[ML – 13] How to design Machine Learning System
Trong bài viết trước chúng ta đã nắm được một vài phương pháp để “chẩn bệnh” cho hệ thống của mình. Đến thời điểm này, nhiều bạn sẽ đặt ra câu hỏi là làm sao để kết hợp những kĩ thuật đã được đề cập đến từ bài viết đầu tiên tới giờ (chẳng hạn các giải thuật, phát hiện Underfitting, Overfitting hay có nên thu thập thêm dữ liệu không…) lại với nhau. Nếu chỉ đơn thuần nắm được rất nhiều giải thuật mà không hiểu làm thế nào để chúng hoạt động trên một hệ thống hoàn chỉnh thì việc hiểu chúng chẳng có ý nghĩa gì ? Vậy làm sao để thiết kế một hệ thống ML ? Trong bài viết này, tôi sẽ đề cập đến những vấn đề chúng ta sẽ gặp phải trong quá trình xây dựng một “Machine Learning System” và cách đối mặt với chúng.
1. Pick project:
Vì ML hiện nay được ứng dụng trong rất nhiều lĩnh vực, được sử dụng để giải quyết rất nhiều vấn đề (chẳng hạn như lọc email rác, điều hướng quảng cáo phù hợp cho người dùng, computer vision, dự đoán các xu thế, xe tự lái, máy tự chơi game, xử lý ngôn ngữ tự nhiên…) nên việc lựa chọn một lĩnh vực phù hợp để bắt đầu dự án của mình là vô cùng quan trọng. MNIST – phân loại các chữ số viết tay, được coi là “Hello world!” trong ML, nếu là người mới bắt đầu, tôi khuyên bạn nên bắt đầu với dự án này vì bạn sẽ không phải lo về vấn đề dữ liệu, và không phải quá đau đầu khi lựa chọn feature (Do với mọi vấn đề về computer vision đều có input là ảnh – image). Bên cạnh đó bạn cũng có thể lựa chọn “Spam Email Classification” – phân loại mail rác, đơn giản bởi vì “rác” là thứ chúng ta không thiếu, chỉ cần đăng kí trên vài website, bạn đã có cả tấn mail rác trong hòm thư của mình sau vài ngày nên dữ liệu không phải là vấn đề. Theo tôi nếu như bạn muốn giảm thiểu được phần nào công việc của mình, bạn nên lựa chọn những dự án có tính chất phổ biến, dữ liệu dễ kiếm, vấn đề gặp phải dễ hiểu, vì nếu bạn chọn những vấn đề kiểu như xử lý ngôn ngữ tự nhiên, những vấn đề mang tính chất chuyên ngành như liên quan tới sinh học, y học, địa chất… thì ngay việc để hiểu vấn đề đã không phải là một chuyện đơn giản. Khi lựa chọn một dự án để phát triển, dù bạn chọn dễ hay khó, điều quan trọng nhất vấn là ta phải làm nó cho tới cùng, một dự án tuy đơn giản nhưng hoàn thiện còn có giá trị hơn chục dự án làm nửa vời. Như bản thân tôi bắt đầu với MNIST.
MNIST – Digit Classification: (Phân loại các chữ số viết tay)

2. Feautures selection :
Khi bắt đầu với một dự án ML, vấn đề đầu tiên ta gặp phải là làm sao xác định được nên sử dụng những feature nào ? Với những dự án mà dữ liệu của nó vốn dĩ không phải dạng số, thì bạn vẫn có thể chọn những feature không phải dạng số, sau đó số hoá cho chúng. Chẳng hạn với “Spam Classification”, ta có một email rác như sau:
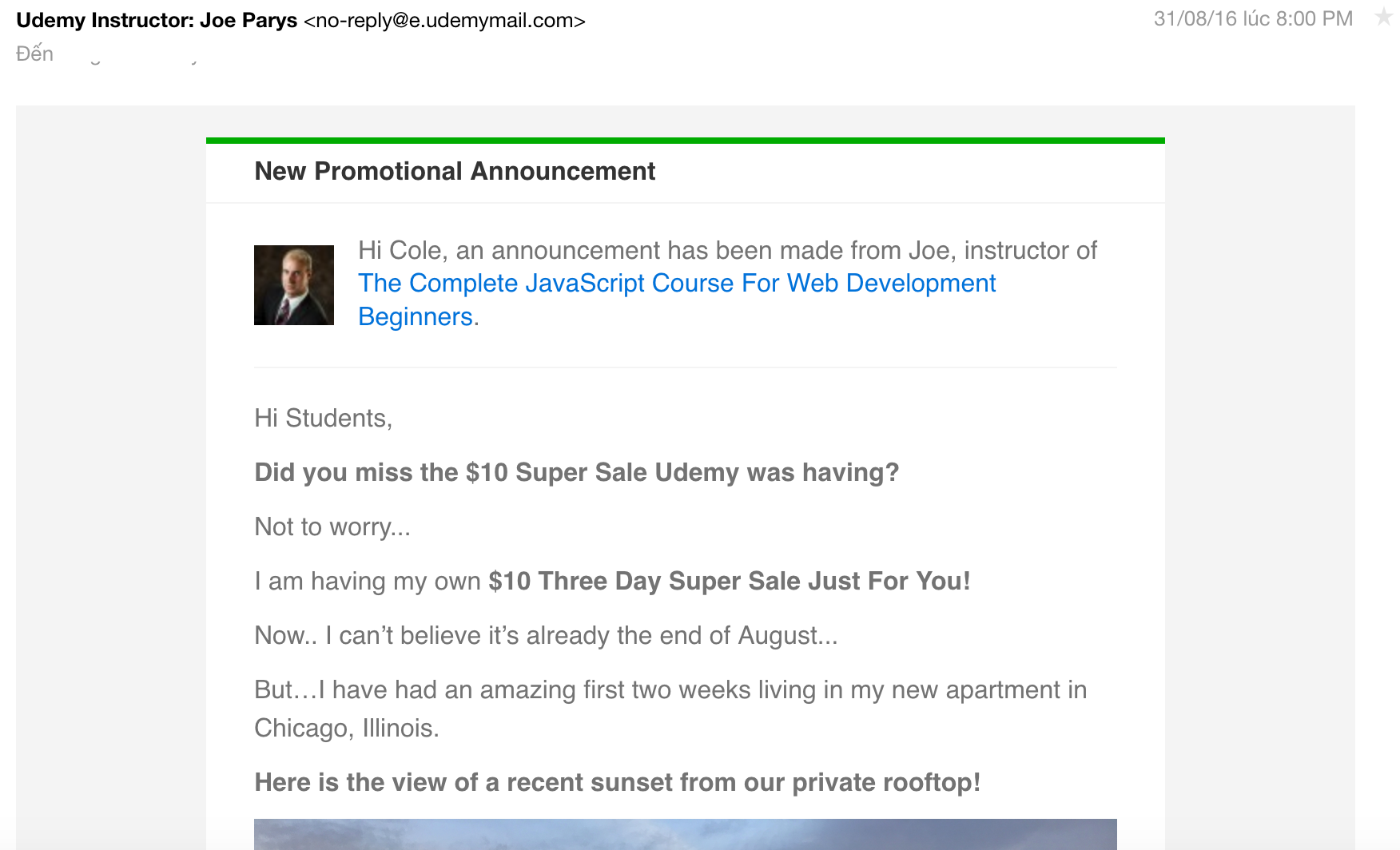
Ở đây dữ liệu ta có là text, đơn giản thì mỗi email được đại diện bởi nội dung text trong nó, phức tạp hơn thì có thêm người gửi (Sender), người nhận (Receiver – dĩ nhiên là những người không phải là bạn). Để ý rằng trong email rác, nội dung của chúng thường chứa một số từ hay cụm từ chung chung (nghĩa là chúng xuất hiện nhiều trong các email rác), chẳng hạn:
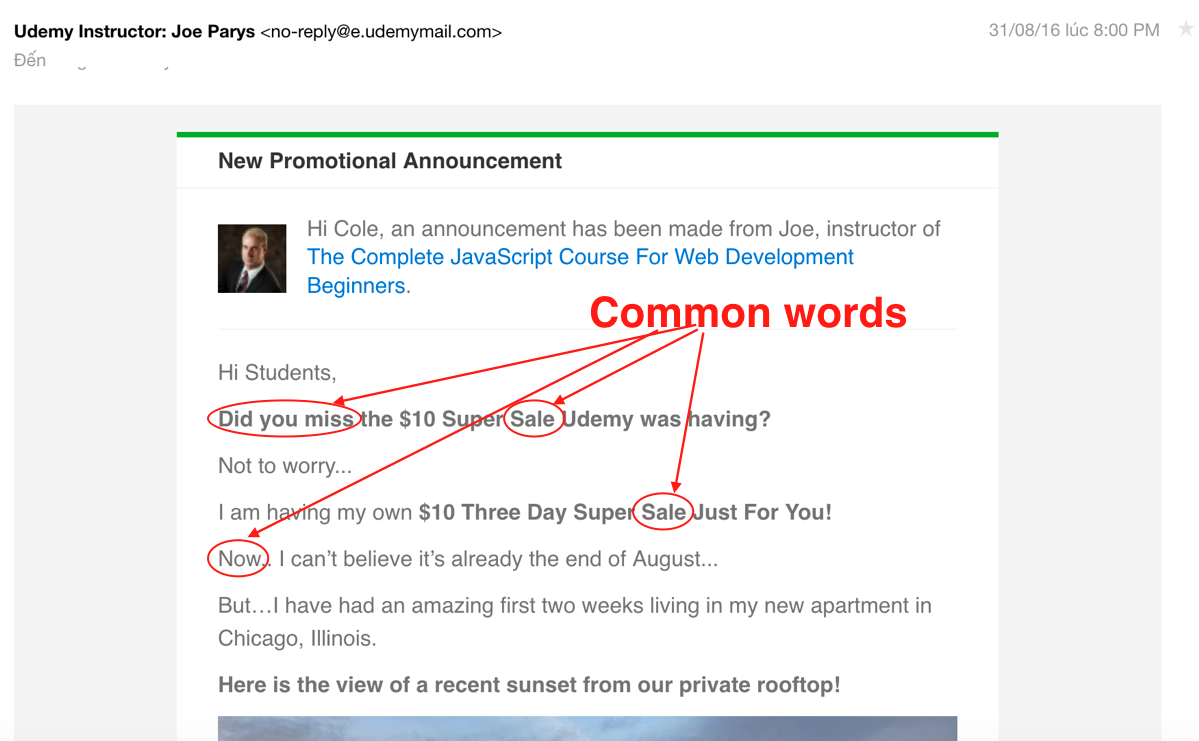
Ta có thể chọn những từ hay cụm từ này để xác định xem đó có phải thư rác hay không, bên cạnh đó để nhận diện thư gửi tới có phải thư thường không ta có thể chọn tương tự những từ hay cụm từ sẽ chỉ xuất hiện trong nội dung của thư thường. Thông thường để hệ thống hoạt động hiệu quả, ta sẽ chọn số lượng feature lớn một chút, chẳng hạn trong Spam Classification, ta hay chọn khoảng 10000-50000 từ để làm feature. Sau khi chọn được những từ mà ta nghĩ là cần thiết, hãy số hoá chúng bằng việc biến chúng thành vector. Chẳng hạn:
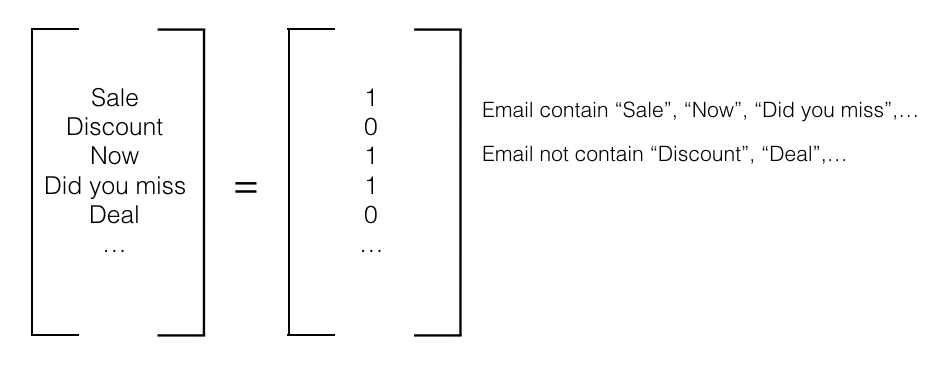
Mỗi từ được chọn hay một feature sẽ nhận giá trị 1 hoặc 0 tương ứng với “Có” hay “Không có” xuất hiện trong email. Với output ta chỉ cần gán 1 cho “Spam” và 0 cho “Not Spam”.
Một ví dụ khác với MNIST: dữ liệu ta có là một ảnh, để đơn giản, ta chọn ảnh đen trắng (binary image). Trong đó mỗi điểm ảnh chỉ bao gồm 1 số nguyên nhận giá trị là 0 hoặc 1, tương ứng đại diện cho màu đen hoặc trắng tại điểm ảnh đó. Mỗi bức ảnh sau khi số hoá trông sẽ như sau:
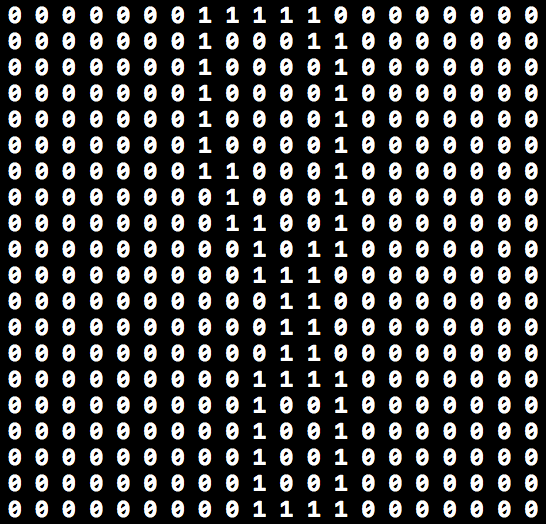
Với kích cỡ ảnh không lớn, ta có thể coi mỗi điểm ảnh là một feature (với ảnh màu RGB, mỗi điểm ảnh có thể cần tới 3 feature để đại diện cho nó) (Đối với những giải thuật phức tạp, chẳng hạn như CNN, ảnh sẽ được xử lý trước để trích xuất ra số lượng feature nhỏ hơn). Tuỳ vào từng vấn đề mà hệ thống của bạn cần giải quyết, ta có thể nên có cách lựa chọn feature khác nhau cho phù hợp.
3. Collecting Data :
Với những công ty lớn, chuyện này không quá khó khăn nhưng đối với cá nhân hay tổ chức nhỏ, đây là một công việc nặng nề, tốn kém nhiều thời gian, thậm chí khiến ta quên mất nhiệm vụ chính đang làm. Tuy nhiên không phải vấn đề nào cũng khó thu thập dữ liệu, chẳng hạn với Spam Classification, bạn có thể tạo tài khoản fake để đưa cho spammer, chỉ sau một vài ngày hay tuần, ta đã có cả đống dữ liệu. Hay với MNIST, cũng có những bộ dữ liệu có sẵn trên Google, nhưng tôi khuyên, các bạn nên lựa chọn nhiệm vụ cho hệ thống của mình phù hợp với lĩnh vực mà có thể thu thập dữ liệu dễ dàng. Bên cạnh đó việc brainstorm đôi khi cũng mang lại giải pháp hiệu quả thay vì cặm cụi thu thập data một cách cực khổ, thủ công. Một cách mà các “ông lớn” hay làm là publish một ứng dụng hay hệ thống nhỏ, và thu thập dữ liệu thông qua chúng, chẳng hạn vấn đề Computer Vision có thể thông qua các app về camera, như Baidu đưa ra ứng dụng “Face you” để có thêm nhiều hình ảnh về khuôn mặt người để giúp phát triển hệ thống nhận diện khuôn mặt hay AR.
4. Algorithm Selection & Error analysis:
Không giống như những vấn đề thông thường, ML không có khuôn mẫu chính xác cho việc lựa chọn giải thuật phù hợp. Những giải thuật ta đã và sẽ học không tương ứng 1:1 với bất kì vấn đề ML nào, vì vậy khi xây dựng hệ thống ta thường phải sử dụng nhiều thuật toán khác nhau. Những giải thuật đơn giản sẽ dễ dàng implement nhưng thường không hiệu quả, tuy nhiên cũng vẫn được sử dụng nhằm mục đích cho ta cái nhìn khái quát về vấn đề ta đang cố gắng giải quyết. Thông thường chúng ta sẽ dành khoang 24h đầu tiên để xây dựng một giải thuật đơn giản, sau đó test trên tập CV, phác hoạ Learning curve… để xác định xem máy có cần thêm dữ liệu để học không, có cần thêm hay bỏ bớt feature không. Có rất nhiều option để lựa chọn giúp improve ML system, nhưng thay vì “cảm thấy” nên chọn option nào thì ta nên để cho learning curve, test trên tập CV,.. những kĩ thuật ta đã được học đưa ra lý do ta nên làm gì.
Sau khi test hệ thống trên tập CV, áp dụng những kĩ thuật đã học hãy để ý xem, hệ thống của ta sai nhiều nhất ở những dữ liệu nào. Tiếp theo kiểm tra nhóm dữ liệu đó xem có gì nổi bật không ? Chẳng hạn khi ta test trên 500 email, và luôn có 100 email bị sai nhãn dù cho mọi cố gắng sử dụng những kĩ thuật đã biết. Khi đó ta nên kiểm tra xem 100 email đó có gì đặc biệt, có thể có những từ đặc trưng trong đó mà chưa được đưa vào làm feature hay lối viết không chính quy, sai chính tả…
5. Skewed analysis :
Nghe đến cụm từ “Skewed analysis” chắc hẳn các bạn sẽ thấy bỡ ngỡ ít nhiều, dịch ra đơn thuần là phân tích tính “lệch”. Ví dụ chúng ta có một Classification problem, ứng dụng Logistic Regression, thì ở ngưỡng h(x) = 0.5 là ngưỡng máy quyết định xem input đưa vào được gán nhãn “0”hay “1”. Nhưng không phải lúc nào ngưỡng quyết định cũng ở 0.5, h(x) là xác suất input của dữ liệu được gán nhãn = “1”, vậy nên xác suất bao nhiêu thì máy có thể chắc chắn nhãn = “1” trên thực tế ta không biết rõ có phải > 0.5 hay không. Chính vì lẽ đó nên ta cần phải kiểm tra xem ngưỡng thực tế nên là bao nhiêu để dự đoán chính xác nhãn cho input hơn. Để hiểu rõ hơn ta lấy một ví dụ cụ thể, chẳng hạn hệ thống với thông tin về bệnh nhân và đưa ra chẩn đoán người đó có bị ung thư hay không (Cancer Classification). Giả sử sau khi training, hệ thống chẩn đoán kết quả khá khả quan, đạt độ chính xác 99% trên tập CV nhưng số người mắc ung thư trên tập CV chỉ đạt 0.5%. Khi đó rõ ràng kết quả lại chẳng tốt chút nào… Vậy tại sao nhãn của dữ liệu lại bị lêch về 1 phía nhiều hơn phía còn lại ?
Lý do là bởi vì dữ liệu ta cung cấp cho máy học, rõ ràng lượng dữ liệu mẫu của một nhãn nhiều hơn hẳn của nhãn còn lại. Đến đây có thể nhiều bạn sẽ nghĩ, vậy chỉ cần đặt ngưỡng (threshold) ở độ chênh lệch giữa 2 nhãn (chẳng hạn số nhãn = 1 nhiều gấp đôi số nhãn = 0 -> threshold = 0.33 – h(x) > 0.33 thì nhãn = 1). Thực tế mọi chuyện không đơn giản như vậy, vì có thể có những dữ liệu cùng nhãn khá giống nhau nên gần như việc xảy ra với mẫu dữ liệu này cũng kéo theo dự đoán chính xác những mẫu khá giống còn lại đó. Chẳng hạn:

2 mẫu chữ viết trên chỉ khác nhau tại 1 điểm ảnh, khả năng cao sau khi học 2 mẫu dữ liệu này sẽ có giá trị h(x) gần nhau. Như vậy, việc xác định chính xác threshold không chỉ đơn thuần là kiểm tra tương quan số lượng dữ liệu giữa các nhãn, ta cần có phương pháp tốt hơn! Có thể các bạn sẽ nghĩ tương tự với cách ta đã làm với Regularization hay lượng data sử dụng để training, ta thử trên những ngưỡng khác nhau và lấy ngưỡng có kết quả dự đoán trên tập CV tốt nhất. Nhưng nếu làm như vậy đôi khi bạn sẽ thấy hệ thống của mình vẫn có thể không tốt như mong đợi… Hãy cùng tôi quan sát một chút:
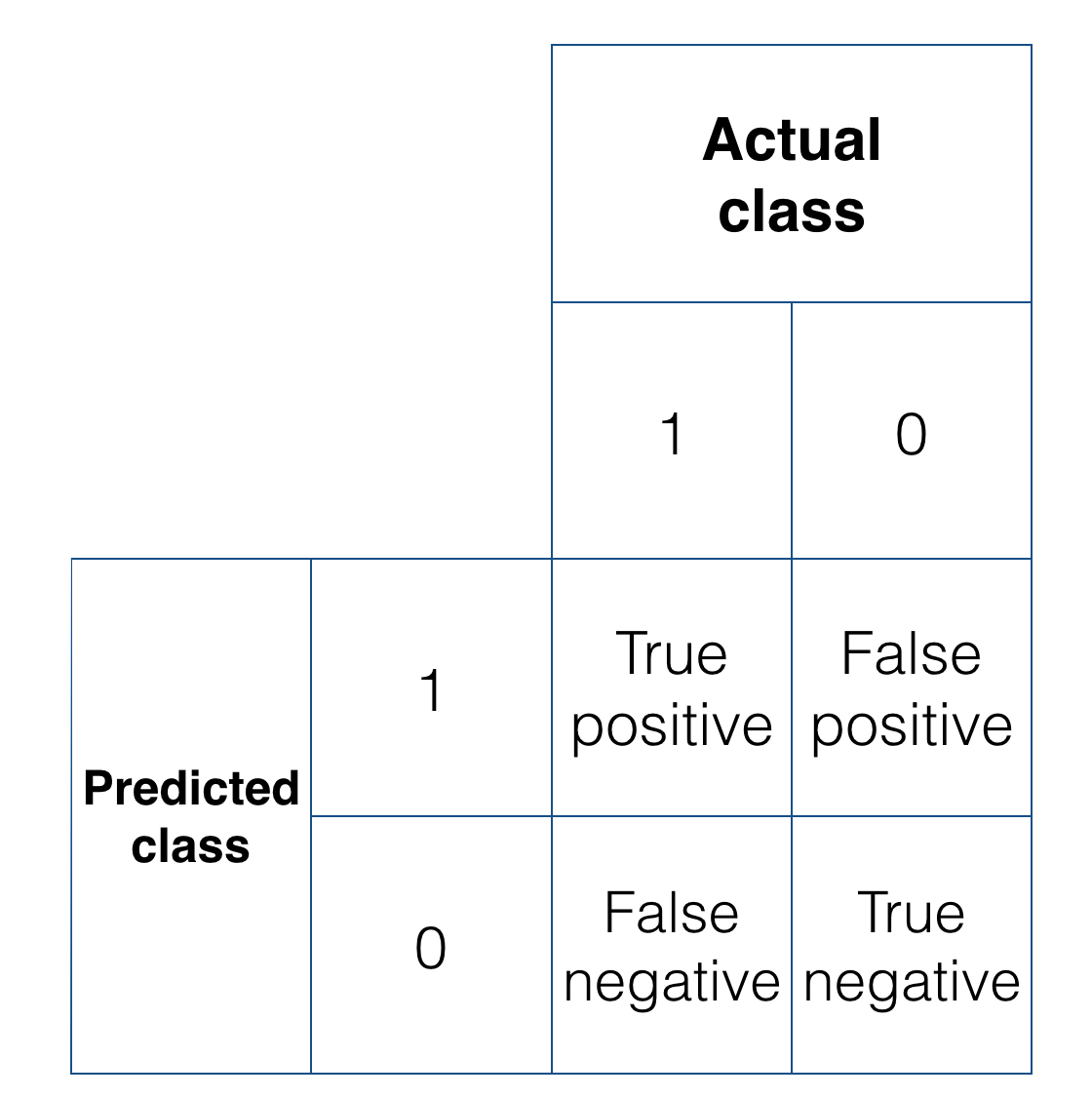
Hình trên cho là kết quả xác định nhãn của dữ liệu trong tập CV. Trong đó:
– Predicted Class: nhãn của dữ liệu được dự đoán bởi hệ thống của chúng ta.
– Actual Class: nhãn của dữ liệu trong thực tế
– True positive: những nhãn = “1” hệ thống dự đoán đúng (dự đoán = 1, thực tế = 1)
– True negative: những nhãn = “0” hệ thống dự đoán đúng (dự đoán = 0, thực tế = 0)
– False positive: những nhãn hệ thống dự đoán = “1” nhưng thực tế = “0”
– False negative: những nhãn hệ thống dự đoán = “0” nhưng thực tế = “1”
Ta xét 2 đại lượng mới Precision và Recall:

Precision thể hiện hệ thống của ta hay dự đoán sai nhãn “1” như thế nào. Vì khi Precision lớn tức là False positive nhỏ, hệ thống dự đoán sai ít nhãn “1” còn khi Precision nhỏ tức là False positive lớn. Precision càng lớn khả năng dự đoán sai nhãn “1” của hệ thống càng thấp -> Precision càng cao càng tốt.

Recall thể hiện hệ thống của ta hay dự đoán sai nhãn “0” như thế nào. Vì khi Recall lớn tức là False negative nhỏ, hệ thống dự đoán sai ít nhãn “0” còn khi Recall nhỏ tức là False negative lớn. Recall càng lớn khả năng dự đoán sai nhãn “0” của hệ thống càng thấp -> Recall càng cao càng tốt. Khi False positive hay False negative lớn hơn nhiều so với số còn lại hay Precision và Recall lớn hơn nhiều so với số còn lại là dấu hiệu cho ta thấy lượng nhãn trong training set đang bị lệch đáng kể về 1 loại. Vậy ta phải làm gì để xử lý chúng ?
Khi ta thay đổi threshold, xác suất cần đề xác định một nhãn sẽ nghiêng về 1 loại nhãn, hay nói cách khác hệ thống sẽ cần “tự tin hơn” khi xác định loại nhãn đó. Chẳng hạn threshold = 0.8 -> h(x) > 0.8 hệ thống mới kết luận label = “1” -> để kết luận nhãn = “1” hệ thống cần phải “rất tự tin” -> ít dữ liệu có nhãn “0” bị dự đoán là “1” hơn hay False positive thấp -> Precision lớn, nhưng bênh cạnh đó lượng dữ liệu đúng ra được gán nhãn “1” cũng bị gán nhãn = “0” ->False negative lớn -> Recall nhỏ. Ngược lại khi chọn threshole thấp thì Recall lớn nhưng Precision nhỏ.
Ta thay đổi threshold và xem sự thay đổi của Precision và Recall sẽ ra sao:
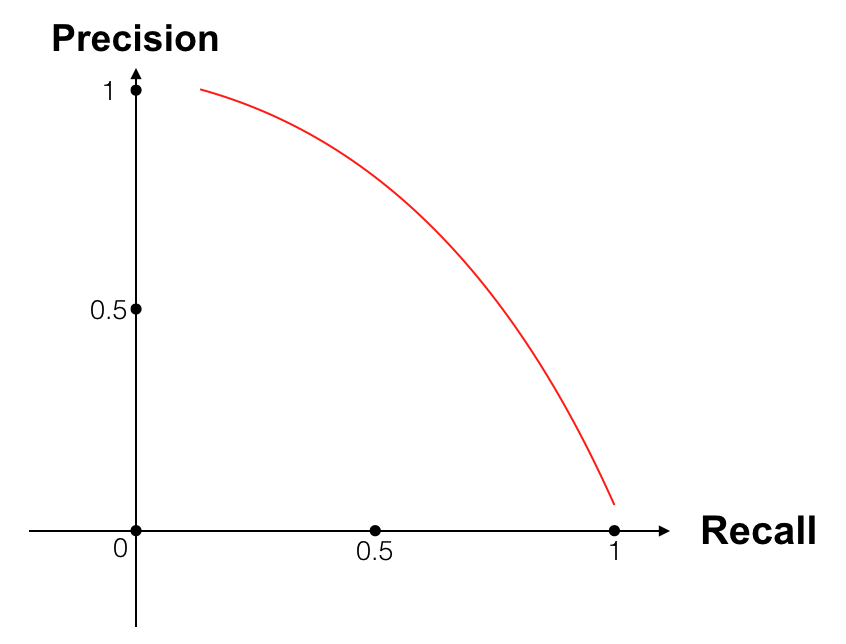
Khi đặt Precision và Recall lên đồ thị, ta có thể thấy được sự thay đổi của chúng khi threshold thay đổi, tuy nhiên vẫn chưa giúp ta biết được tại threshold nào thì hệ thống không bị ảnh hưởng bởi sự thiếu cân bằng về số lượng các nhãn. Bởi vì Precision và Recall là 2 đại lượng không phải chỉ 1 số thực duy nhất, nên ta cần một cách tính trung bình (mean) của chúng. Nếu mean ở đây là trung bình cộng: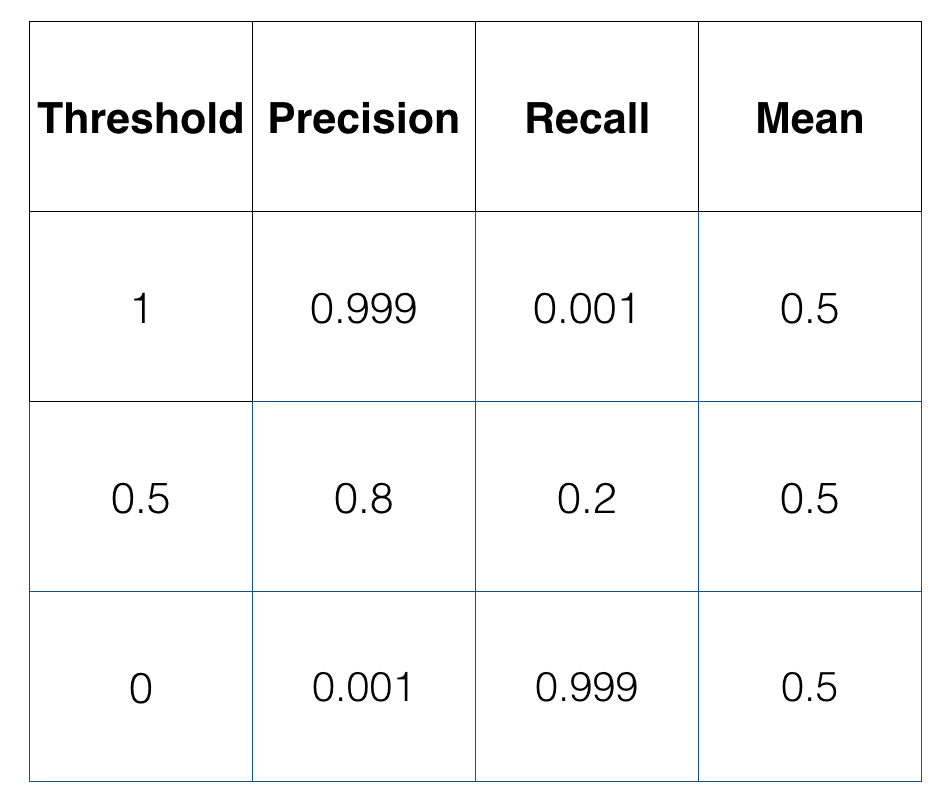
Cùng với mean = 0.5 ta có tới 3 threshold tương ứng, có vẻ không hiệu quả lắm. Ta estimate sai lệch của các nhãn thông qua F1 score (hoặc F score) như sau:
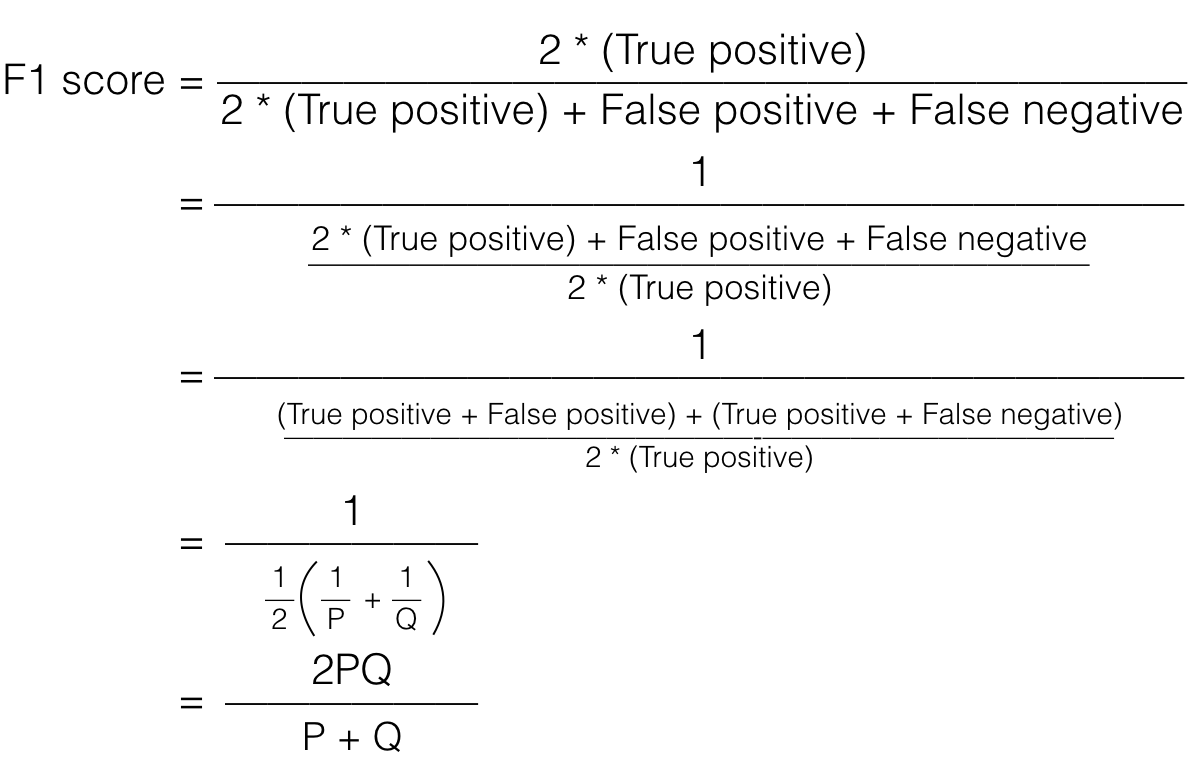
F score chính là Harmonic Mean của Precision và Recall, nó phản ánh cho ta thấy tổng lượng False positive và False negative là bao nhiêu, khi F score lớn, thì số lượng nhãn dự đoán sai nhỏ. Khi nhận thấy có dấu hiệu của sự sai lệch loại nhãn, ta thay đổi threshold sao cho F score lớn.
6. Recap :
Trên đây là một số vấn đề các bạn có thể sẽ gặp phải khi thiết kế một ML system, ngoài những vấn đề về High bias, High variance ta đã biết một vài cách xử lý khi lựa chọn feature, thu thập data, data skewed… Hi vọng đến đây, dù chúng ta chưa hiểu được những giải thuật phức tạp hiện nay nhưng ta đã hiểu công việc ta cần làm với một vấn đề của ML, biết tính nhưng đại lượng để phản ánh vấn đề trong hệ thống. Để đi xa hơn, có thể hiểu được những nội dung của những giải thuật mới, kĩ thuật xử lý mới, tôi tin rằng chúng ta cần trang bị thêm cho mình những kiến thức về toán học đặc biệt là Calculus và Statistic. Trong những bài viết sau, có thể chúng ta sẽ tìm hiểu chúng trước khi cùng nhau tìm hiểu những kiến thức mới của ML. Hẹn gặp lại các bạn trong những bài viết sau!

Speed up your website