Tìm hiểu Pandas (Bài 4): Các vấn đề liên quan đến mất mát dữ liệu, xử lý chuỗi thời gian và mô hình hoá dữ liệu
I. Các vấn đề liên quan đến mất mát dữ liệu
a. Missing data
Khi xủ lý đến dữ liệu, ta khó tránh khỏi việc dữ liệu thô (raw) luôn nằm ngoài các phạm vi ta mong muốn, từ việc crawl dữ liệu không ổn, hay việc input không đúng, ví dụ ta mong muốn column ‘age‘ luôn là con số dương và có khi phải nhỏ hơn … 200, ‘sex‘ chỉ nằm trong các category (male. female, other), v…v… Nếu ta xử lý dữ liệu không tốt, sẽ ảnh hưởng nhiều đến việc phân tích, thống kê hay mô hình hoá dữ liệu. Nhưng có lẽ vấn đề đáng sợ nhất là ta phải đối mặt với việc thiếu dữ liệu hay mất dữ liệu. NaN, Nat, Nil, Null và N/A… everywhere. Đáng sợ không phải là việc ta không xử lý đc nó theo kiểu … drop hết, mà là ta sẽ xử lý như thế nào đối với những bài toán khác nhau.
Khi ta thao tác với Pandas hay Numpy, khi hiển thị dữ liệu ta sẽ thấy vô số từ NaN xuất hiện. Với dữ liệu ngày tháng thì sẽ là NaT, còn lại thì NaN sẽ hiển thị. Ví dụ:
closingPrice categories 2014-05-01 531.35 A 2014-05-02 NaN B 2014-05-05 527.81 A 2014-05-06 515.14 C 2014-05-09 NaN D
b. Giải quyết vấn đề
Ta có thể dùng hàm fillna(), để thiết lập các giá trị mặc định.
Ví dụ: fillna(50)
closingPrice categories 2014-05-01 531.35 A 2014-05-02 50.00 B 2014-05-05 527.81 A 2014-05-06 515.14 C 2014-05-09 50.00 D
Nếu dữ liệu NaN không hợp lệ, ta mong muốn loại bỏ những dữ liệu đó khi tính toán t có thể dùng dropna().
Ví dụ:
closingPrice categories 2014-05-01 531.35 A 2014-05-05 527.81 A 2014-05-06 515.14 C
Ngoài ra ta hoàn có thể nội suy ra các giá trị NaN thông qua quyến tính, các hàm bậc 2, … với hàm interpolate().
Ví dụ:
closingPrice categories 2014-05-01 531.35 A 2014-05-02 529.58 B 2014-05-05 527.81 A 2014-05-06 515.14 C 2014-05-09 515.14 D
Ngoài ra có thể tham khảo thêm các phương thức:
fillna(method='ffill') hoặc fillna(method='bfill')
Việc sử dụng như thế nào hoàn toàn phụ thuộc vào việc bài toán của ta sẽ tính toán những dữ liệu đó như thế nào, vài trò của những dữ liệu NaN trong công việc tính toán dữ liệu đó không, để t có thể dùng những hàm đó một cách thích hợp.
II. Xử lý chuỗi thời gian
a. Import dữ liệu
Thông thường khi import dữ liệu kiểu thời gian, ta thường thao tác với kiểu dữ liệu cơ bản từ thư viện chuẩn của python là class datetime nhưng dữ liệu được import sẽ xuất hiện dưới kiểu str, ta nên convert sang kiểu datetime để có thể đánh chỉ mục cho từng cột.
googClosingPrices['TradeDate'] = pd.to_datetime(googClosingPrices['TradeDate'])
Vậy dữ liệu cột ‘TradeDate‘ đã ở dạng <class ‘pandas._libs.tslibs.timestamps.Timestamp’>
b. Đối tượng DateOffset và TimeDelta
DateOffset là một đối tượng đại diện cho việc thay đổi hoặc thêm phần bù cho chuỗi thời gian. mảng một chiều giống như mảng Numpy, nhưng nó bao gồm thêm một bảng đánh label. Series có thể được khởi tạo thông qua NumPy, kiểu Dict hoặc các dữ liệu vô hướng bình thường
today = pd.datetime.now() today + pd.DateOffset(weeks=1) ============================== 2019-05-09 13:30:20.374928 2019-05-16 13:30:20.374928
Note: đối tượng datetime.datetime thì khác hoàn toàn so với pd.Timestamp. Kiểu dữ liệu cơ bản thường không hiệu quả, so với pd.Timestamp làm việc trực tiếp với kiểu numpy.datetime64. Và đối tượng DateOffset thì làm việc trực tiếp với đới tượng pd.Timestamp, nên đối tượng datetime.datetime sẽ được tự động ép kiểu sang pd.Timestamp
c. Các phương thức quan trọng
Đôi khi ta muốn dịch chuyển các ngày trong tuần (Nếu các ngày xuất hiện như một chuỗi thời gian nối tiếp) về trước hoặc về sau, thậm chí với các ngày làm việc bình thường (business day):
index closingPrice categories TradeDate 0 0 531.35 A 2014-05-01 1 1 NaN B 2014-05-02 2 2 527.81 A 2014-05-05 3 3 515.14 C 2014-05-06 4 4 NaN D 2014-05-09
googClosingPrices.shift(3) ============================================ index closingPrice categories TradeDate 0 NaN NaN NaN NaT 1 NaN NaN NaN NaT 2 NaN NaN NaN NaT 3 0.0 531.35 A 2014-05-01 4 1.0 NaN B 2014-05-02
Các phép biến đổi
Ta có thể sử dụng hàm asfreq cho các phép biến đổi như sau. Ví dụ để nhận được chuỗi ngày tương ứng với các ngày cuối cùng của tháng, t sử dụng phép biến đổi như sau:
ibmTS.asfreq('BM')
1959-07-31 428
1959-08-31 425
1959-09-30 411
1959-10-30 411
1959-11-30 428
1959-12-31 439
1960-01-29 418
1960-02-29 419
1960-03-31 445
1960-04-29 453
1960-05-31 504
1960-06-30 522
Lấy mẫu dữ liệu
Hàm TimeSeries.resample cho phép chúng ta tóm tắt, tổng hợp dữ liệu chi tiết hơn dựa trên khoảng thời gian lấy mẫu và hàm lấy mẫu.
Downsampling là một thuật ngữ bắt nguồn từ xử lý tín hiệu số và đề cập đến quá trình giảm tốc độ lấy mẫu của tín hiệu. Trong trường hợp dữ liệu, chúng tôi sử dụng nó để giảm lượng dữ liệu mà chúng tôi muốn xử lý. Quá trình ngược lại là Upampling.
Ví dụ:
Timestamp close high low open volume
0 1401197402 555.008 556.41 554.35 556.38 81100
1 1401197460 556.250 556.30 555.25 555.25 18500
2 1401197526 556.730 556.75 556.05 556.39 9900
3 1401197582 557.480 557.67 556.73 556.73 14700
4 1401197642 558.155 558.66 557.48 557.59 15700
Sau đó ta thay đổi:
googTickData['tstamp']=pd.to_datetime(googTickData['Timestamp'],unit='s',utc=True)
googTickTS=googTickData.set_index('tstamp')
googTickTS=googTickTS.drop('Timestamp',axis=1)
googTickTS.head() tstamp close high low open volume
2014-05-27 13:30:02 555.008 556.41 554.35 556.38 811000
2014-05-27 13:31:00 556.250 556.30 555.25 555.25 18500
2014-05-27 13:32:06 556.730 556.75 556.05 556.39 9900
2014-05-27 13:33:02 557.480 557.67 556.73 556.73 14700
2014-05-27 13:34:02 558.155 558.66 557.48 557.59 15700
Định danh
Để chỉ định chi tiết cho phần bù khoảng thời gian, ta đưa ra khái niệm về các định danh được sử dụng trong Pandas:
- B, BM: Đại diện cho ngày làm việc (business day)và tháng làm việc (business month)
- D, W, M, Q, A: Đại diện cho ngày (Day), tuần (Week), tháng (Month), quý (Quater), năm (Year)
- H, T, S, L, U: Đại diện cho giờ (hour), phút (minutes), giây (second), milli giây (milli second), micro giây (microsecond)
googTickTS.resample('7T30S').head(5)close high low open volume tstamp 2014-05-27 09:30:00-04:00 556.8266 557.4362 556.3144 556.8800 28075.0 2014-05-27 09:37:30-04:00 556.5889 556.9342 556.4264 556.7206 11642.9 2014-05-27 09:45:00-04:00 556.9921 557.2185 556.7171 556.9871 9800.0 2014-05-27 09:52:30-04:00 556.1824 556.5375 556.0350 556.3896 14350.0 2014-05-27 10:00:00-04:00 555.2111 555.4368 554.8288 554.9675 12512.5 5 rows x 5 columns
Khái niệm và kiểu dữ liệu
Ngoài ra vẫn có thể tạo Panel từ Dict của các DataFrame hay từ chính các DataFrame
Khi xử lý đến chuỗi thời gian, ta thường chỉ chú ý đến “thời điểm và khoảng thời gian”. Và trong pandas đại diện cho “thời điểm” là kiểu Timestamp, tương đương với nó là kiểu datetime của python. Còn lại, đại diện cho “khoảng thời gian” ta có kiểu Period, và chỉ có duy nhất trên Pandas.
pd.Period('11/11/1918 11:00',freq='H')
pd.Period('11/11/1918 11:00',freq='H') - 48
============================================
1918-11-11 11:00
1918-11-09 11:00III. Vẽ đồ thị với matplotlib
Cả Series với Dataframe đều có rất nhiều phương thức để mô hình hoá đồ thị. Ta sẽ dùng thư viện matplotlib để biểu diễn một cách trực quan các điểm trên mặt phẳng toạ độ. Để sử dụng thư viện, ta cần import:
import matplotlib.pyplot as plt
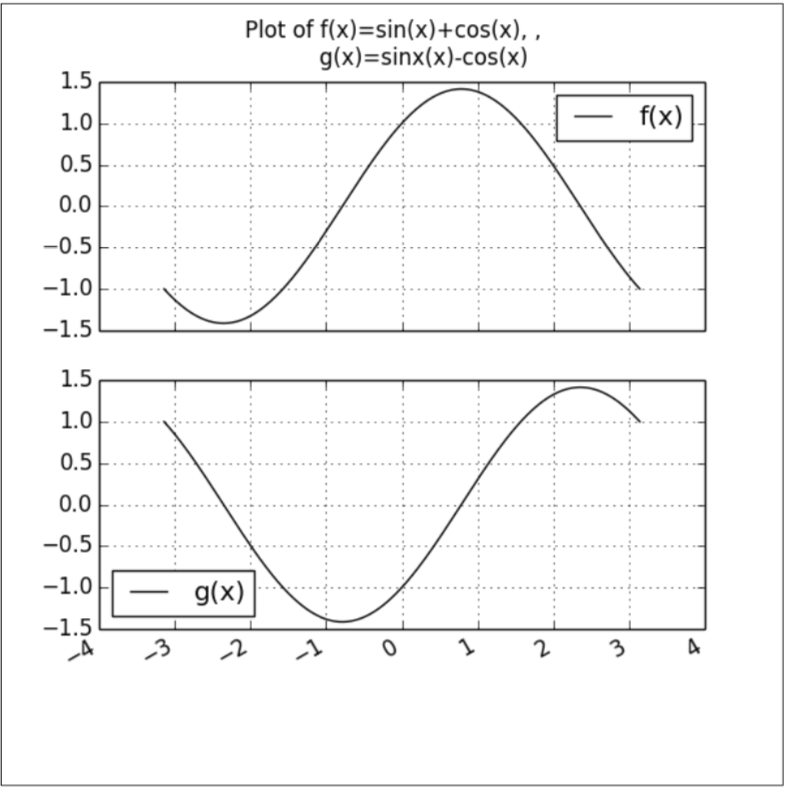
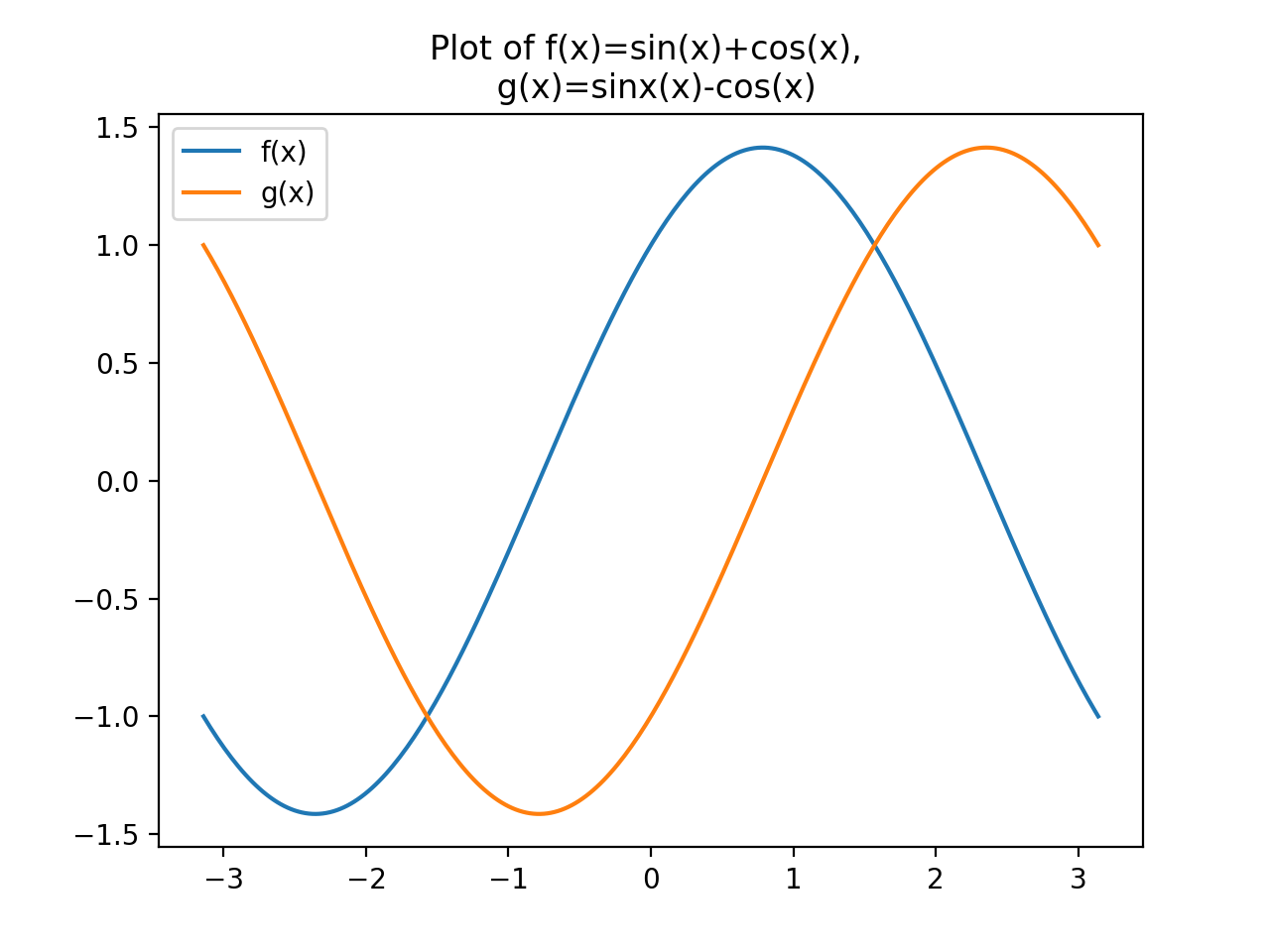
Giả sử ta muốn biểu diễn hai hàm số f(x) và g(x) với :
- f(x) = cos(x) + sin (x)
- g(x) = cos (x) – sin (x)
X = np.linspace(-np.pi, np.pi, 256, endpoint=True) f, g = np.cos(X) + np.sin(X), np.sin(X) - np.cos(X) f_ser = pd.Series(f) g_ser = pd.Series(g) plotDF = pd.concat([f_ser, g_ser], axis=1) plotDF.index = X plotDF.columns = ['sin(x)+cos(x)', 'sin(x)-cos(x)'] plotDF.head() plotDF.plot() plotDF.columns = ['f(x)', 'g(x)'] plotDF.plot(title='Plot of f(x)=sin(x)+cos(x), \n g(x)=sinx(x)-cos(x)') plt.show()
IV. Kết luận
Vậy trong phần này ta đã hoàn thành phần các phần quan trọng là xử lý với việc mất mát dữ liệu khi thao tác với Pandas, đồng thời thực hiện mô hình hoá dữ liệu trên mặt phẳng đồ thị với thư viện matplotlib. Việc thao tác để làm mượt hoá dữ liệu, hay có thể nói một cách khác là ta đã biến dữ liệu thô thành một loại dữ liệu có cáu trúc hoàn chỉnh để phục vụ cho các phase sau, như làm input cho dữ liệu để Học Máy (Machine Learning), hoặc Khai Phá Dữ Liệu (Data Minding) đồng thời cũng biết cách biểu diễn dữ liệu một cách trực quan qua đồ thị.

Tìm hiểu Pandas (Bài 2): Cấu trúc dữ liệu của Pandas

Pandas trong Python (Bài 1): Giới thiệu chung
