Tìm hiểu Pandas (Bài 3): Group, Merge dữ liệu
 Ở bài này, ta sẽ giải quyết câu hỏi làm thế nào để sắp xếp lại cấu trúc dữ liệu phục vụ cho mục đích phù hợp. Ta sẽ sử dụng một số hàm phổ biến như: groupby, concat, aggregate, append,.. qua các ví dụ với tập dữ liệu thực để hiểu rõ hơn. (Các ví dụ được thao tác trên python 3.7.0 và pandas 0.23.4)
Ở bài này, ta sẽ giải quyết câu hỏi làm thế nào để sắp xếp lại cấu trúc dữ liệu phục vụ cho mục đích phù hợp. Ta sẽ sử dụng một số hàm phổ biến như: groupby, concat, aggregate, append,.. qua các ví dụ với tập dữ liệu thực để hiểu rõ hơn. (Các ví dụ được thao tác trên python 3.7.0 và pandas 0.23.4)
Các mục thảo luận gồm:
- Nhóm dữ liệu (grouping of data)
- Nối dữ liệu (merging and concatenating data)
I. Nhóm dữ liệu (grouping of data)
Groupby là phép toán thực hiện trên DataFrames, khi thực thi sẽ thực hiện 3 việc:
- Chia tập dữ liệu
- Phân tích dữ liệu
- Nhóm dữ liệu
Hàm groupby:
DataFrame.groupby(by=None, axis=0, level=None, as_index=True, sort=True, group_keys=True, squeeze=False, observed=False, **kwargs)
Tham số thường dùng:
- by : mapping, function, label, hoặc danh sách các label. Xác định nhóm để groupby.
- axis : int, 0: group theo hàng, 1: group theo cột (mặc định 0)
- level : int/string, chỉ số level hoặc tên cột, mặc định None. Sử dụng với MultiIndex, để chỉ rõ lấy index nào
- as_index : boolean, mặc định True. Giá trị True: kết quả trả về column được group sẽ là key.
- sort : boolean, mặc định True. Sắp xếp key, để tăng hiệu suất thì hãy để False.
Group một cột
Giờ cùng thử thao tác với tập dữ liệu các đội bóng vô địch UEFA Champions League: euro_winners.csv
In [1]: import pandas as pd
uefaDF=pd.read_csv('./euro_winners.csv')
In [2]: uefaDF.head()
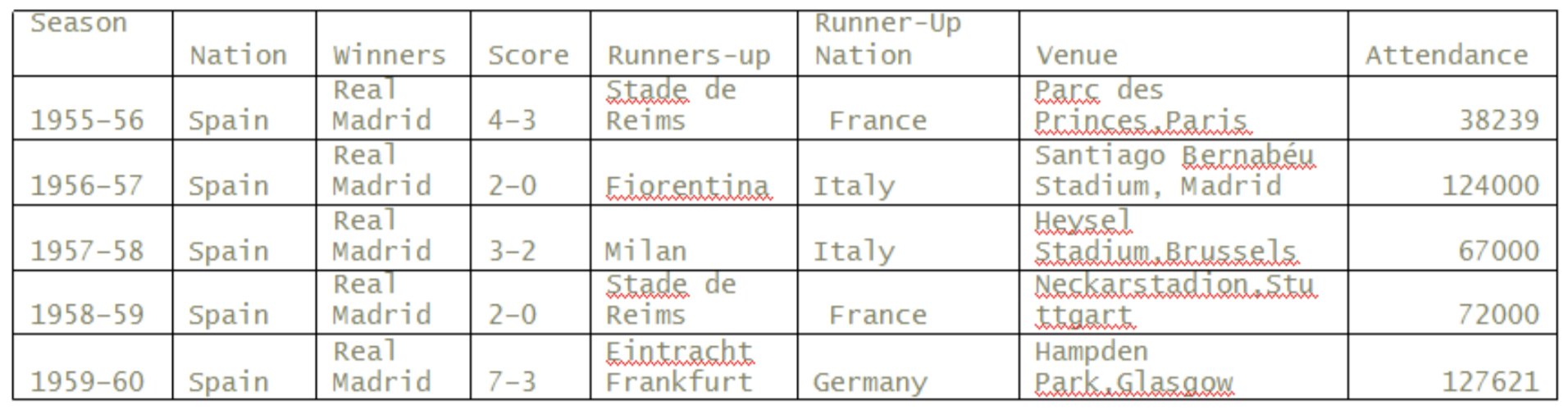
In [4]: nationsGrp=uefaDF.groupby('Nation');
type(nationsGrp)
Out[5]: pandas.core.groupby.DataFrameGroupByKiểu của nationsGrp là pandas.core.groupby.DataFrameGroupBy. Cột được sử dụng để groupby sẽ là key. Sử dụng thuộc tính “groups”:
In [6]: nationsGrp.groups
Out[7]:{'England': IntIndex64([12, 21, 22, 23, 24, 25, 26, 28, 43, 49, 52, 56], dtype='int64'),
'France':IntIndex64([37], dtype='int64'),
'Germany':IntIndex64([18, 19, 20, 27, 41, 45, 57], dtype='int64'),
'Italy':IntIndex64([7, 8, 9, 13, 29, 33, 34, 38, 40, 47, 51, 54], dtype='int64'),
'Netherlands':IntIndex64([14, 15, 16, 17, 32, 39], dtype='int64'),
'Portugal':IntIndex64([5, 6, 31, 48], dtype='int64'),
'Romania':IntIndex64([30], dtype='int64'),
'Scotland':IntIndex64([11], dtype='int64'),
'Spain':IntIndex64([0, 1, 2, 3, 4, 10, 36, 42, 44, 46, 50, 53, 55], dtype='int64'),
'Yugoslavia':IntIndex64([35], dtype='int64')}Về cơ bản, đây là dạng dictionary cho thấy tên nhóm riêng biệt và index tương ứng.
Để lấy được số quốc gia có FC vô địch (số lượng group), số FC vô địch theo từng nước (số lượng bản ghi trong từng group):
In [8]: len(nationsGrp.groups)
Out[9]: 10
In [10]: nationWins=nationsGrp['Winners'].count();
nationWins
Out[11]:
Nation
England 12
France 1
Germany 7
Italy 12
Netherlands 6
Portugal 4
Romania 1
Scotland 1
Spain 13
Yugoslavia 1
dtype: int64Để đưa về dạng DataFrame, sử dụng reset_index()
In [12]: nationWins.reset_index(name='FC_count')
Out[13]:
Nation FC_count
0 England 12
1 France 1
2 Germany 7
3 Italy 12
4 Netherlands 6
5 Portugal 4
6 Romania 1
7 Scotland 1
8 Spain 13
9 Yugoslavia 1Thuộc tính ‘name‘ để thay đổi tên cột kết quả, ở đây là số lượng FC vô địch.
Thay vì sử dụng hàm reset_index(), ta có thể sử dụng thuộc tính as_index =False khi groupby cũng sẽ cho kết quả tương đương.
In [14]: nationsGrp=uefaDF.groupby('Nation', as_index=False)['Winners'].count();Group nhiều cột
Để xem số lần vô địch của từng FC theo từng quốc gia:
In [15]: winnersGrp =uefaDF.groupby(['Nation','Winners'])
clubWins=winnersGrp.size()
clubWins
Out[16]:
Nation Winners
England Aston Villa 1
Chelsea 1
Liverpool 5
Manchester United 3
Nottingham Forest 2
France Marseille 1
Germany Bayern Munich 5
Borussia Dortmund 1
Hamburg 1
Italy Internazionale 3
Juventus 2
Milan 7
Netherlands Ajax 4
Feyenoord 1
PSV Eindhoven 1
Portugal Benfica 2
Porto 2
Romania Steaua Bucure?ti 1
Scotland Celtic 1
Spain Barcelona 4
Real Madrid 9
Yugoslavia Red Star Belgrade 1
dtype: int64
Một chút khác biệt so với khi group một cột đó là group nhiều cột thì các cột này phải được đưa dưới dạng list (trong dấu [])
Như vậy bước đầu ta có thể hiểu được cách hoạt động của groupby và cách sử dụng.
Group với MultiIndex
Ta có thể group by theo level với DataFrame có MultiIndex. Dữ liệu: goal_stats_euro_leagues_2012-13.csv
In [17]: goalStatsDF=pd.read_csv('./goal_stats_euro_leagues_2012-13.csv')
goalStatsDF=goalStatsDF.set_index(['Month','Stat'])
goalStatsDF
Out[18]:
EPL La Liga Serie A Bundesliga
Month Stat
08/01/2012 MatchesPlayed 20.0 20 10.0 10.0
09/01/2012 MatchesPlayed 38.0 39 50.0 44.0
10/01/2012 MatchesPlayed 31.0 31 39.0 27.0
11/01/2012 MatchesPlayed 50.0 41 42.0 46.0
12/01/2012 MatchesPlayed 59.0 39 39.0 26.0
01/01/2013 MatchesPlayed 42.0 40 40.0 18.0
02/01/2013 MatchesPlayed 30.0 40 40.0 36.0
03/01/2013 MatchesPlayed 35.0 38 39.0 36.0
04/01/2013 MatchesPlayed 42.0 42 41.0 36.0
05/01/2013 MatchesPlayed 33.0 40 40.0 27.0
06/02/2013 MatchesPlayed NaN 10 NaN NaN
08/01/2012 GoalsScored 57.0 60 21.0 23.0
09/01/2012 GoalsScored 111.0 112 133.0 135.0
10/01/2012 GoalsScored 95.0 88 97.0 77.0
11/01/2012 GoalsScored 121.0 116 120.0 137.0
12/01/2012 GoalsScored 183.0 109 125.0 72.0
01/01/2013 GoalsScored 117.0 121 104.0 51.0
02/01/2013 GoalsScored 87.0 110 100.0 101.0
03/01/2013 GoalsScored 91.0 101 99.0 106.0
04/01/2013 GoalsScored 105.0 127 102.0 104.0
05/01/2013 GoalsScored 96.0 109 102.0 92.0
06/01/2013 GoalsScored NaN 80 NaN NaNTheo thứ tự set index: Month = 0, Stat = 1 nên khi group theo level = 1 hay level = ‘Stat’ sẽ đều cho kết quả tương đương.
In [19]: monthStatGroup=goalStatsDF.groupby(level=1).count()
monthStatGroup
Out[20]:
EPL La Liga Serie A Bundesliga
Stat
GoalsScored 10 11 10 10
MatchesPlayed 10 11 10 10Thao tác với hàm aggregate:
In [21]: import numpy as np
monthStatGroup=goalStatsDF.groupby(level='Stat')
monthStatGroup.agg(np.sum)
Out[22]:
EPL La Liga Serie A Bundesliga
Stat
GoalsScored 1063.0 1133 1003.0 898.0
MatchesPlayed 380.0 380 380.0 306.0Chú ý rằng giá trị NaN sẽ không được tính trong phép toán agg.
Có thể truyền nhiều hàm cùng lúc:
In [23]: monthStatGroup.agg([np.sum, np.mean,np.size])
Out[24]:
EPL La Liga Serie A \
sum mean size sum mean size sum mean
Stat
GoalsScored 1063.0 106.3 11.0 1133 103.000000 11 1003.0 100.3
MatchesPlayed 380.0 38.0 11.0 380 34.545455 11 380.0 38.0
Bundesliga
size sum mean size
Stat
GoalsScored 11.0 898.0 89.8 11.0
MatchesPlayed 11.0 306.0 30.6 11.0Cũng thể chỉ định cột nào sử dụng hàm nào
In [25]: monthStatGroup.agg({'EPL':np.sum, 'La Liga':np.mean})
Out[26]:
La Liga EPL
Stat
GoalsScored 103.000000 1063.0
MatchesPlayed 34.545455 380.0II. Nối dữ liệu (merging and concatenating of data)
Hàm concat
Hàm concat dùng để nối các dữ liệu cấu trúc pandas với nhau.
pandas.concat(objs, axis=0, join=’outer’, join_axes=None, ignore_index=False, keys=None, levels=None, names=None, verify_integrity=False, copy=True)
Tham số thường dùng:
- objs: danh sách các object Series, DataFrame, hoặc Panel
- axis: int, 0: concat theo cột, 1: concat theo hàng (mặc định 0)
- join: inner/outer (mặc định outer)
- ignore_index: boolean (mặc định False), giá trị True: giá trị index sẽ không được sử dụng trong khi concat. Kết quả trả về index được đánh lại từ 0
In [1]: df1 = pd.DataFrame({'A': ['A0', 'A1', 'A2', 'A3'],
...: 'B': ['B0', 'B1', 'B2', 'B3'],
...: 'C': ['C0', 'C1', 'C2', 'C3'],
...: 'D': ['D0', 'D1', 'D2', 'D3']},
...: index=[0, 1, 2, 3])
In [2]: df2 = pd.DataFrame({'A': ['A4', 'A5', 'A6', 'A7'],
...: 'B': ['B4', 'B5', 'B6', 'B7'],
...: 'C': ['C4', 'C5', 'C6', 'C7'],
...: 'D': ['D4', 'D5', 'D6', 'D7']},
...: index=[4, 5, 6, 7])
...:
In [3]: df3 = pd.DataFrame({'A': ['A8', 'A9', 'A10', 'A11'],
...: 'B': ['B8', 'B9', 'B10', 'B11'],
...: 'C': ['C8', 'C9', 'C10', 'C11'],
...: 'D': ['D8', 'D9', 'D10', 'D11']},
...: index=[8, 9, 10, 11])
...:
In [4]: pd.concat([df1, df3, df2])
A B C D
0 A0 B0 C0 D0
1 A1 B1 C1 D1
2 A2 B2 C2 D2
3 A3 B3 C3 D3
8 A8 B8 C8 D8
9 A9 B9 C9 D9
10 A10 B10 C10 D10
11 A11 B11 C11 D11
4 A4 B4 C4 D4
5 A5 B5 C5 D5
6 A6 B6 C6 D6
7 A7 B7 C7 D7Sử dụng ignore_index:
In [5]: pd.concat([df1, df3, df2], ignore_index=True)
A B C D
0 A0 B0 C0 D0
1 A1 B1 C1 D1
2 A2 B2 C2 D2
3 A3 B3 C3 D3
4 A8 B8 C8 D8
5 A9 B9 C9 D9
6 A10 B10 C10 D10
7 A11 B11 C11 D11
8 A4 B4 C4 D4
9 A5 B5 C5 D5
10 A6 B6 C6 D6
11 A7 B7 C7 D7
Sử dụng logic để nối, nếu không chỉ định tham số join thì mặc định là sẽ ‘outer’
In [6]: df4 = pd.DataFrame({'B': ['B2', 'B3', 'B6', 'B7'],
...: 'D': ['D2', 'D3', 'D6', 'D7'],
...: 'F': ['F2', 'F3', 'F6', 'F7']},
...: index=[2, 3, 6, 7])
...:
In [7]: pd.concat([df1, df4], axis=1)
A B C D B D F
0 A0 B0 C0 D0 NaN NaN NaN
1 A1 B1 C1 D1 NaN NaN NaN
2 A2 B2 C2 D2 B2 D2 F2
3 A3 B3 C3 D3 B3 D3 F3
6 NaN NaN NaN NaN B6 D6 F6
7 NaN NaN NaN NaN B7 D7 F7Chỉ định tham số join=’inner’:
In [8]: result = pd.concat([df1, df4], axis=1, join='inner')
In [9]: result
A B C D B D F
2 A2 B2 C2 D2 B2 D2 F2
3 A3 B3 C3 D3 B3 D3 F3Hàm append
Hàm append là phiên bản đơn giản của hàm concat với axis=0
DataFrame.append(other, ignore_index=False, verify_integrity=False, sort=None)
Tham số thường dùng:
- other: danh sách object DataFrame hoặc Series/Dictionary
- ignore_index: boolean (mặc định False), giá trị True: giá trị index sẽ không được sử dụng
In [10]: df1.append(df4, ignore_index=True)
A B C D F
0 A0 B0 C0 D0 NaN
1 A1 B1 C1 D1 NaN
2 A2 B2 C2 D2 NaN
3 A3 B3 C3 D3 NaN
4 NaN B2 NaN D2 F2
5 NaN B3 NaN D3 F3
6 NaN B6 NaN D6 F6
7 NaN B7 NaN D7 F7Chú ý: hàm concat và append đều không thay đổi df1, mà chỉ tạo ra bản copy với phần df4 đã được nối
Append row vào DataFrame
Kiểu Series/Dictionary:
In [11]: s2 = pd.Series(['X0', 'X1', 'X2', 'X3'], index=['A', 'B', 'C', 'D'])
In [12]: df1.append(s2, ignore_index=True)
A B C D
0 A0 B0 C0 D0
1 A1 B1 C1 D1
2 A2 B2 C2 D2
3 A3 B3 C3 D3
4 X0 X1 X2 X3
Kiểu Dictionary:
In [13]: dicts = [{'A': 1, 'B': 2, 'C': 3, 'X': 4},
....: {'A': 5, 'B': 6, 'C': 7, 'Y': 8}]
....:
In [14]: df1.append(dicts, ignore_index=True)
A B C D X Y
0 A0 B0 C0 D0 NaN NaN
1 A1 B1 C1 D1 NaN NaN
2 A2 B2 C2 D2 NaN NaN
3 A3 B3 C3 D3 NaN NaN
4 1 2 3 NaN 4.0 NaN
5 5 6 7 NaN NaN 8.0SQL-like merging/joining
Hàm merge ở đây tương tự như query trong SQL database, DataFrame object tương tự như bảng trong SQL database.
Pandas cung cấp phép toán join đầy đủ các tính năng, hiệu suất cao. Những phương thức này có hiệu suất tốt hơn so với các open source khác (chẳng hạn base::merge.data.frame trong ngôn ngữ R)
pandas.merge(left, right, how=’inner’, on=None, left_on=None, right_on=None, left_index=False, right_index=False, sort=False, suffixes=(‘_x’, ‘_y’), copy=True, indicator=False, validate=None)
Tham số thường dùng:
- left: DataFrame
- right: DataFrame
- how: {‘left’, ‘right’, ‘outer’, ‘inner’}, mặc định ‘inner’
- on: tên các cột hoặc index level để join. (chú ý: phải có ở cả 2 DataFrames)
- left_on: tên các cột hoặc index level của DataFrame bên trái để join
- right_on: tên các cột hoặc index level của DataFrame bên phải để join
- sort: boolean, mặc định là False
- indicator: boolean hoặc string, mặc định là False, nếu để True: sẽ có thêm một cột “_merge”(tên cột sẽ thay đổi theo string nếu được truyền vào) với thông tin source của từng row
- left_only: key chỉ xuất hiện ở DataFrame bên trái
- right_only: key chỉ xuất hiện ở DataFrame bên phải
- both: key xuất hiện ở cả 2 DataFrame
- validate: string, mặc định là None.
- “one_to_one” or “1:1”: kiểm tra liệu key hợp nhất có riêng biệt ở cả 2 DataFrame không
- “one_to_many” or “1:m”: kiểm tra liệu key hợp nhất có riêng biệt ở DataFrame bên trái không
- “many_to_one” or “m:1”: kiểm tra liệu key hợp nhất có riêng biệt ở DataFrame bên phải không
- “many_to_many” or “m:m”: được phép nhưng không đưa ra kết quả
Giá trị tham số “how” và giá trị join SQL tương đương:
| Merge method | SQL Join Name | Description | _merge |
|---|---|---|---|
left | LEFT OUTER JOIN | Chỉ sử dụng keys của frame bên trái | left_only |
right | RIGHT OUTER JOIN | Chỉ sử dụng keys của frame bên phải | right_only |
outer | FULL OUTER JOIN | Sử dụng từng keys của 2 frames | both |
inner | INNER JOIN | Sử dụng keys giao nhau của 2 frames | both |
In [15]: left = pd.DataFrame({'key1': ['K0', 'K0', 'K1', 'K2'],
....: 'key2': ['K0', 'K1', 'K0', 'K1'],
....: 'A': ['A0', 'A1', 'A2', 'A3'],
....: 'B': ['B0', 'B1', 'B2', 'B3']})
....:
In [16]: right = pd.DataFrame({'key1': ['K0', 'K1', 'K1', 'K2'],
....: 'key2': ['K0', 'K0', 'K0', 'K0'],
....: 'C': ['C0', 'C1', 'C2', 'C3'],
....: 'D': ['D0', 'D1', 'D2', 'D3']})
....:
In [17]: pd.merge(left, right, on=['key1', 'key2'])
key1 key2 A B C D
0 K0 K0 A0 B0 C0 D0
1 K1 K0 A2 B2 C1 D1
2 K1 K0 A2 B2 C2 D2
In [18]: pd.merge(left, right, how='left', on=['key1', 'key2'])
key1 key2 A B C D
0 K0 K0 A0 B0 C0 D0
1 K0 K1 A1 B1 NaN NaN
2 K1 K0 A2 B2 C1 D1
3 K1 K0 A2 B2 C2 D2
4 K2 K1 A3 B3 NaN NaN
In [19]: pd.merge(left, right, how='right', on=['key1', 'key2'])
key1 key2 A B C D
0 K0 K0 A0 B0 C0 D0
1 K1 K0 A2 B2 C1 D1
2 K1 K0 A2 B2 C2 D2
3 K2 K0 NaN NaN C3 D3
In [20]: pd.merge(left, right, how='outer', on=['key1', 'key2'])
key1 key2 A B C D
0 K0 K0 A0 B0 C0 D0
1 K0 K1 A1 B1 NaN NaN
2 K1 K0 A2 B2 C1 D1
3 K1 K0 A2 B2 C2 D2
4 K2 K1 A3 B3 NaN NaN
5 K2 K0 NaN NaN C3 D3Tham số “indicator”
In [21]: pd.merge(left, right, on=['key1','key2'], how='outer', indicator=True) key1 key2 A B C D _merge 0 K0 K0 A0 B0 C0 D0 both 1 K0 K1 A1 B1 NaN NaN left_only 2 K1 K0 A2 B2 C1 D1 both 3 K1 K0 A2 B2 C2 D2 both 4 K2 K1 A3 B3 NaN NaN left_only 5 K2 K0 NaN NaN C3 D3 right_only
Tham số “validate”
Pandas cung cấp tham số “validate” để kiểm tra liệu có sự trùng lặp key hợp nhất không. Tính duy nhất của khóa được kiểm tra trước khi merge, do đó sẽ chống việc tràn bộ nhớ, đồng thời đó cũng là một cách tốt để đảm bảo cấu trúc dữ liệu được như mong đợi. Nếu “validate” đúng thì kết quả sẽ được trả về, nếu không sẽ có lỗi được thông báo.
Ví dụ khi thực hiện merge như bên dưới với DataFrame B có giá trị trùng lặp thì sẽ trả ra lỗi.
In [22]: left = pd.DataFrame({'A' : [1,2], 'B' : [1, 2]})
In [23]: right = pd.DataFrame({'A' : [4,5,6], 'B': [2, 2, 2]})
In [24]: left
A B
0 1 1
1 2 2
In [25]: right
A B
0 4 2
1 5 2
2 6 2
In [26]: result = pd.merge(left, right, on='B', how='outer', validate="one_to_one")
...
MergeError: Merge keys are not unique in right dataset; not a one-to-one merge
Tài liệu tham khảo:
- “Mastering pandas” – Femi Anthony
- http://pandas.pydata.org/pandas-docs/version/0.23.4/
Python 101 – The great but nearly forgotten Decorators

Pandas trong Python (Bài 1): Giới thiệu chung
