Đừng sử dụng CSV nữa !
Là một người làm việc với Data từ lâu, nhưng 2 năm trở lại đây tôi mới tiếp cận với Pandas và hệ thống sử dụng cơ sở dữ liệu là Google Driver, Google Spreadsheet nhiều. Bạn biết đấy, xây dựng hệ thống xử lí dữ liệu đầu cuối chưa bao giờ là dễ dàng cả. Tôi hiểu rằng đây là quá trình vô cùng nhàm chán và người thực hiện không thể tránh khỏi việc phải tạo ra nhiều tệp trung gian trong quá trình xử lí hoặc xuất các processing file trong quá trình xử lí dữ liệu để rà soát lỗi một cách dễ dàng hơn trong tương lai khi hệ thống đưa ra output sai. Và đọc tới đây bạn nghĩ tới gì nào, tất nhiên rồi : to_csv() – CSV file.
CSV file mang tới sự linh hoạt to lớn trong việc đọc, ghi, xem trước dữ liệu bằng các phần mềm. Nó là định dạng nổi tiếng nhất mà hầu như tất cả những ai đang làm việc với Dataframe đều sử dụng và tiếp xúc với nó. Vài năm trở lại đây tôi đã sử dụng csv rất nhiều, NHƯNG cho tới nửa năm trở lại đây tôi nghĩ :
“Liệu CSV có phải là lựa chọn duy nhất, có định dạng nào tối ưu hơn CSV không nhỉ?”
Thật may khi Pandas cung cấp cho chúng ta nhiều định dạng tệp có thể lưu trữ DataFrame của mình như :
- CSV
- Pickle
- Parquet
- Feather
- JSON
- HDF5
Và thế là tôi quyết định đi vào thử nghiệm và xếp hạng dựa trên các định dạng đó bằng thư viện nổi tiếng nhất : Pandas với 2 thông số chính sau :
- Dung lượng lưu trữ của file
- Thời gian Load từ file type từng loại thành Dataframe và Save Dataframe thành file type tương ứng
Trong thử nghiệm tôi sử dụng API để get dữ liệu, convert thành Dataframe và làm tất cả các tác dụng đều bằng thư viện Pandas.
- Dung lượng lưu trữ của file.
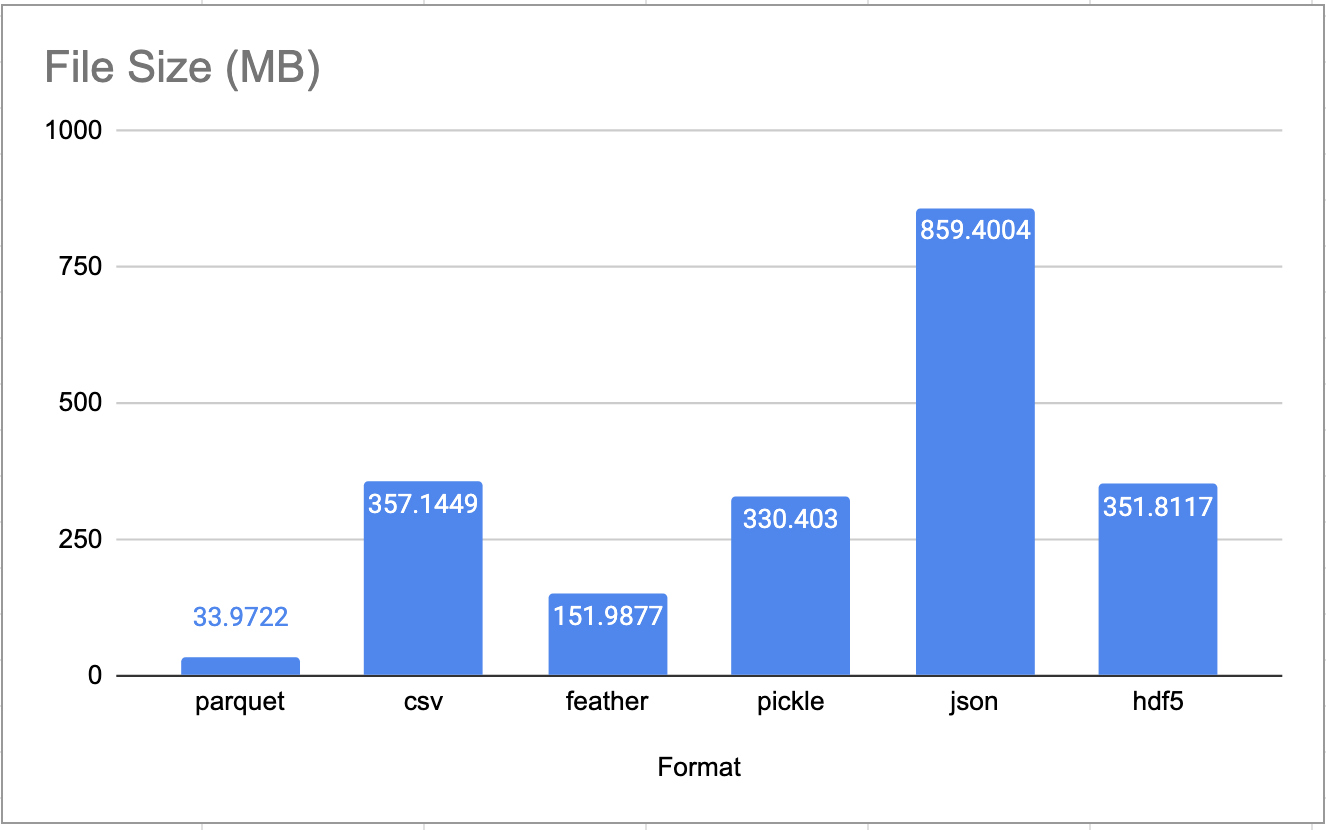
Bạn có thể thấy Parquet là nhẹ nhất, CSV của chúng ta xếp thứ 2 nhưng là từ trên xuống, và tất nhiên JSON file không phải là sự lựa chọn tốt về dung lượng cho việc lưu trữ các file xử lí trung gian rồi khi dung lượng phải lưu trữ hơn gấp đôi so với CSV và gấp 26 lần so với Parquet…
Vậy nên nếu nói về tối ưu dung lượng lưu trữ thì Parquet, Feather đều ổn hơn CSV. Tuy vậy sự chênh lệnh giữa CSV với Pickle, HDF5 đều không quá lớn.
Tại sao tôi vẫn phải nhắc về Pickle và HDF5 ? Vì phần sau sẽ làm bạn bất ngờ đấy.
2. Thời gian Load File và Save File
Ở đây tôi tiếp tục thử nghiệm thời gian Save File từ DataFrame về dạng file và load từ dạng File thành Dataframe
Và đây là chart để bạn tiện so sánh, tất cả đều tính trên đơn vị giây
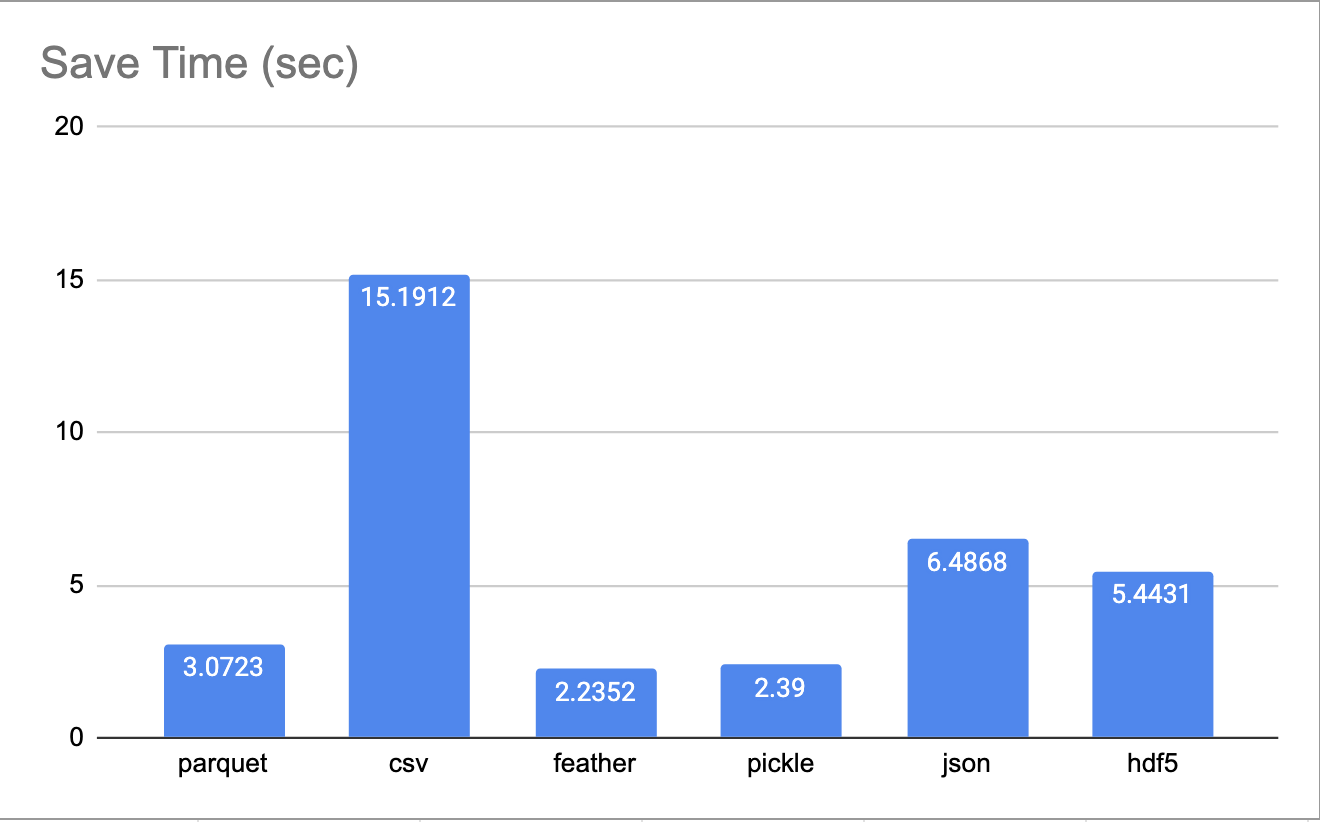
Ngạc nhiên chưa, CSV tốn nhiều thời gian để chuyển từ Dataframe thành file nhất với 15.1 giây, cùng với dung lượng gần như ngang bằng nhưng Pickle và HDF5 đều có tốc độ lưu nhanh hơn đáng kể. Pickle lưu nhanh gấp 7.5 lần và HDF5 nhanh gần gấp 3 lần.
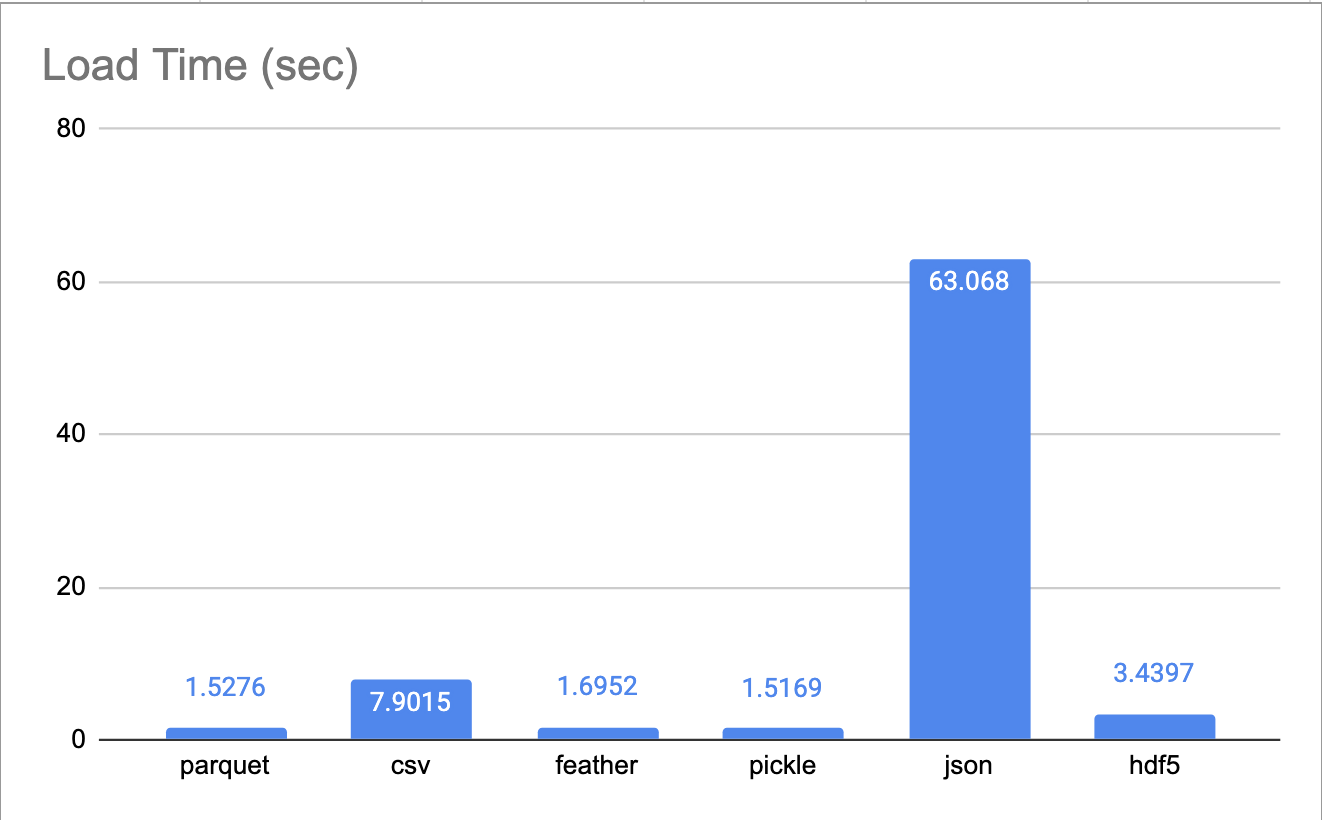
Còn với thời gian load thì sao, đáng buồn thay CSV vẫn cứ là chậm kinh khủng, chậm gấp gần 5 lần so với Parquet, Feather, Pickle. (Xin đừng cười ông già JSON nhé)
Và chúng ta có bảng tổng thời gian cuối cùng.

Thật buồn khi CSV của chúng ta chậm gần như gấp 7, 8 lần so với các loại file type khác… CSV có vẻ không phải là sự lựa chọn tốt nhất khi bạn cần xuất, đọc, lưu trữ một tệp xử lí trung gian.
Theo quan điểm của tôi thì Parquet, Feather đều là những sự lựa chọn ấn tượng hơn nhiều mà bạn nên thử trong thời gian tới với dung lượng nhẹ, đọc nhanh, lưu nhanh so với tất cả 6 loại trên…
3. Tóm lại thì…
Tôi biết là CSV rất tuyệt, tôi cũng thấy vậy, tôi cũng thích CSV vì những lí do sau :
- Pandas cho phép chúng ta chỉ view top 5, 10, 15… hàng của file CSV, tiết kiệm ram và tốc độ với nrows trong read_csv(). Điều mà các format khác không làm được vì chúng là dạng nhị phân hoặc cấu trúc.
- Excel và các tool văn bản khác có thể view được CSV, còn các file khác thì không mở trực tiếp được.
Thế nhưng có thể CSV đang giết chết tốc độ xử lí trong dự án của bạn, trên thực tế tôi đã thử nghiệm thay CSV và Parquet và tốc độ lưu trữ dữ liệu trung gian của dự án tôi tăng đáng kể và tiết kiệm bộ nhớ rất nhiều, thời gian chạy script gần như tăng gấp đôi so với CSV. Tôi chỉ lưu file CSV khi cần xuất output cuối cùng cho khách hàng.
Trừ khi DataFrame của bạn cần view bởi các tool tương tự như Excel thì ĐỪNG NHẮM MẮT NHẮM MŨI SỬ DỤNG CSV. Bạn nên cân nhắc sử dụng giữa Parquet, Feather hoặc Pickle bởi những lợi ích tôi đã phân tích ở trên, chúng đều cung cấp khả năng đọc và ghi file nhanh hơn nhiều so với CSV.
Lần tới khi gõ pd.to_csv() thì hãy nghĩ tới bài blog này, nghĩ tới một người đã dành 1 ngày cuối tuần để thử nghiệm và dành nửa ngày còn lại để viết blog chia sẻ cách giúp bạn speed up ứng dụng xử lí DataFrame. Nếu bạn giảm thời gian đọc, lưu, xử lí trong code cũng là giảm phí sử dụng SERVER cho khách hàng và nhiều lợi ích khác mà tôi sẽ nói trong một lần khác.
Tập code python Slack bot đơn giản
Giới thiệu về Playwright – Automation test
