[Speech Processing] Nhận dạng giọng nói bằng Mô hình Markov ẩn (HMM)
Giới thiệu về mô hình Markov ẩn
Ngay khi máy tính ra đời con người đã mơ ước máy tính có thể nói chuyện với mình ?. Yêu cầu đơn giản nhất là máy có thể xác định được từ ngữ mà chúng ta nói, vì thế nhận dạng giọng nói đóng vai trò cầu nối quan trọng trong giao tiếp giữa con người và máy tính.
Có nhiều hướng tiếp cận cho nhận dạng tiếng nói trong đó được sử dụng nhiều nhất là Tiếp cận Nhận dạng mẫu thống kê bằng việc sử dụng các phương pháp máy học dựa trên thống kê dựa vào Mô hình Markov ẩn (Hidden Markov Model).
Mô hình Markov ẩn có nhiều ứng dụng, đặc biệt trong lĩnh vực tin sinh học. Mình xin trình bày một cách tóm tắt nhất có thể về HMM trong nhận dạng giọng nói.
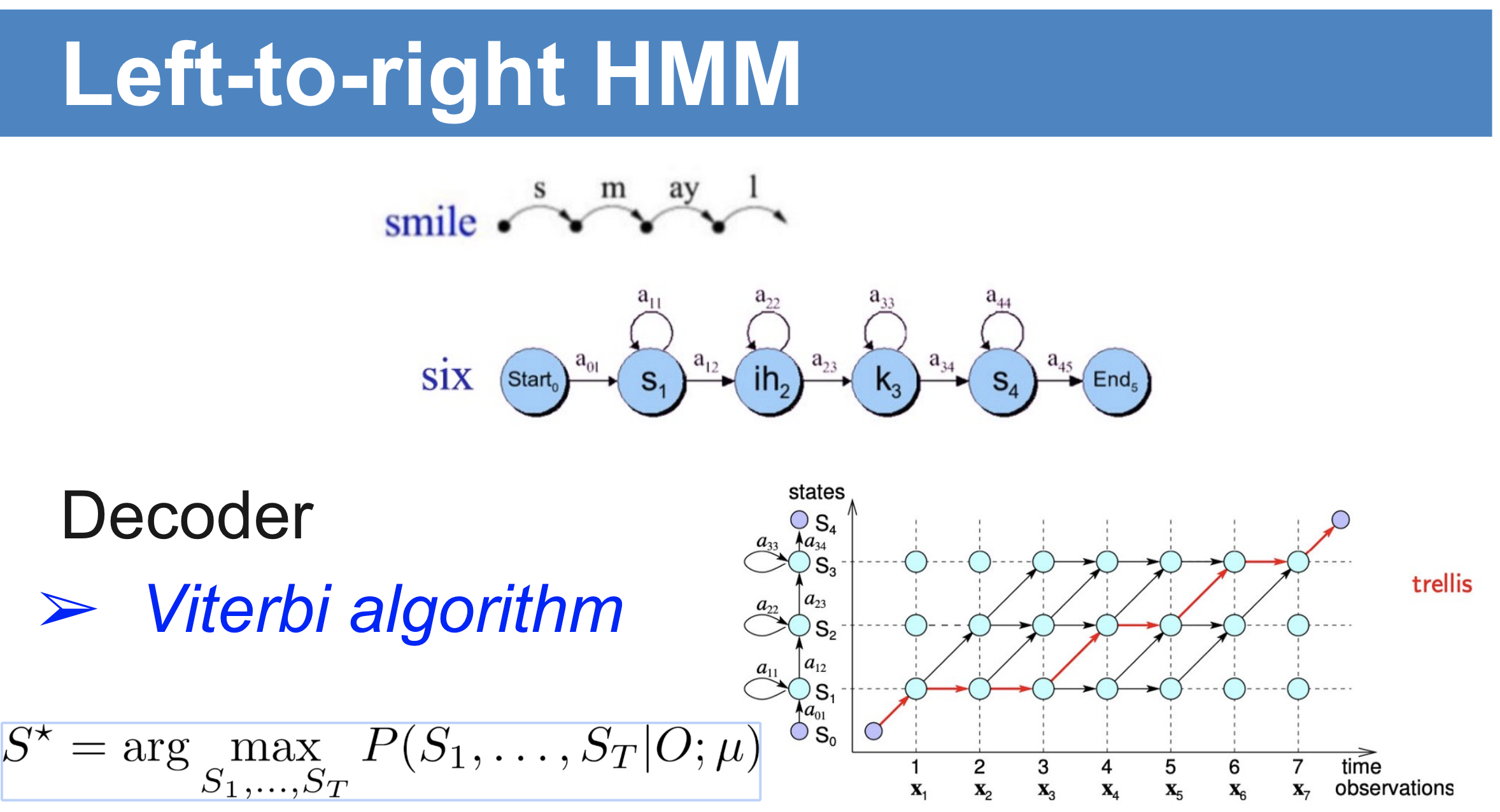
Mô hình HMM trong nhận dạng âm thanh là mô hình left-to-right HMM (left-to-right do sử dụng thuật toán Viterbi, chuỗi xác suất được sinh ra là ma trận dạng đường chéo đi từ trái sang phải). Ở blog này, mình sẽ hướng dẫn mọi người xây dựng mô hình HMM cho từ đơn lẻ, quá trình nhận dạng sẽ so sánh xác suất nào là lớn nhất làm kết quả nhận dạng. Một từ đơn lẻ sẽ bao gồm các âm vị (âm tiết), một âm sẽ chia ra thành 3 trạng thái bắt đầu, giữa, cuối nối tiếp nhau. Như từ smile sẽ bao gồm các âm “s”, “m”, “ay”, “l”, như thế có 12 trạng thái cho từ smile. Các trạng thái nối tiếp nhau theo trình tự thời gian nên một trạng thái sẽ đi kèm với các xác suất chuyển trạng thái ( xác suất “s” => “s” hoặc “s” => “m”).

 Đặc trưng âm thanh là MFCC (Mel-frequency cepstral coefficients):
Đặc trưng âm thanh là MFCC (Mel-frequency cepstral coefficients):- Window length: 25ms – độ dài trung bình mỗi state
- Hop length: 10ms – khoảng cách tạo mới window sau khi window trước được sinh ra
- 13 frame features: 12 MFCC + 1 energy
- 13 delta bậc 1 và 13 delta bậc 2 tính toán từ 13 frame features trên

Tổng cộng là 39 đặc trưng.
Lý thuyết tạm dừng tới đây! Let’s coding!
Chuẩn bị: Python 3, IDE(Jupyterlab,…), các thư viện hmmlearn(train mô hình), librosa(library rất mạnh để hỗ trợ xử lý âm thanh).
Mình đã gán nhãn trước khoảng hơn 600 file audio cho 5 mô hình của các từ “có thể”, “không”, “người”, “tôi”, “những”.
 Trích suất đặc trưng MFCC.
Trích suất đặc trưng MFCC.
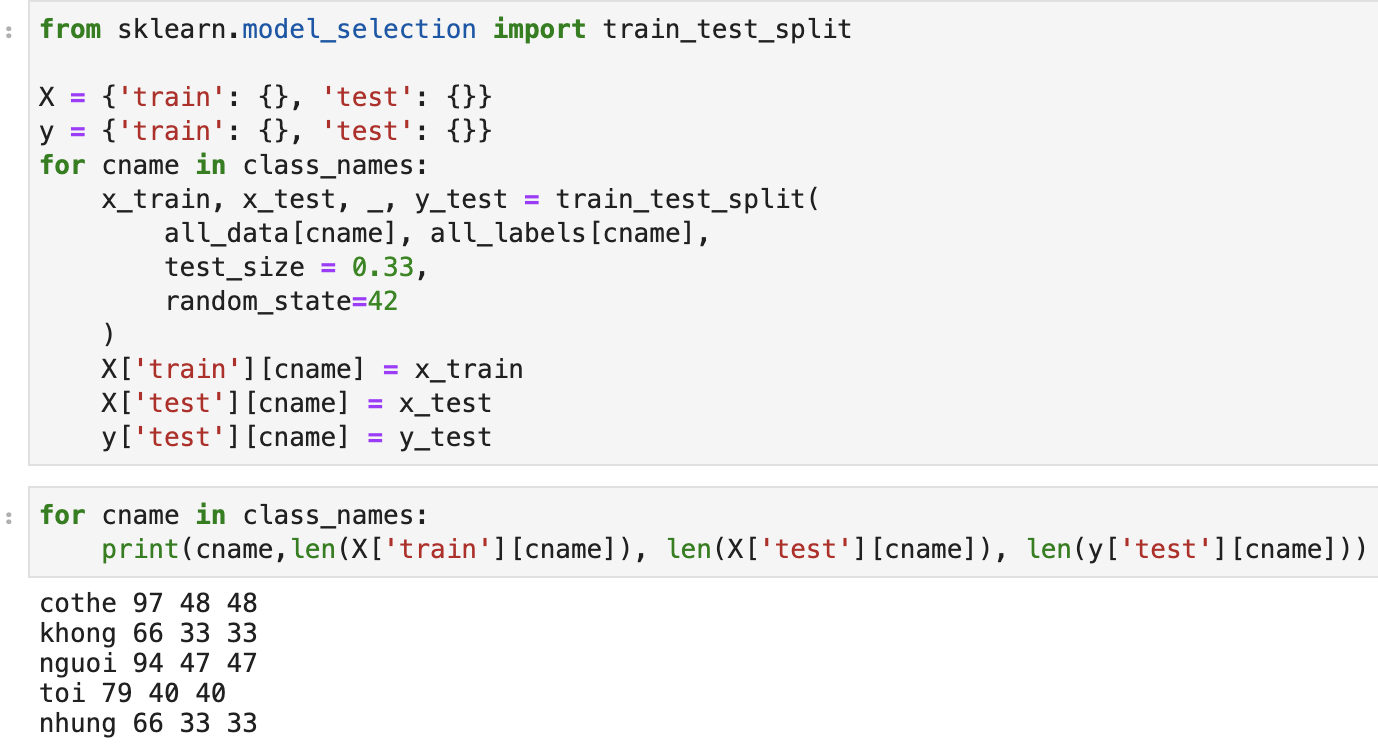
Chia train/test.
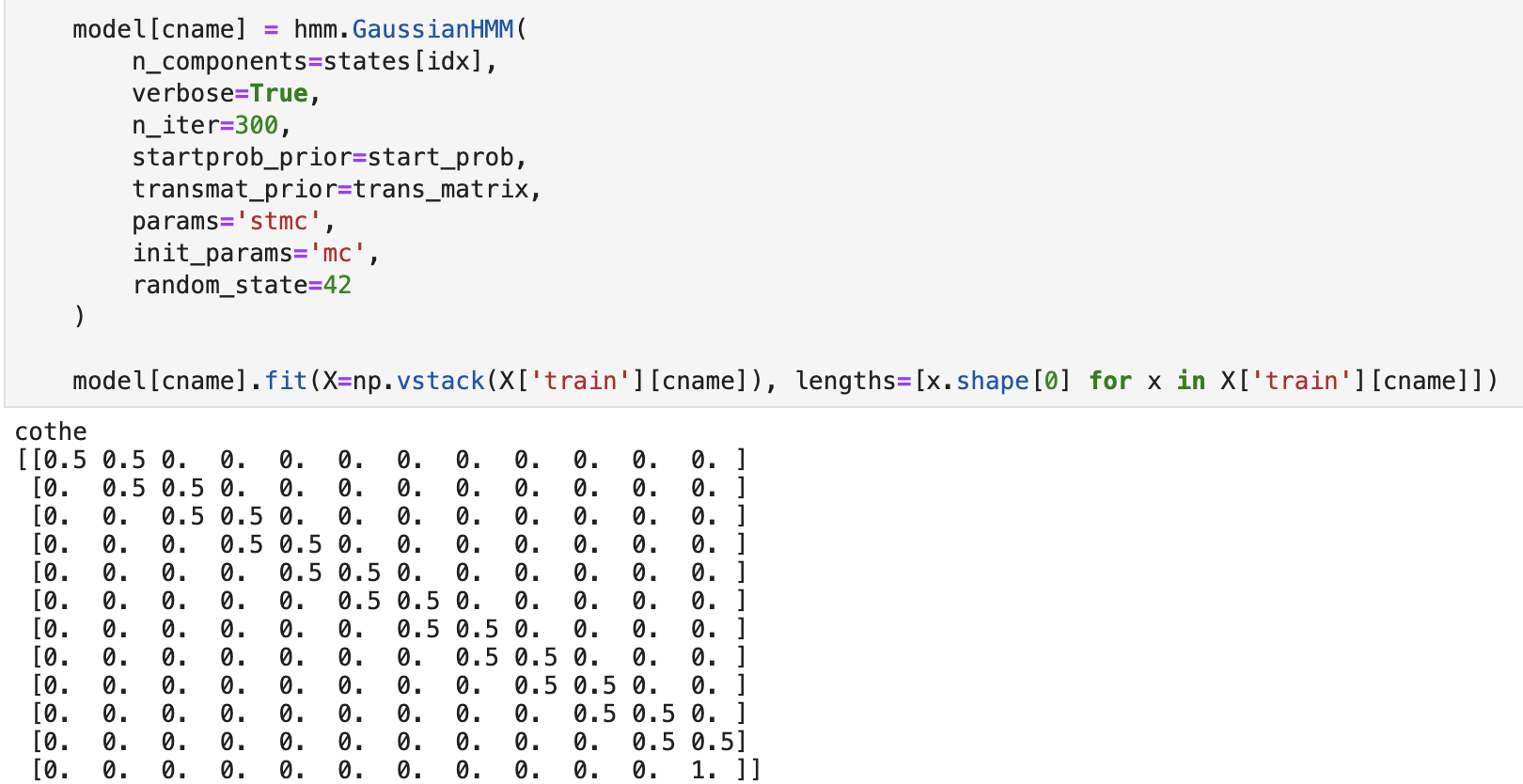 hmmlearn cung cấp 3 gói HMM (GaussianHMM, GMMHMM, MultinomialHMM). Mình sẽ sử dụng GaussianHMM, GMMHMM mình chưa thử, MultinomialHMM thì đã thử và fail lòi ?.
hmmlearn cung cấp 3 gói HMM (GaussianHMM, GMMHMM, MultinomialHMM). Mình sẽ sử dụng GaussianHMM, GMMHMM mình chưa thử, MultinomialHMM thì đã thử và fail lòi ?.
Bên trái là ma trận chuyển trạng thái của từ “có thể”.
 Kết quả train.
Kết quả train.
Source code: Github ( Chạy trên IDE jupyterlab, mình có app demo(App.py) nhưng app mình dev trên window, thư viện winsound trên mac hay linux sẽ không có nên không có chức năng record để test ?).
Tham khảo: https://docs.google.com/presentation/d/1wP_5TPFPDwy2bQE5Uy61rVWC1CBE8ni5pUmnsgVK7sE/edit#slide=id.p
Hẹn gặp lại mọi người trong những blog sau!
[ML – 11] Machine Learning Diagnostic P1
Giới thiệu về thuận toán K láng giềng (K nearest neighbor) trong machine learning