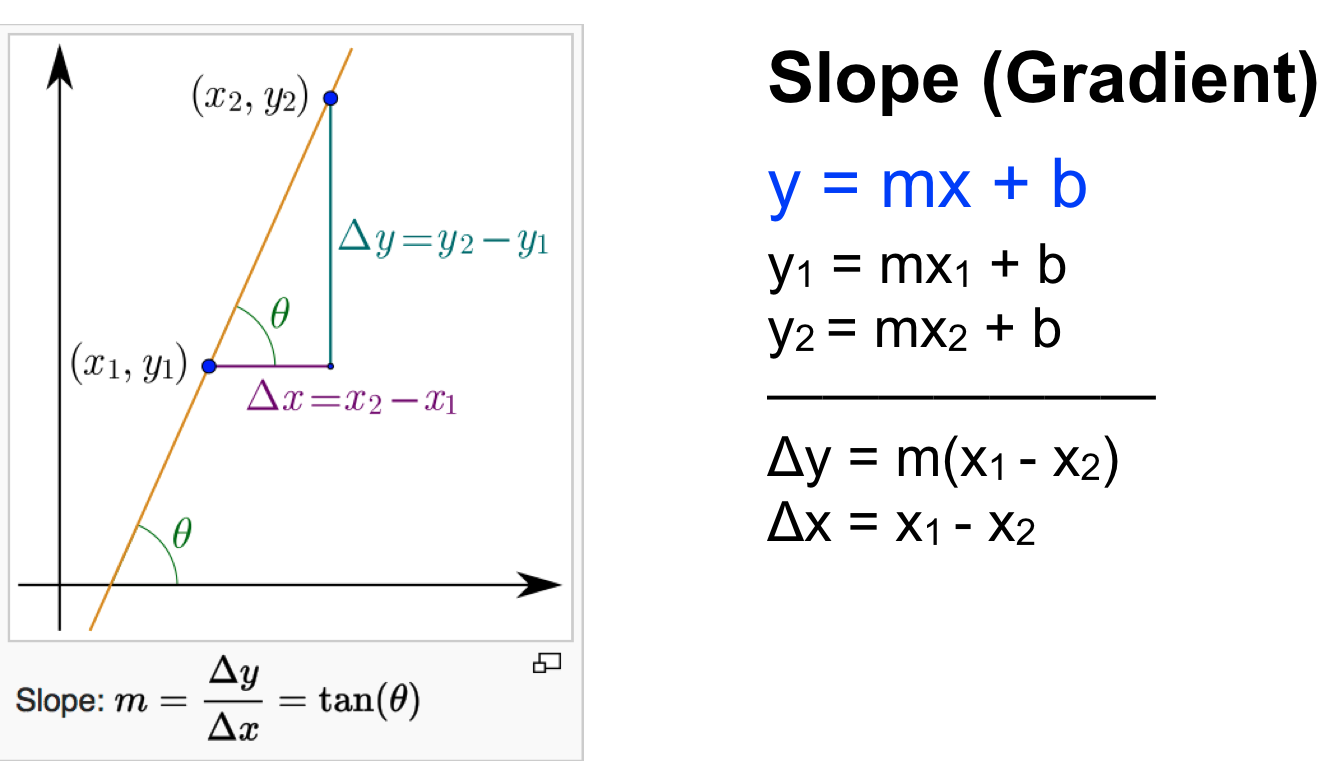

Độ dốc của một đường thẳng tương tự như vận tốc so với quãng đường, vận tốc càng lớn thì quãng đường đi được tăng càng nhanh và ngược lại.
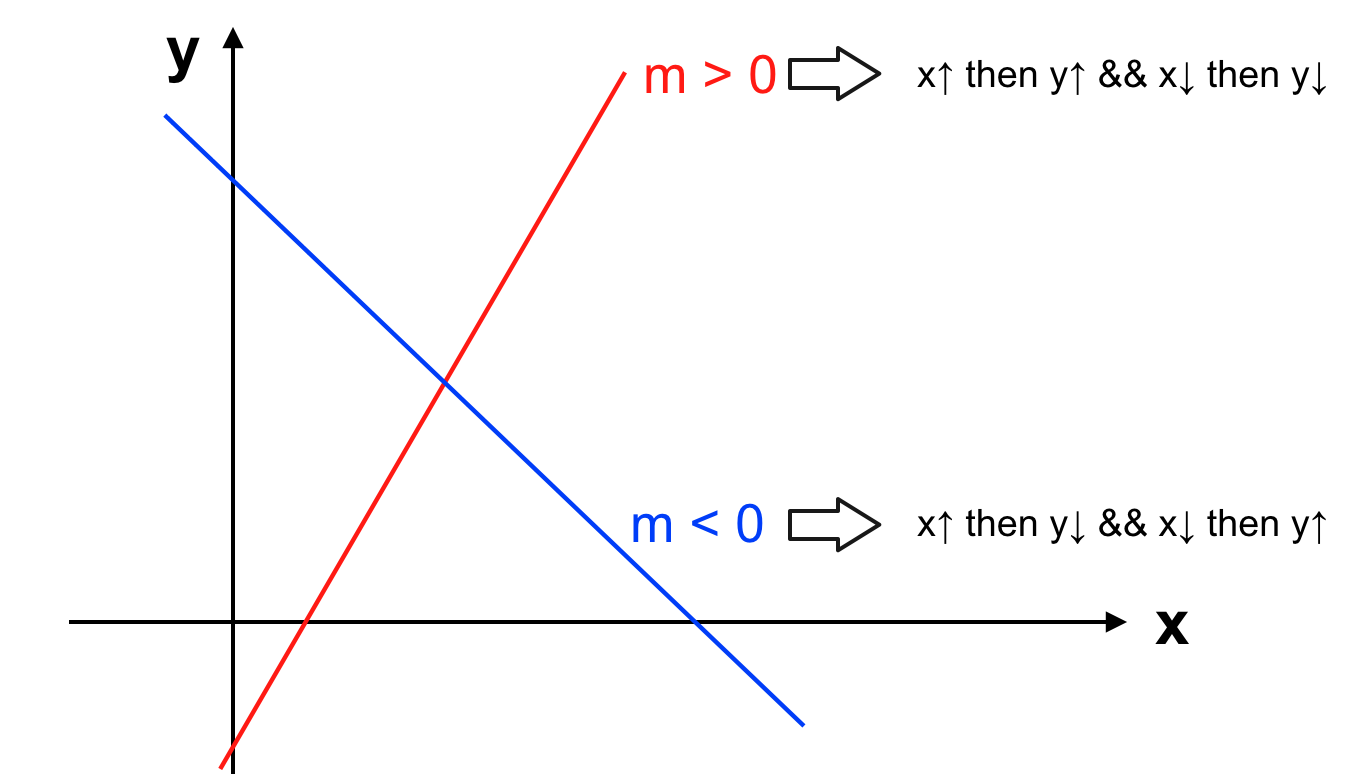

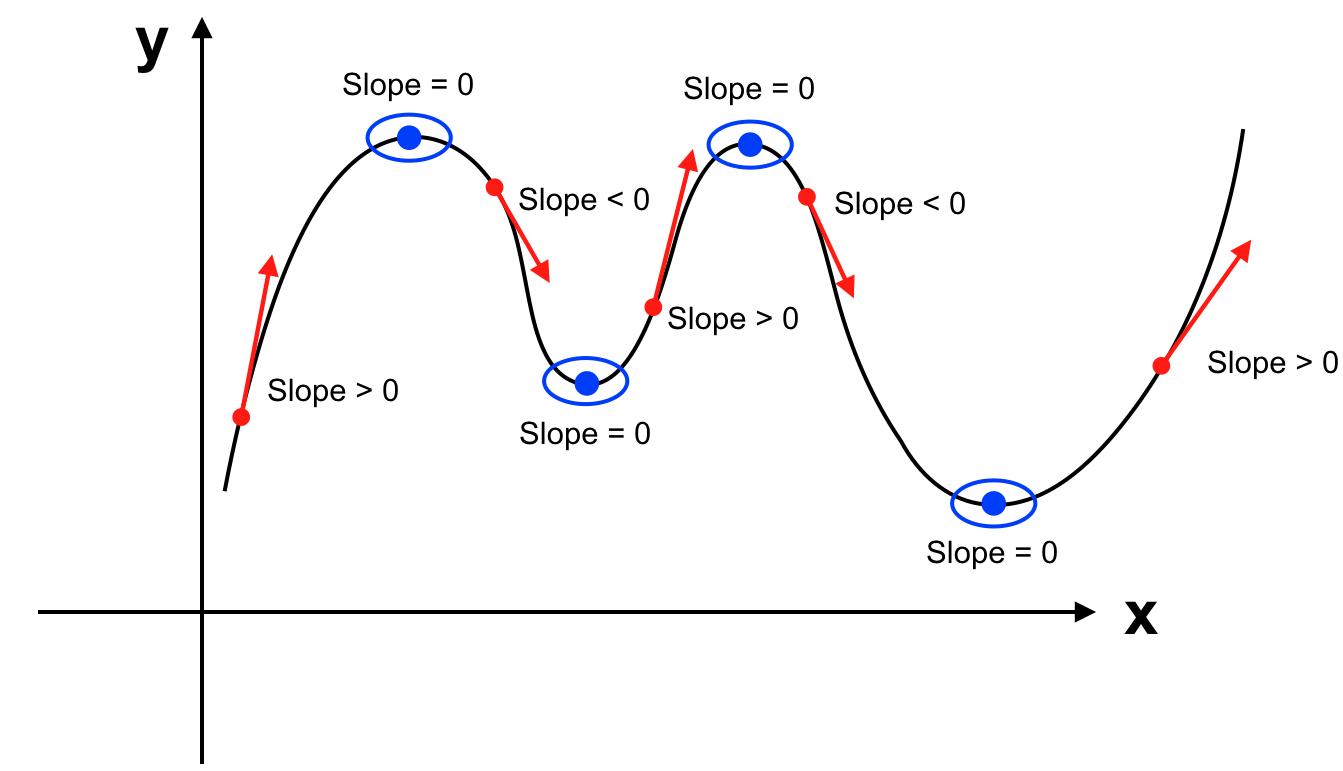
Khi slope > 0 tương tự như vận tốc > 0 thì quãng đường sẽ tăng hay đồ thị hàm số sẽ đi lên.
Khi slope < 0 tương tự như vận tốc < 0 thì quãng đường sẽ giảm (chúng ta đi lùi) hay đồ thị hàm số sẽ đi xuống.
Khi slope = 0 tương tự như vận tốc = 0, chúng ta không di chuyển nên quãng đường bất biến. Đồ thị hàm số sẽ đi ngang hay y = f(x) không thay đổi. - Độ dốc của hàm số tại một điểm:
Để ý rằng mọi đường cong thực tế được tạo nên bởi nhiều đoạn thẳng:
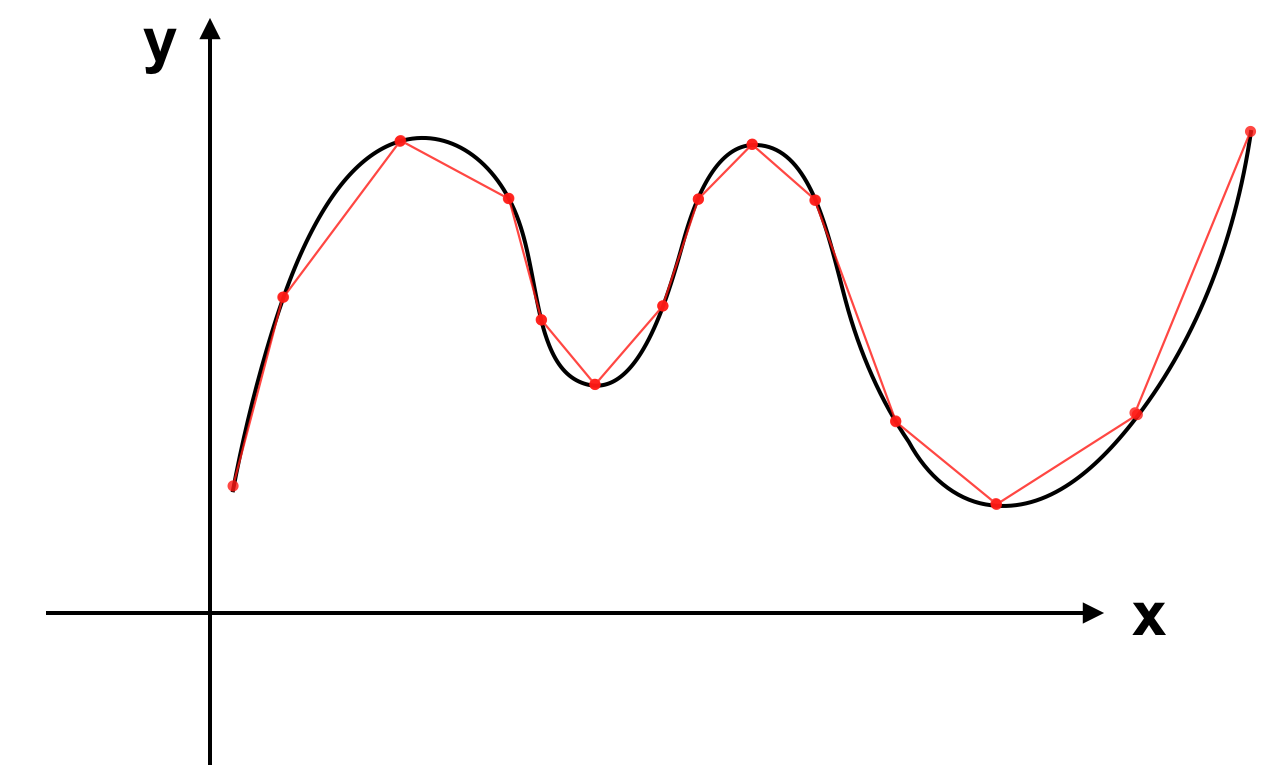

Vì 2 điểm bất kì xác định một đường thẳng nên slope giữa 2 điểm chính là slope của đường thẳng đi qua chúng. Ta có slope giữa 2 điểm trên đồ thị hàm số:
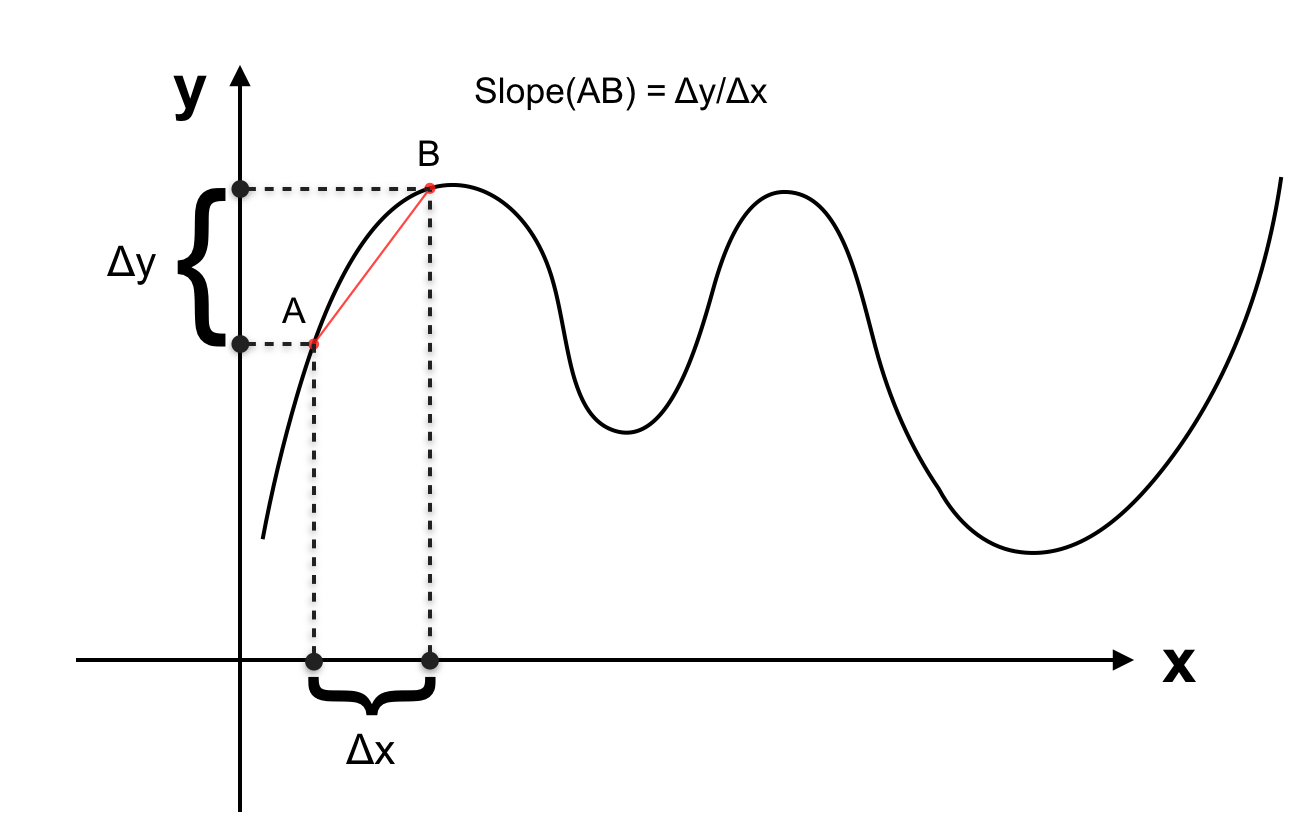

Khi 2 điểm trên tiến gần lại đến nhau, khoảng cách giữa chúng tiến về 0 chúng ta có slope tại 1 điểm.

- Đạo hàm của hàm số:
Hàm số mô tả lại sự biến thiên slope của mọi điểm trên hàm số chính là đạo hàm của hàm số đó. Cực đại và cực tiểu của hàm số:
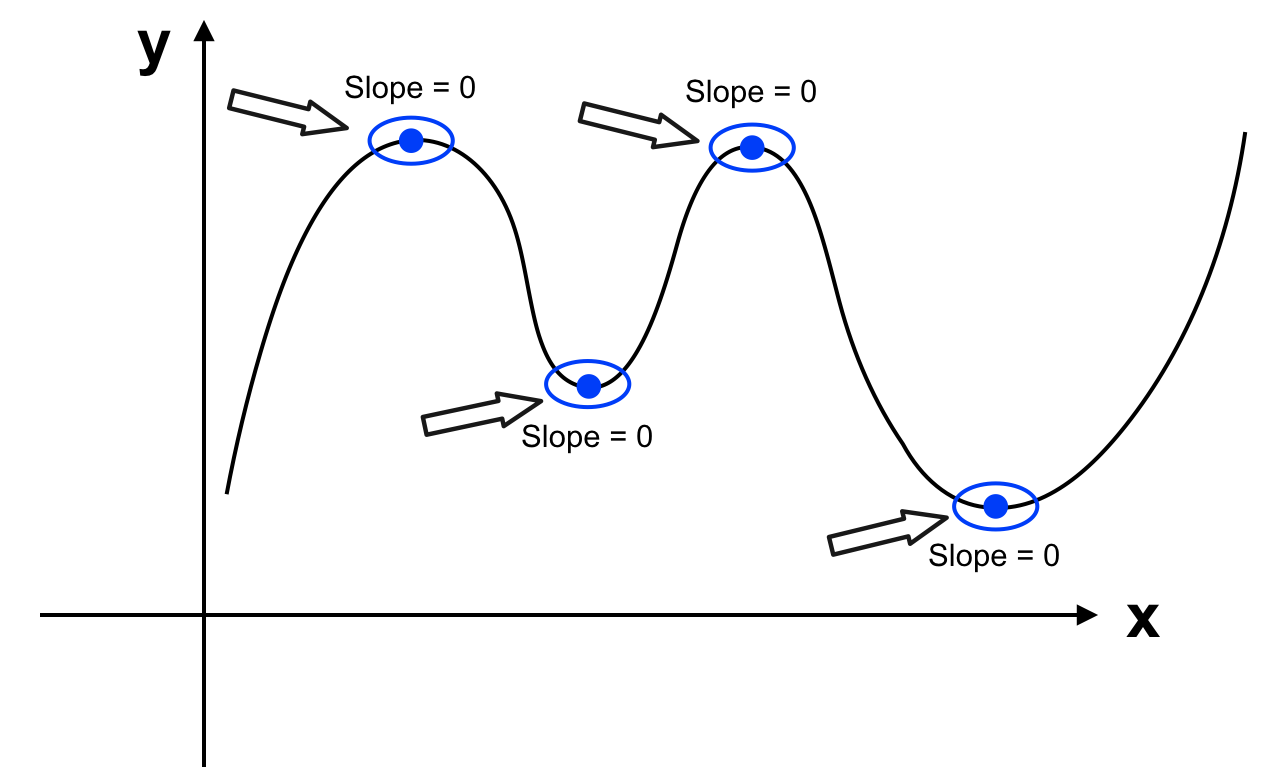
Để ý một chút chúng ta sẽ thấy khi di chuyển trên đường để có thể đang từ tiến về phía trước đi lùi về phía sau (từ vận tốc > 0 chuyển sang trạng thái vận tốc < 0) thì ta phải dừng lại (khi đó vận tốc = 0). Hàm số cũng vậy để chuyển từ đi lên sang đi xuống nó phải qua trạng thái slope = 0. Hàm số biến thiên giống như dãy núi vậy, đi lên rồi đi xuống qua những điểm là đỉnh núi và chân núi. Khi đó tại những điểm slope = 0, hàm số đạt giá trị cực đại hoặc cực tiểu.
2. Cực tiểu hóa cost function J(θ) như thế nào:
Đến đây chúng ta đã biết điểm cực đại và cực tiểu của hàm số ở đâu. Về mặt lý thuyết, ta đi tìm đạo hàm của J(θ), tìm tất cả những giá trị θ là nghiệm của phương trình J'(θ) = 0 (J'(θ) là đạo hàm của hàm số J(θ)). Sau đó chọn θ sao cho J(θ) nhỏ nhất trong tập nghiệm thu được. Phương pháp này còn được gọi là “Normal Equation”.
Tuy nhiên trên thực tế không phải mọi phương trình đều giải được, bên cạnh đó khi số lượng tham số lớn, việc giải phương trình có thể tốn nhiều chi phí về mặt performance. Vậy nên chúng ta có một giải thuật giúp khắc phục vấn đề này mang tên "Gradient descent". Trong bài viết tiếp theo, chúng ta sẽ đi tìm hiểu về giải thuật này và áp dụng cụ thể trong mô hình đơn giản nhất "Linear Regression" (Hồi quy tuyến tính).
Organize your development environments with Vagrant

Sử dụng git trong ubuntu