[ML – 17] Neural Net Regularization with Drop-Out
Chào các bạn, rất vui được gặp lại các bạn trong bài viết này. Hôm nay chúng ta sẽ tìm hiểu về một kĩ thuật Regularization cho ANN được gọi là Drop-Out. Thay vì đi vào tìm hiểu “đạo lý” đằng sau kĩ thuật này hay phân phối xác suất đằng sau nó, tôi sẽ giải thích một cách trực quan để các bạn dễ hiểu, dễ nắm bắt và mường tượng được ý nghĩa của nó.
1. Drop-Out là gì:
Như ta đã biết overfitting là một vấn nạn đối với Machine Learning, đặc biệt là trong mạng NN. Khi muốn cho mô hình trở nên phức tạp hơn, ta thường tăng số lượng layer và số lượng unit của mỗi layer thay vì tăng bậc của feature như trước đây đã đề cập. Nhưng khi mô hình phức tạp hơn, overfitting bắt đầu xuất hiện, vì số lượng tham số trong mạng NN nhiều và có “độ sâu” khác nhau, vì vậy khi áp dụng chung ? cho tất cả các tham số sẽ yêu cầu số lần training lớn để tìm được ? phù hợp. Có một kĩ thuật dành riêng cho mạng NN và khá đơn giản, đó là Drop-out (một kĩ thuật khác được biết đến tương tự là Drop-Connect).
Drop-out là một kĩ thuật Regularization để chống lại vấn đề overfitting. Cách Drop-out thực hiện là xoá bỏ một số unit trong các step training ứng với một giá trị xác suất p cho trước.
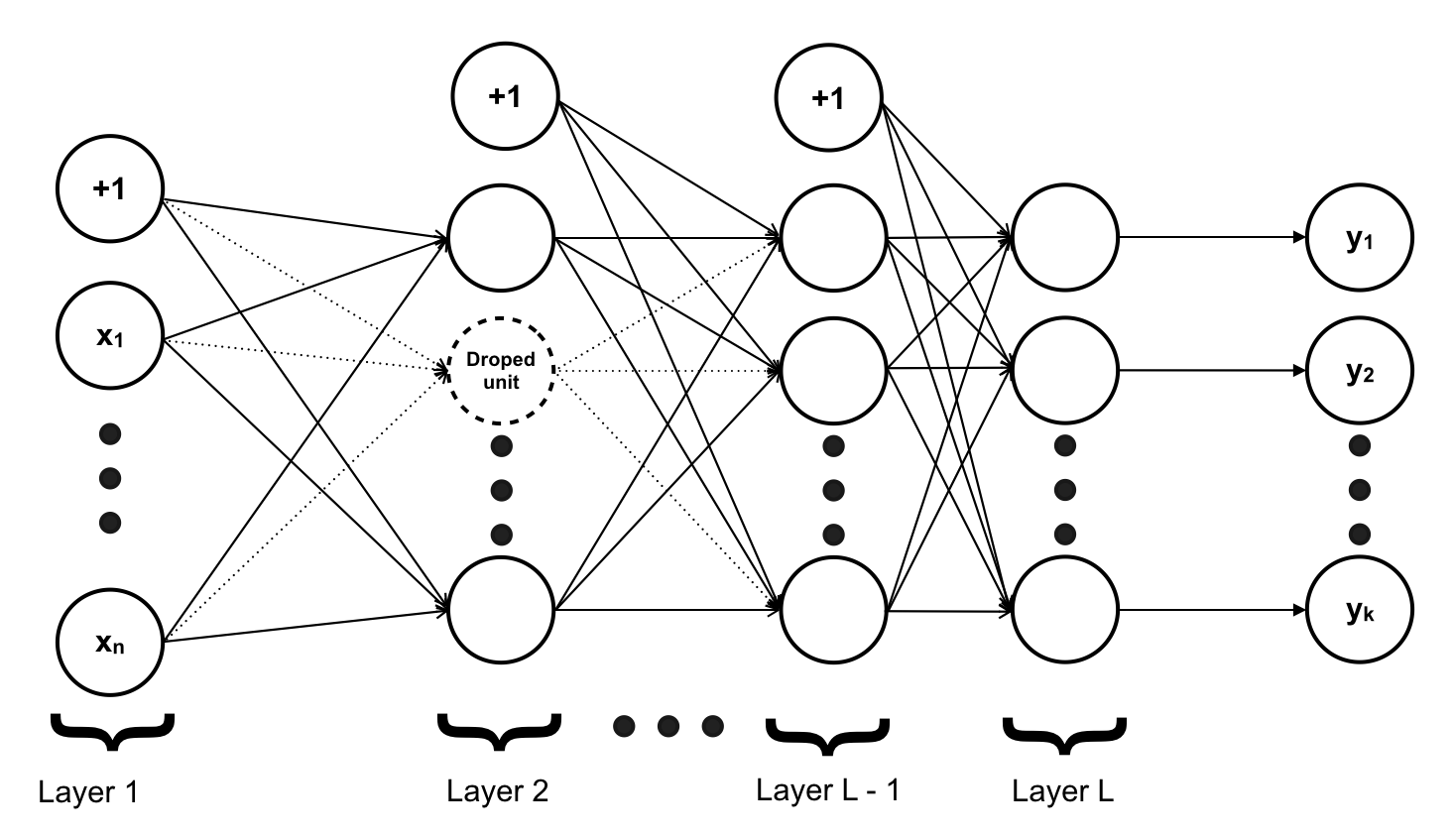
2. Drop-Out hoạt động như thế nào:
- Drop-Out được áp dụng trên một layer của mạng NN với một xác suất p cho trước (ta có thể sử dụng nhiều Drop-Out khác nhau cho những layer khác nhau, nhưng trên 1 layer sẽ chỉ có 1 Drop-Out).
- Tại mỗi step trong quá trình training, khi thực hiện Forward Propagation (Lan truyền xuôi) đến layer sử dụng Drop-Out, thay vì tính toán tất cả unit có trên layer, tại mỗi unit ta “gieo xúc xắc” xem unit đó có được tính hay không dựa trên xác suất p. Với những unit được tính, ta tính toán bình thường còn với những unit không được tính giá trị tại unit đó = 0.
- Khi thực hiện tính toán trên mạng NN trong quá trình test (sử dụng mạng NN để dự đoán) thay vì làm như trên, ta thực hiện tính toán trên tất cả các unit nhưng trọng số trên mỗi connect đến các unit của layer được áp dụng Drop-Out được thay thế bằng giá trị của trọng số đó với xác suất p hay θ := θ * p
3. Tại sao Drop-Out hiệu quả:
Đối với mạng NN, không giống như những kĩ thuật khác như Linear Regression hay Logistic Regression là đẩy bậc của feature lên mà ta tăng số lượng hidden layer và số lượng unit trong các layer lên. Nhưng đối khi do việc thêm vào quá nhiều hidden layer cũng như unit khiến cho mô hình phức tạp hơn mức cần thiết và khiến chúng bị overfitting. Chính vì vậy để tránh bị overfitting trong trường hợp này, ta cần phải giản lược mạng NN hiện có. Khi áp dụng Drop-Out vào 1 layer nào đó, thì thực tế tại mỗi training step mạng NN của ta chỉ còn 1 phần:
Giả sử layer của ta có 4 unit (như trong clip minh hoạ), và xác suất p = 0.8 -> khi đó xác suất sử dụng số lượng unit của layer sẽ như sau:
– Sử dụng 0 unit của layer: = (1-p)4 = 0.24 = 0.0016(Vì xác suất để mỗi unit không được sử dụng là 1-p nên để cả 4 unit không được sử dụng thì xác suất phải là (1-p)4)
– Sử dụng 1 unit của layer: = 4 * p * (1-p)3 = 4 * 0.8 * 0.23 = 0.0256(Vì xác suất để mỗi unit không được sử dụng là 1-p nên để 3 unit không được sử dụng thì xác suất phải là (1-p)3 và có thêm 1 unit được sử dụng với xác suất p, bên cạnh đó có tới 4 unit có thể được chọn để sử dụng)
– Tương tự khi sử dụng 2 unit của layer: = 6 * p2 * (1-p)2 = 6 * 0.82 * 0.2 2 = 0.1536 (có 6 cách để lựa chọn 2 unit để sử dụng trong 4 unit của layer)
– Khi sử dụng 3 unit của layer: = 4 * p3 * (1-p) = 4 * 0.83 * 0.2 = 0.4096 (có 4 cách để lựa chọn 3 unit để sử dụng trong 4 unit của layer)
– Khi sử dụng 4 unit của layer: = p4 * = 0.84= 0.4096 (chỉ có 1 cách để lựa chọn 4 unit để sử dụng trong 4 unit của layer)
Tính trung bình ra ta có số lượng unit layer sử dụng khi áp dụng Drop-Out: 0 * 0.0016 + 1 * 0.0256 + 2 * 0.1536 + 3 * 0.4096 + 4 * 0.4096 = 3.2 = 4 * 0.8 = 4 * p (Số lượng unit nhân với xác suất p). Nghĩa là khi áp dụng Drop-Out layer của ta chỉ sử dụng số unit tương đương 3.2 bằng cách sử dụng nhiều mạng nhỏ (với 0,1,2,3,4 unit trong layer như mô tả ở trên)
Cuối cùng, các bạn sẽ thắc mắc tại sao khi sử dụng mạng NN để test ta lại không “gieo xúc xắc” như khi training mà lại sử dụng trọng số có giá trị bị giảm đi theo xác suất p. Đơn giản là vì khi các unit được sử dụng với xác suất như trên, các trọng số cũng được update với tỉ lệ tương tự, nên để thay vì phải tính kết quả trên tất các mạng con bằng cách “gieo xúc sắc”, ta thực hiện approximate giá trị trung bình của tất cả các mạng con bằng cách scale θ theo p.
Issuing free HTTPS certificate with Let’s encrypt