[ML – 09] Understanding Neural Network P3
Xin chào các bạn, hôm nay chúng ta tiếp tục loạt bài về ANN. Trong bài viết trước chúng ta đã đi vào ví dụ cụ thể xem ANN vận hành như thế nào, và nó có lợi hơn so với Logistic Regression ra sao đồng thời cũng đã bước đầu tưởng tượng được ANN học như thế nào. Khi áp dụng giải thuật Gradient Descent với yêu cầu cần tính đạo hàm tại tất cả các tham số θ hay nói cách khác là xác định xem mỗi tham số θ ảnh hưởng tới cost function như thế nào. Ở bài trước ta đã biết 2 cách tính đạo hàm và thấy được rằng cách tính ngược đạo hàm của cost function J(θ) tại mỗi node hay mỗi neuron sẽ giảm thiểu chi phí tính toán đi rất nhiều (khi ANN càng phức tạp). Bây giờ chúng ta sẽ xem, nếu áp dụng cụ thể, giải thuật sẽ như thế nào ?
1. Cost function:
Đối với ANN thì cost function phụ thuộc vào hàm activation của layer cuối cùng (Output Layer), mà trong trường hợp cụ thể xuyên suốt 3 bài viết về ANN này thì mọi hàm activation đều là Sigmoid Function. Vì vậy nên cost function sẽ có dạng tương tự Logistic Regression:
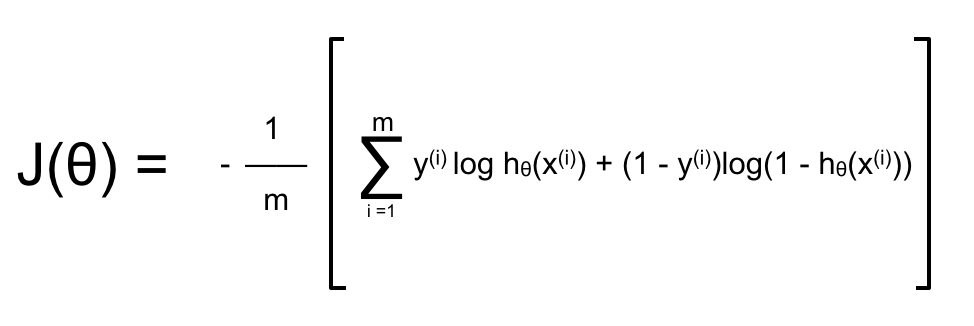
Đối với ANN có k output hay dùng để phân loại k label khác nhau thì cost function có dạng:
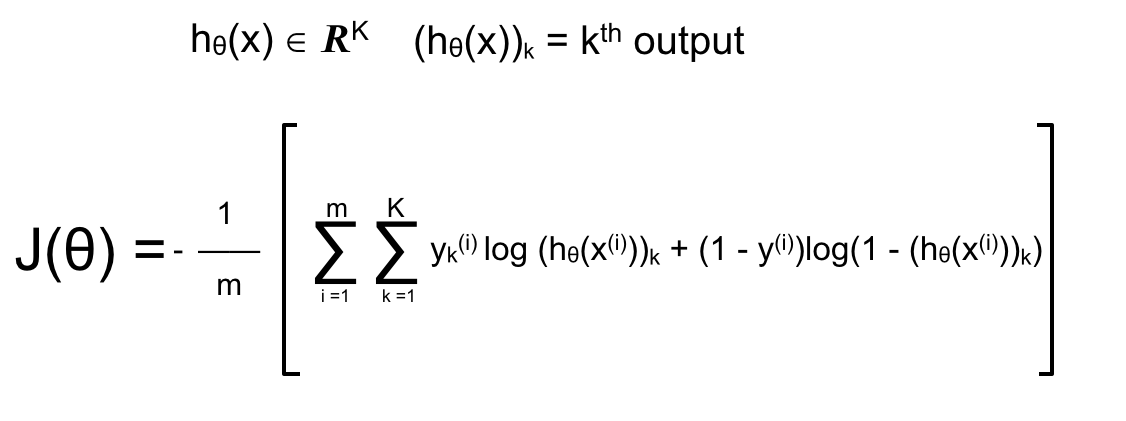
Trong đó ở đây m là số lượng training example trong training set, còn k là số lượng output hay số lượng label. Để đơn giản, trước tiên ta sẽ làm việc với training set chỉ có 1 training example duy nhất và mỗi layer chỉ có 1 neuron. Cost function và mạng neuron trong ví dụ hôm nay sẽ như sau:
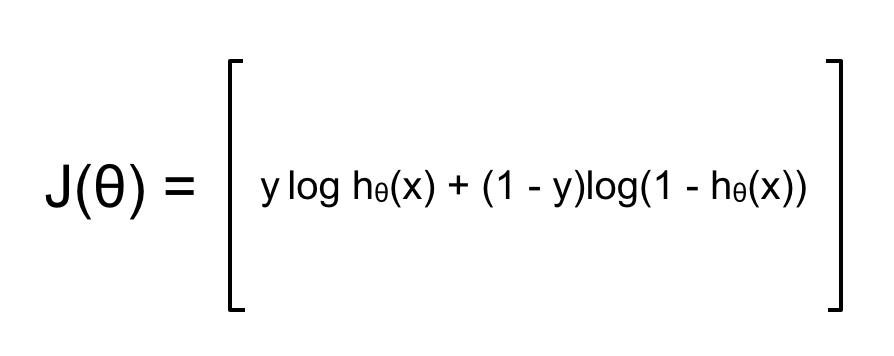
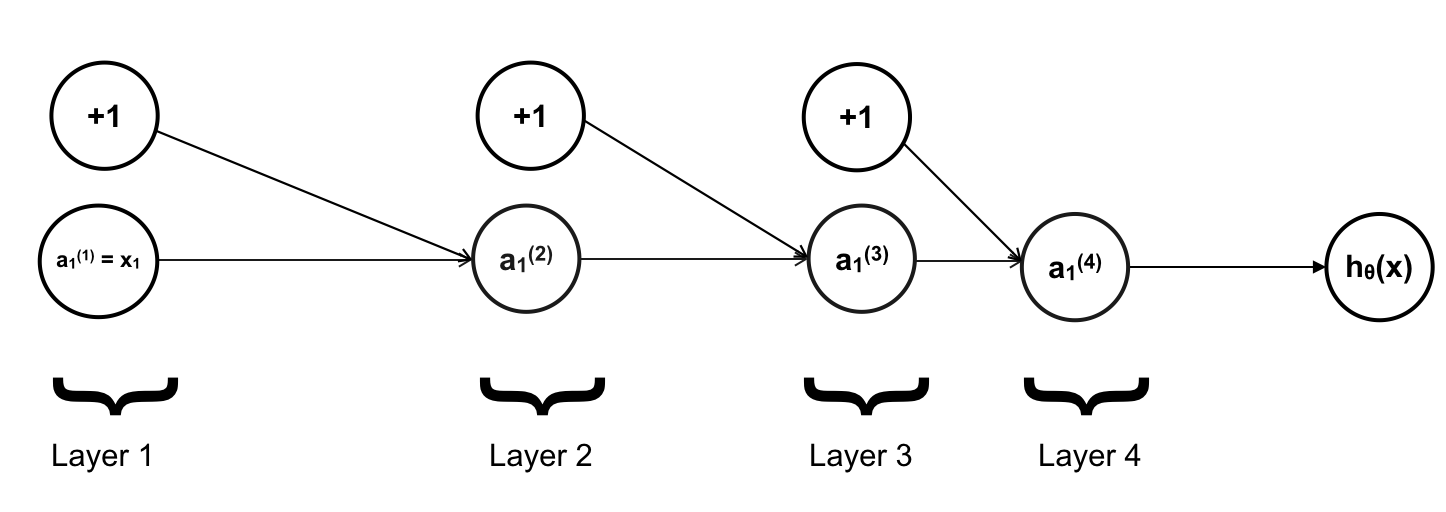
Mục tiêu của ta là tính đạo hàm tại mỗi tham số θ, chẳng hạn với θ11(1):
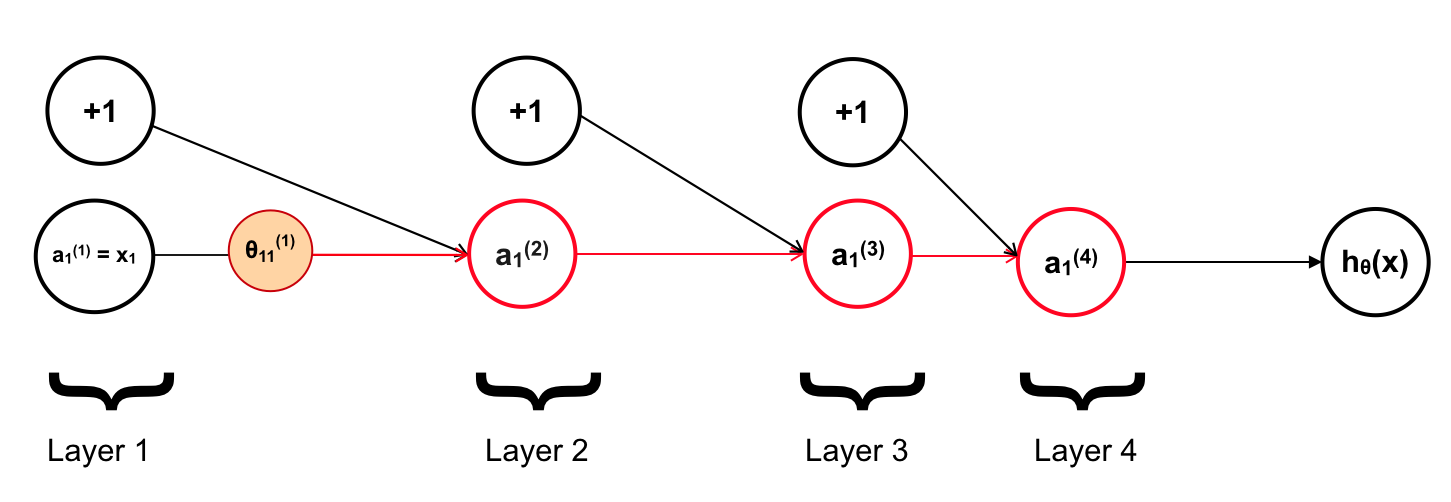
2. Back Propagation Algorithm:
Giờ chúng ta xem θ11(1) ảnh hưởng tới các neuron như thế nào ?
Đầu tiên là a1(2)
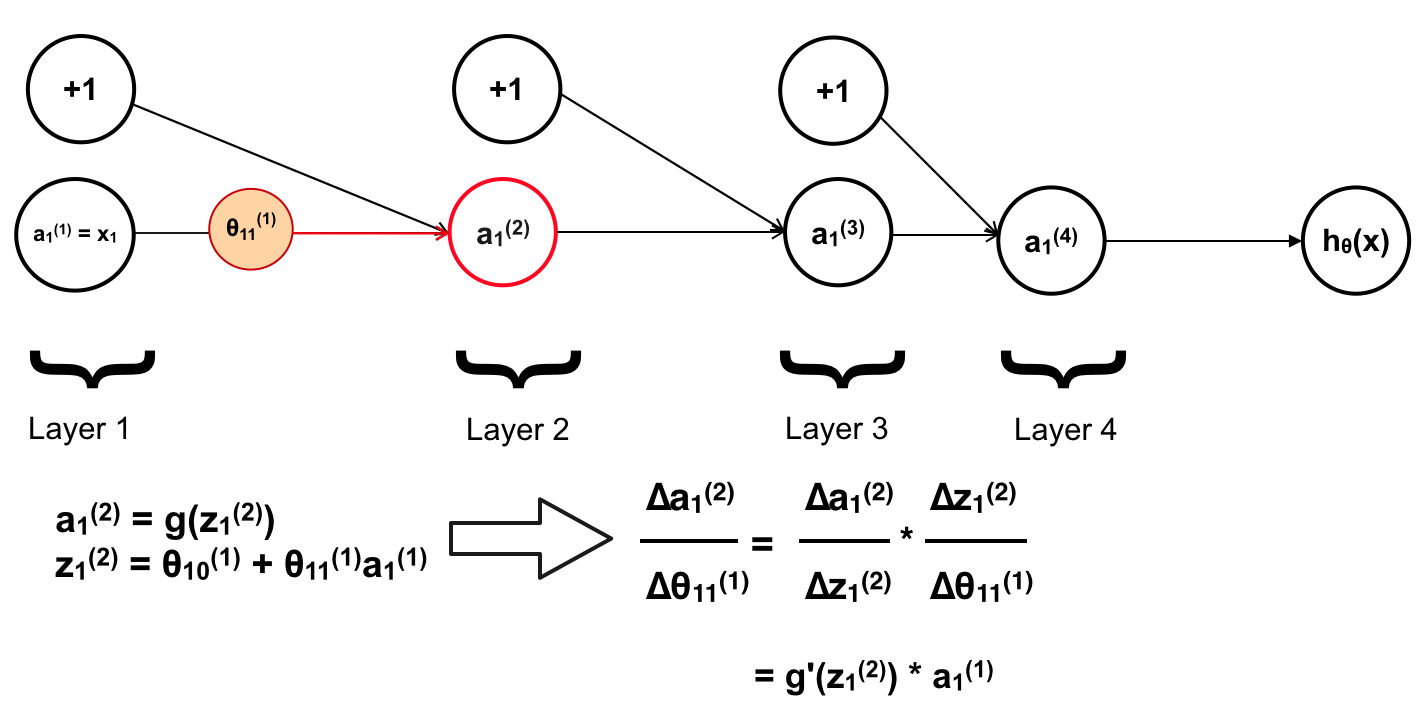
Tiếp theo là a1(3)
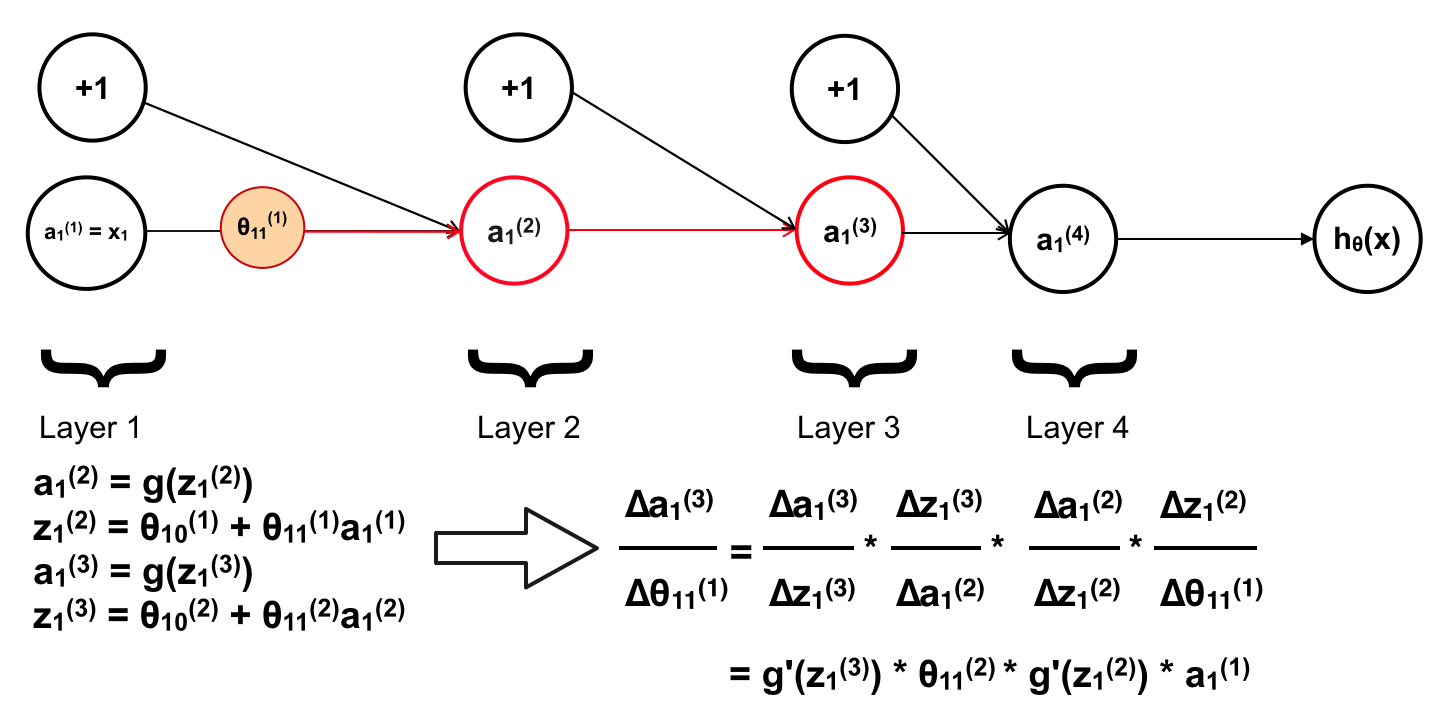
Tiếp tục với a1(4)
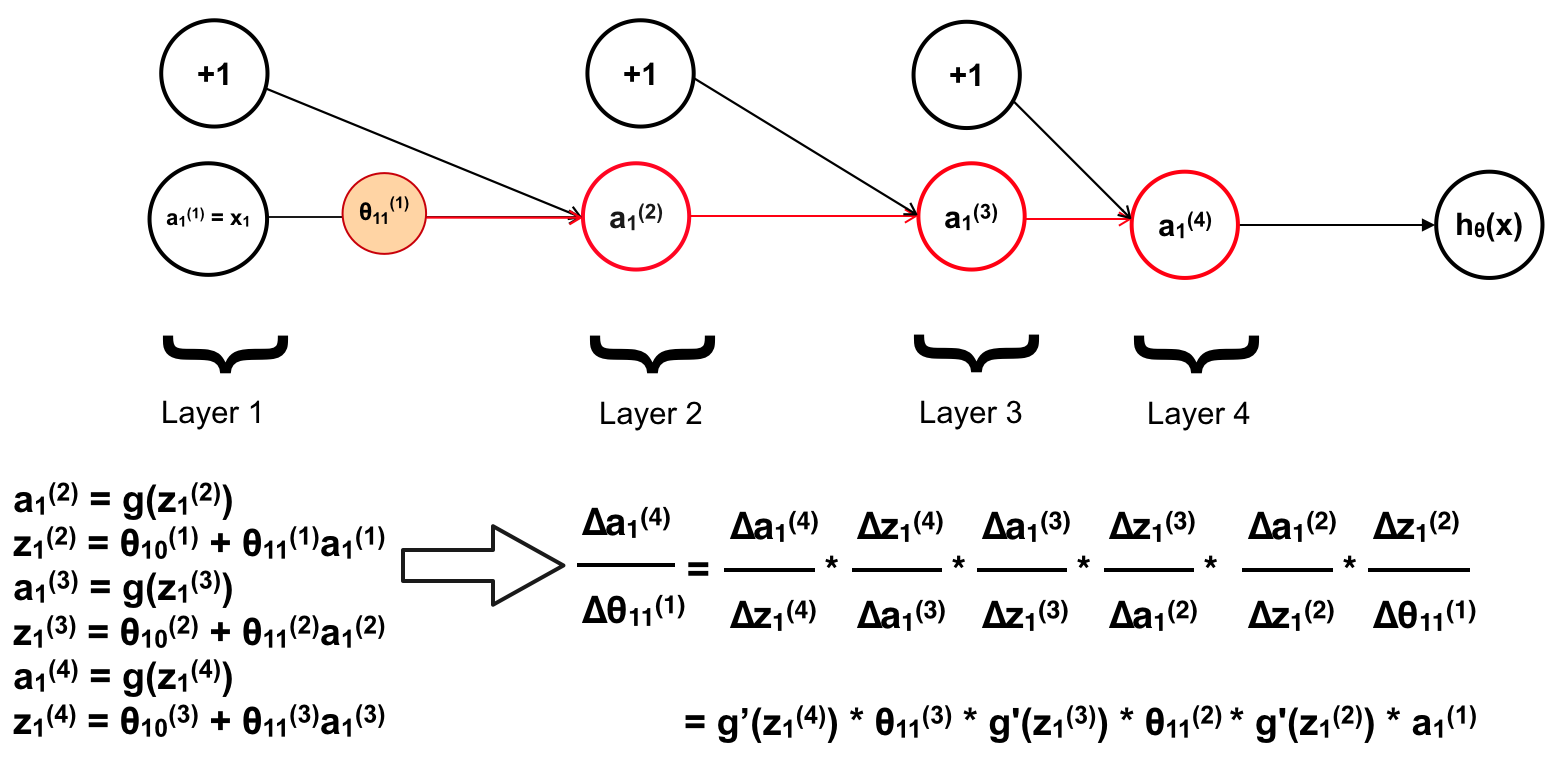
Ở đây a1(4) chính là hθ(x). Mà trong bài về Logistic Regression chúng ta đã tính ra được đạo hàm riêng tại mỗi θ có dạng:
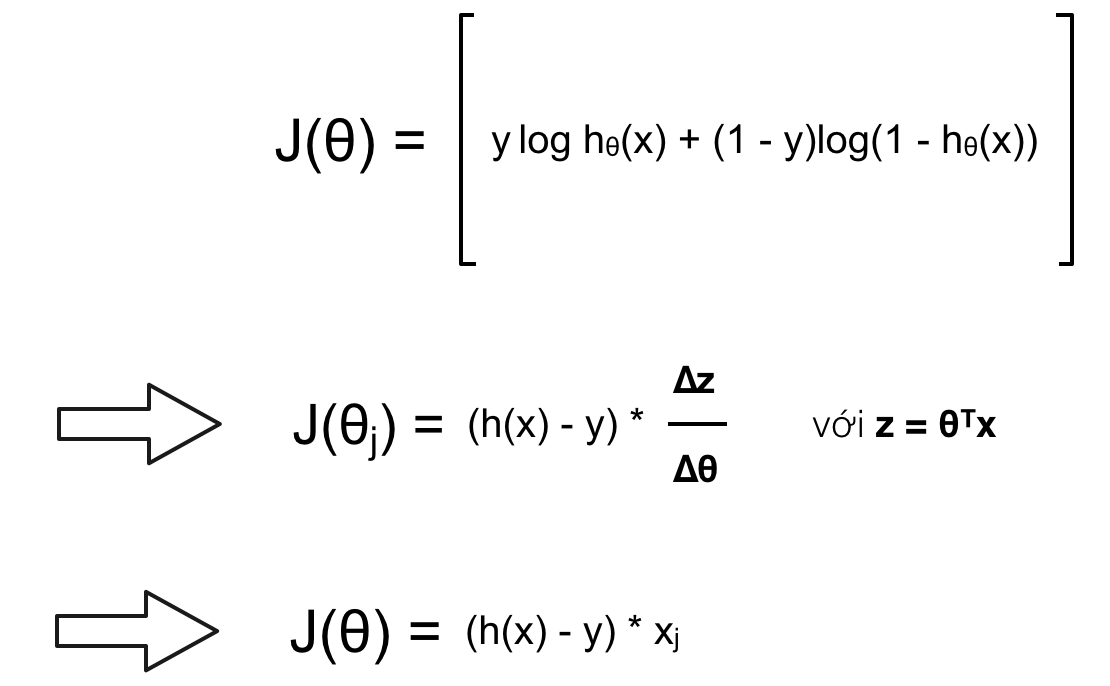
Nên đạo hàm tại z1(4), hay z1(4) ảnh hưởng tới cost function là a1(4) – y (chính là hθ(x) – y). Vì khi đó đạo hàm riêng của J tại z1(4) sẽ có phần đạo hàm của z trên θ bằng 1. Chính vì vậy ta không cần tính toán θ ảnh hưởng tới a1(4) mà chỉ cần tính θ ảnh hưởng tới z1(4). Ta bỏ đi phần đạo hàm trên a1(4) sẽ có:
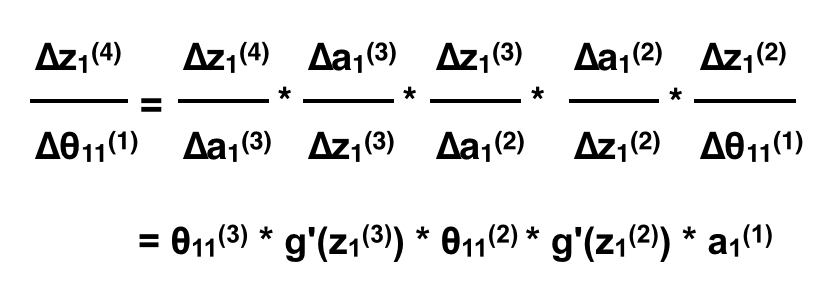
Nếu như ta thêm 1 feature x2 ta sẽ có kết quả tương tự khi tính đạo hàm riêng tại θ12(1):
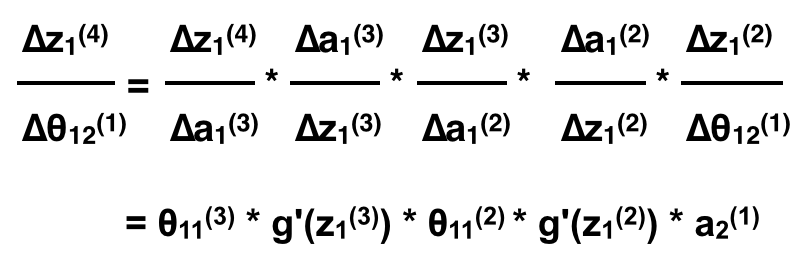
Như vậy nếu như ta muốn tính đạo hàm riêng tại một θ bất kì, ta coi như ANN bắt đầu từ neuron đó và tính tương tự như trên, thì mọi θ của cùng một layer sẽ có đạo hàm riêng gần như giống nhau trừ thành phần aj(1) là neuron nó liên kết (Neuron bắt đầu, θijℓ liên kết từ neuron j ở layer ℓ tới neuron i ở layer ℓ+1). Quan sát ví dụ trên sẽ thấy rất rõ với 2 feature x1 và x2. Bên cạnh đó nếu để ý một chút là các phần θ11(i) * g'(z1(i)) lặp lại khi ta tính qua mỗi layer.
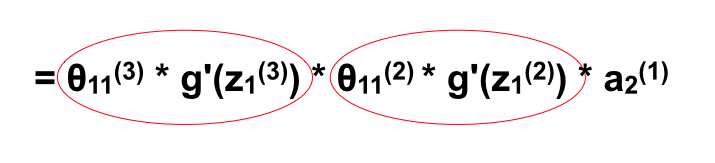
Vậy nếu ta tính ngược lại kết quả sẽ như sau:
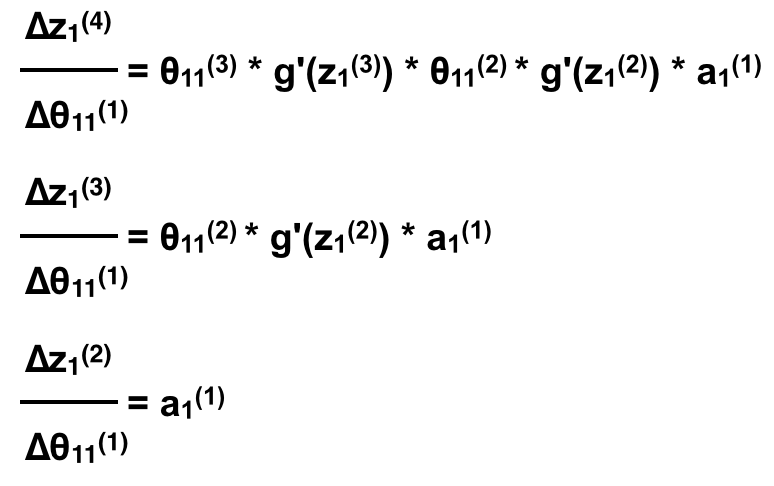
Hay:

Giờ chúng ta sẽ tổng quát hoá quá trình này, và tạo ra một đại lượng mới δ để tiện cho việc tính toán. δ được gọi là sai số (error) tại mỗi neuron có giá trị được tính như sau:
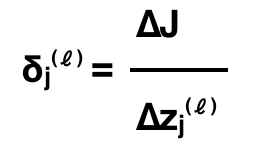
Cụ thể là error của neuron thứ j trên layer ℓ. Với ví dụ trên, error của neuron thứ 1 của layer 4 là
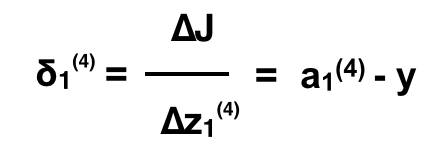
tương tự với các neurons khác:

Với mỗi layer có số lượng neuron lớn hơn 1 thì sai số của neuron của một layer sẽ được tinh thông qua tất cả các neuron của layer liền kế tiếp nó! (Không tính bias)
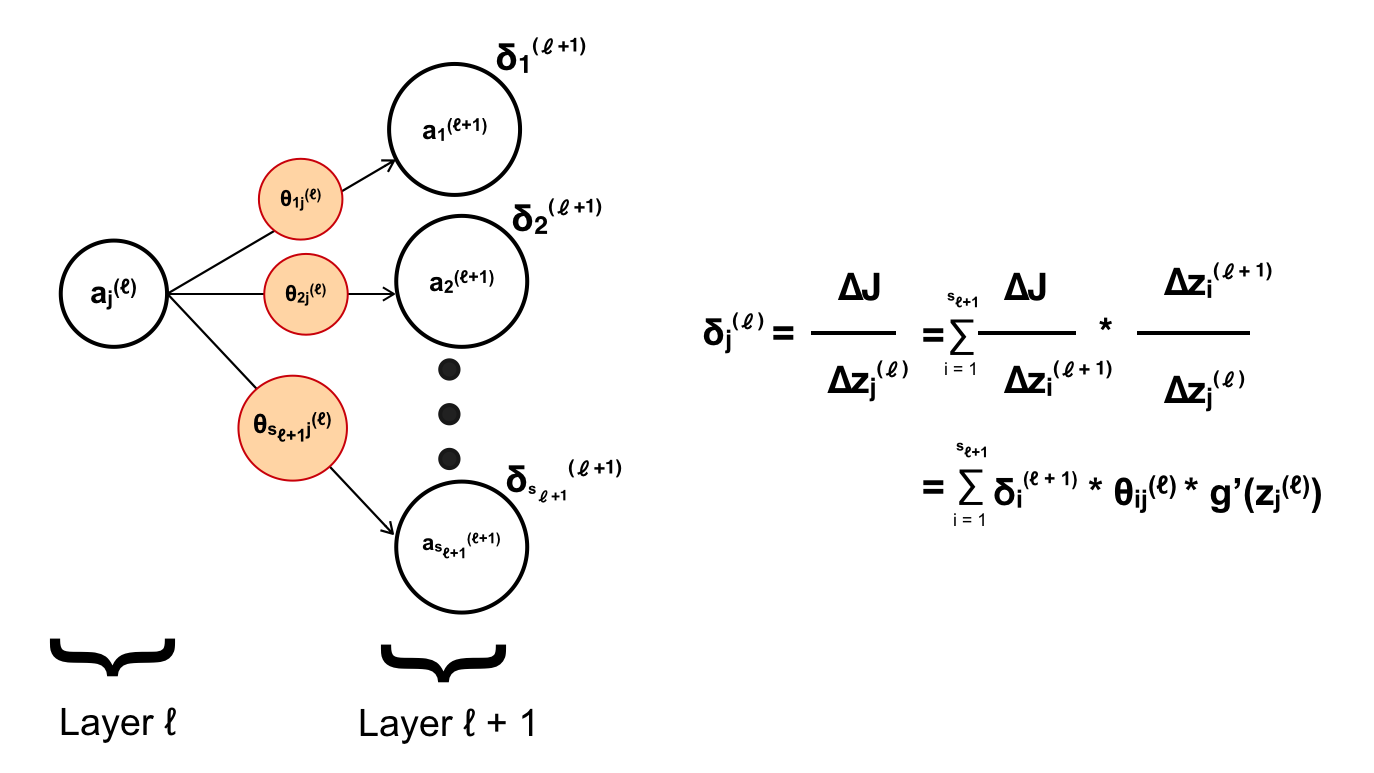
Nếu viết dưới dạng vector, layer ℓ sẽ có error là vector δ(ℓ), còn weight hay tham số từ neuron j layer ℓ tới layer ℓ + 1 sẽ là vector θjℓ, cụ thể:
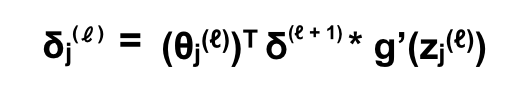
còn để tính error cho cả layer thì kết quả là:

Trong đó tham số của tất cả neuron trong một layer không còn là một vector như trên nữa mà là một matrix như ta đã nói trong phần 1, matrix θ có kích thước (sℓ+1) x (sℓ + 1) và δℓ+1 là vector sℓ+1. Bên cạnh đó phép toán ” . * ” là lấy từng phần tử của vector thu được sau khi nhân matrix θ và vector δ với các phần tử tương ứng của vector g'(z(ℓ)) (Đây là phép toán có trong MathLab, nếu các bạn có kinh nghiệm về nó thì chắc hẳn sẽ rất quen thuộc).
Và giờ để tính đạo hàm cho các θ, ta chỉ cần:
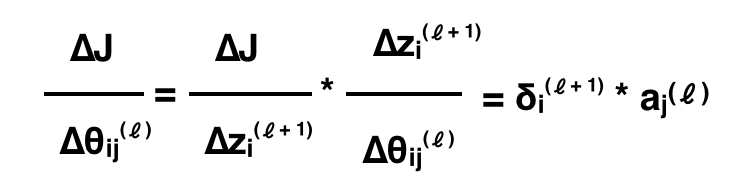
Đến đây thì chúng ta đã hiểu được cách tính đạo hàm riêng tại các tham số θ. Với việc tính toán δ ngược từ output layer giúp giảm thiểu chi phí tính toán và thuận tiện trong việc chuyển đổi tương ứng sang đạo hàm riêng của θ. Vậy là các bạn đã nắm được giải thuật Back Propagation, với đạo hàm riêng thu được, áp dụng vào giải thuật Gradient Descent ta sẽ tối ưu hoá được cost function và ANN đã học thành công 🙂
Sử dụng Cucumber để viết unit test trong Rails 3.2
So sánh tốc độ giữa VueJS vs ReactJS
