Bài toán tối ưu performance và memory cùng với Akka (Phần II)
Trong phần 1 đã đề cập đến Akka Actor và cách sử dụng chúng trong bài toán cụ thể. Cũng như nhắc đến những ưu điểm và nhược điểm trong việc xử lý concurrency và parallelism.
Đến với phần 2 chúng ta sẽ giải quyết bài toán “tắc nghẽn cổ chai” gặp phải khi sử dụng Akka Actor trong bài toán Batch processing
Problem
Nhắc lại một chút từ phần 1, chúng ta có
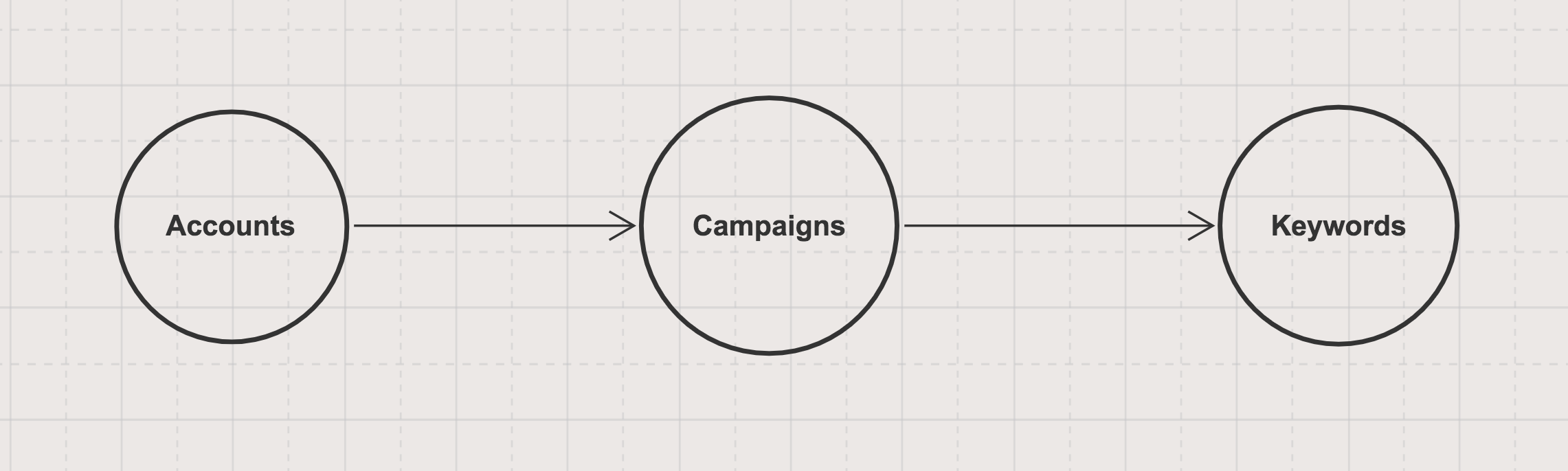
Khi sử dụng Akka Actor chúng ta gặp phải vấn đề “tắc nghẽn cổ chai”
Solution
Cốt lõi để xử lý hiện tượng “tắc nghẽn cổ chai” là
Producer đẩy số lượng công việc lớn hơn số công việc consumer có thể xử lý

Ở siêu thị nếu mỗi nhân viên bán hàng chỉ xử lý được 10 khách/phút thì việc 20 khách vào 1 hàng không những không làm tăng tốc độ được thanh toán mà còn gây “rảnh rỗi” không cần thiết ở những hàng chờ khác.
Lý do là khách hàng(Producer) không biết tốc độ bán hàng của nhân viên(consumer) là bao nhiêu? Vậy nếu như ở mỗi line bán hàng, thông báo :
- Come In: nếu số lượng khách hàng (rate of producer) < tốc độ xử lý của nhân viên bán hàng(rate of consumer)
- Full: nếu số lượng khách hàng (rate of producer) >tốc độ xử lý của nhân viên bán hàng(rate of consumer)
Và đây chính là nguyên tắc xử lý của “Work pulling pattern”
Tuy nhiên từ vấn đề này khiến mình nhìn ra nhiều vấn đề khi sử dụng Akka Actor trong bài toán Batch processing:
- Actors do not compose well: Việc gửi message từ Actor A đến Actor B sẽ được hard-code trong Actor A, điều này làm giảm tính linh hoạt khi thiết kế hệ thống và sử dụng lại Actor
- Actors thường không minh bạch: ngay trong bài toán của mình, khi 1 người mới nhìn vào 1 đống những Actors, họ sẽ không thể hiểu/tưởng tượng ra một cách tổng quát những Actors nào đang giao tiếp với Actors nào. Chỉ có cách đọc từng actor một, việc này gây lãnh phí thời gian 1 cách không cần thiết.
- Actors cần tối ưu hóa rất nhiều: how to tối ưu hóa ?
Akka Streams — Reactive Streams way
Back-Pressure — Heart of Reactive Streams
Cốt lõi của Back-pressure chính là xử lý problem của chúng ta bên trên
Producer đẩy số lượng công việc lớn hơn số công việc consumer có thể xử lý
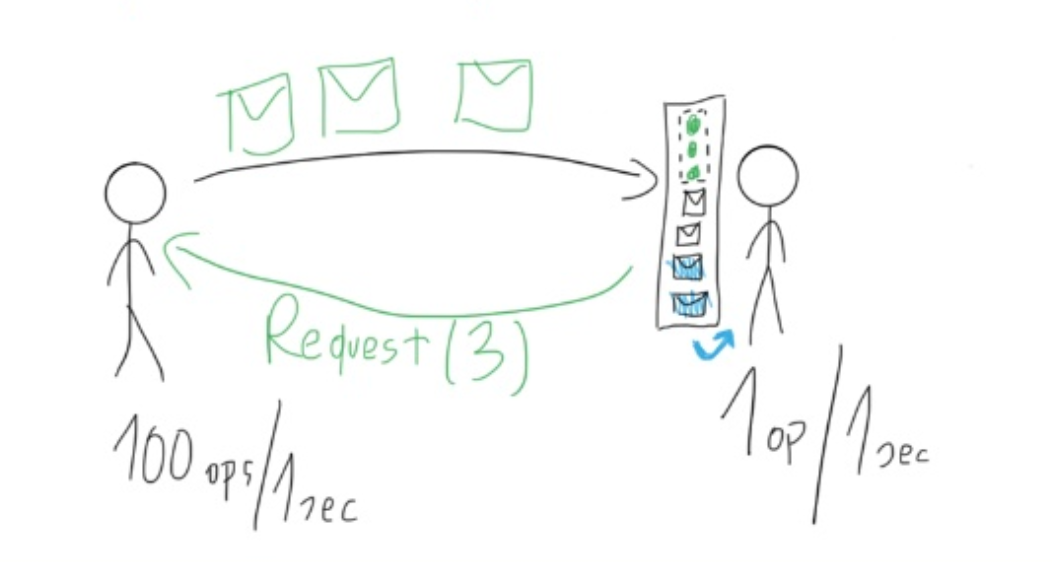
Consumer sẽ yêu cầu số lượng mình mong muốn cho Producer, và producer sẽ đáp ứng con số đấy. Con số này sẽ phụ thuộc hoàn toàn vào consumer ở những thời điểm khác nhau.
Điều ngày ngược hoẳn hoàn toàn với cách với Actor ở phần I
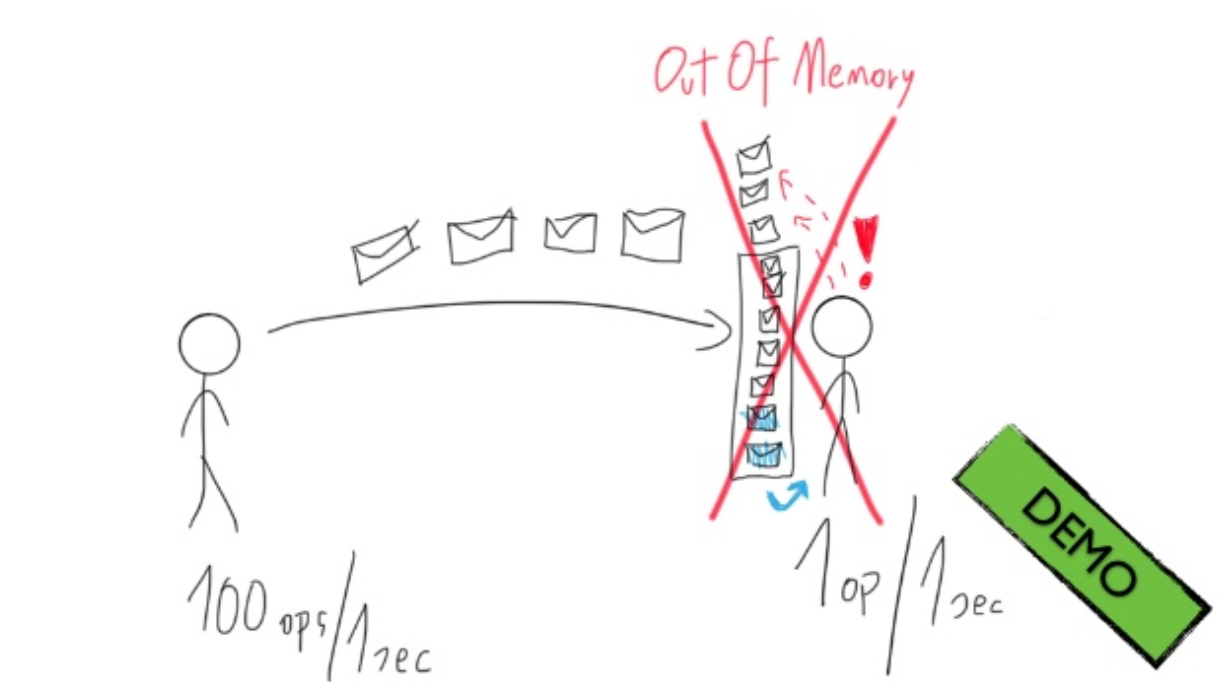
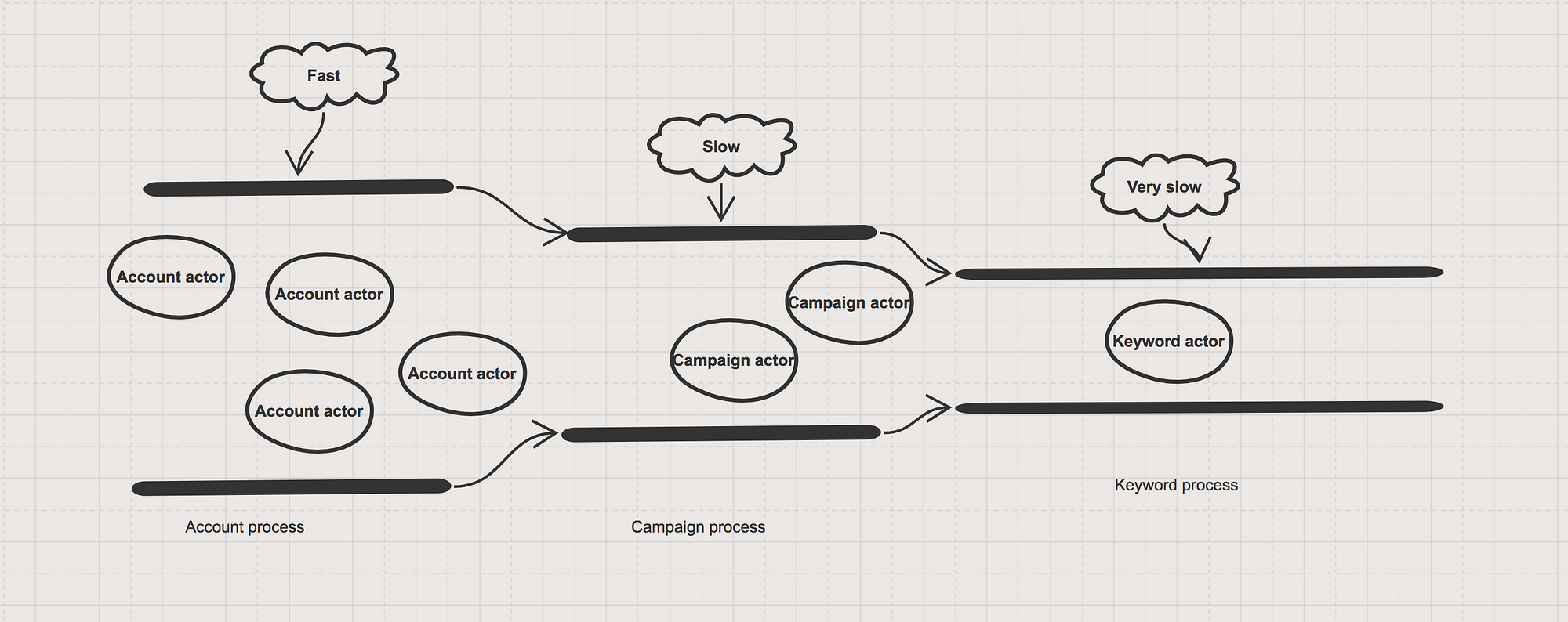
Account process xử lý rất nhanh, nó đổ messages liên tục vào Mailbox của Campaign Actor, tượng tự với Campaign actor đổ messages vào mailbox của Keyword actor. Mà không cần quan tâm process sau mình đang xử lý ở tốc độ nào. Với việc Mailbox tăng nhanh, mà actor ở process đấy có hạn(đang busy xử lý) => memory dùng cho Mailboxs tăng cao một cách không cần thiết.
Let The Code Speak For Itself
case class Account(id: Int, name: String)
case class Campaign(id: Int, accountId: Int, name: String)
case class Keyword(id: Int, campaignId: Int, name: String)
val accounts: List[Account] = List(
Account(1, "Maria"),
Account(2, "Jon"),
Account(3, "Snow")
)
val campaigns: List[Campaign] = List(
Campaign(1, 1, "Maria-campaign-1"),
Campaign(2, 1, "Maria-campaign-2"),
Campaign(3, 2, "Jon-campaign-1"),
Campaign(4, 3, "Snow-campaign-1"),
)
val keywords: List[Keyword] = List(
Keyword(1, 1, "A"),
Keyword(2, 1, "B"),
Keyword(3, 1, "C"),
Keyword(4, 1, "D"),
Keyword(5, 2, "E"),
Keyword(6, 2, "F"),
Keyword(7, 3, "G"),
Keyword(8, 3, "H"),
Keyword(9, 4, "I"),
)
implicit val system: ActorSystem = ActorSystem("AkkaStream")
implicit val materializer = ActorMaterializer(ActorMaterializerSettings(system))
// Source is where everything start
// It has a output
val source: Source[Account, NotUsed] = Source(accounts)
// Flow is where data transformation
// It has a input and a output
val accountFlow: Flow[Account, List[Campaign], NotUsed] = Flow[Account].map(account => {
println(s"Insert account ${account.name}")
val campaignIn = for (campaign <- campaigns; if campaign.accountId == account.id) yield campaign
campaignIn
})
// Flow[A,B,C] : A is input's type, B is output's type, C is materialized value
val campaignFlow: Flow[Campaign, List[Keyword], NotUsed] = Flow[Campaign].map(campaign => {
println(s"Insert campaign ${campaign.name}")
val keywordsIn = for (keyword <- keywords; if keyword.campaignId == campaign.id) yield keyword
keywordsIn
})
val keywordFlow: Flow[Keyword, Unit, NotUsed] = Flow[Keyword].map(keyword => {
println(s"Insert keyword ${keyword.name}")
})
// This is where you connect all the pieces you have wrote
// via means make ...~>...
source via accountFlow mapConcat identity via campaignFlow mapConcat identity via keywordFlow runWith Sink.ignore onComplete {
case Success(_) =>
println("Stream completed successfully")
system.terminate()
case Failure(error) =>
println(s"Stream failed with error ${error.getMessage}")
system.terminate()
}Let the picture make you understand easier
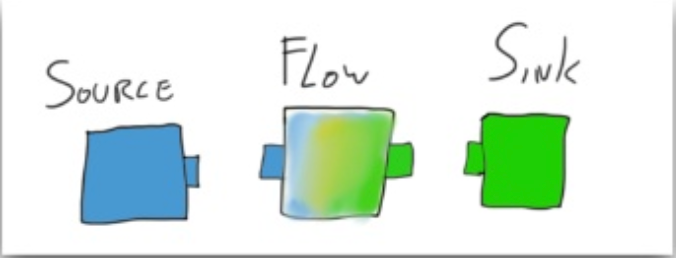
Công việc của bạn là xây dựng các Source, Flow, Sink sau đó sắp xếp chúng với nhau như ghép lego vậy!
In-depth
Đây là kết quả khi chạy đoạn code trên
Start AkkaStream-akka.actor.default-dispatcher-3 Insert account Maria AkkaStream-akka.actor.default-dispatcher-3 Insert campaign Maria-campaign-1 AkkaStream-akka.actor.default-dispatcher-3 Insert keyword A AkkaStream-akka.actor.default-dispatcher-3 Insert keyword B AkkaStream-akka.actor.default-dispatcher-3 Insert keyword C AkkaStream-akka.actor.default-dispatcher-3 Insert keyword D AkkaStream-akka.actor.default-dispatcher-3 Insert campaign Maria-campaign-2 AkkaStream-akka.actor.default-dispatcher-3 Insert keyword E AkkaStream-akka.actor.default-dispatcher-3 Insert keyword F AkkaStream-akka.actor.default-dispatcher-3 Insert account Jon AkkaStream-akka.actor.default-dispatcher-3 Insert campaign Jon-campaign-1 AkkaStream-akka.actor.default-dispatcher-3 Insert keyword G AkkaStream-akka.actor.default-dispatcher-3 Insert keyword H AkkaStream-akka.actor.default-dispatcher-3 Insert account Snow AkkaStream-akka.actor.default-dispatcher-3 Insert campaign Snow-campaign-1 AkkaStream-akka.actor.default-dispatcher-3 Insert keyword I Stream completed successfully
Cùng dispatcher-2 => không parallelism?
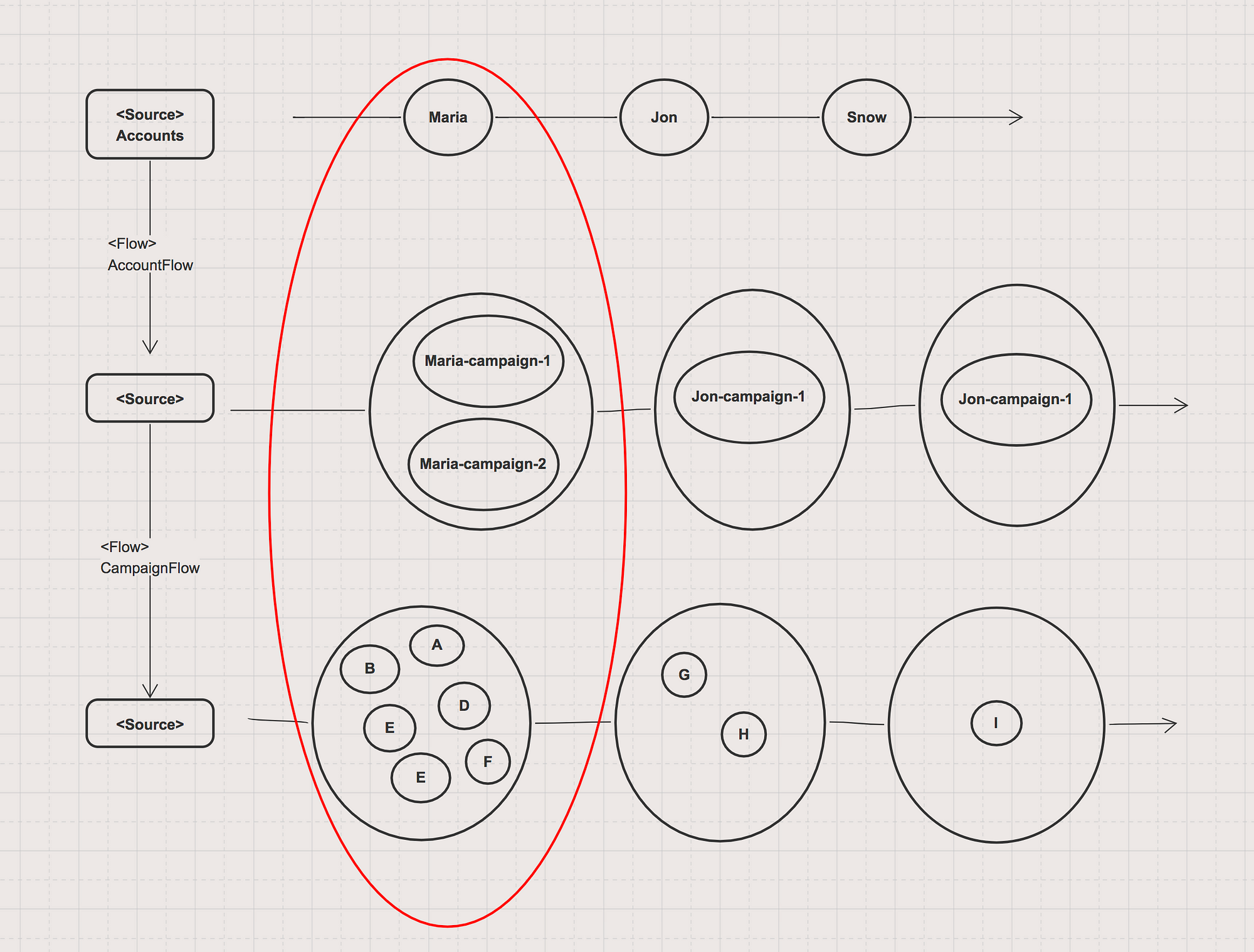
Bạn để ý data sẽ được print theo chiều dọc, theo chiều của vòng tròn màu đỏ, sau đó chuyển sang hàng dọc tiếp theo => Synchronous?
Vậy có vẻ như đoạn code trên với Akka Streams chúng ta không đạt được điều ta mong muốn như khi dùng với Akka Actors.
Điều chúng ta thiếu ở đây là làm cho Flow asynchronous, và akka streams có cung cấp cho chúng ta:
/** * Put an asynchronous boundary around this `Flow`. * * If this is a `SubFlow` (created e.g. by `groupBy`), this creates an * asynchronous boundary around each materialized sub-flow, not the * super-flow. That way, the super-flow will communicate with sub-flows * asynchronously. */ def async: Repr[Out]
Và đây là kết quả sao đó
Start AkkaStream-akka.actor.default-dispatcher-2 Insert account Maria AkkaStream-akka.actor.default-dispatcher-2 Insert account Jon AkkaStream-akka.actor.default-dispatcher-2 Insert account Snow AkkaStream-akka.actor.default-dispatcher-7 Insert campaign Maria-campaign-1 AkkaStream-akka.actor.default-dispatcher-7 Insert campaign Maria-campaign-2 AkkaStream-akka.actor.default-dispatcher-7 Insert campaign Jon-campaign-1 AkkaStream-akka.actor.default-dispatcher-3 Insert keyword A AkkaStream-akka.actor.default-dispatcher-7 Insert campaign Snow-campaign-1 AkkaStream-akka.actor.default-dispatcher-3 Insert keyword B AkkaStream-akka.actor.default-dispatcher-3 Insert keyword C AkkaStream-akka.actor.default-dispatcher-3 Insert keyword D AkkaStream-akka.actor.default-dispatcher-3 Insert keyword E AkkaStream-akka.actor.default-dispatcher-3 Insert keyword F AkkaStream-akka.actor.default-dispatcher-3 Insert keyword G AkkaStream-akka.actor.default-dispatcher-3 Insert keyword H AkkaStream-akka.actor.default-dispatcher-3 Insert keyword I Stream completed successfully
Data đã được print một cách asynchronous theo hàng ngang như ở hình trên.
Và mỗi Flow cũng được dispatcher đặt ở các thread khác nhau!
What next?
Xét cho cùng Akka Streams chỉ là một tool/framework để xử lý các trường hợp phù hợp
Giữa Akka Actor — Akka Streams đều có những điểm mạnh/điểm yếu phù hợp với từng trường hợp:
- Akka Actor: mang lại cho chúng ta distribution và location transparency
- Akka Streams: mang lại cho chúng ta Back-Pressure và rất nhiều blueprint
Phía trên mới chỉ là cách sử dụng Akka streams một cách cơ bản, trong phần tiếp theo, mình sẽ trình bày thêm về cách sử dụng, Akka Streams Graph, cách limit rate, cách parallelism trong 1 Flow
Tham khảo
Understanding Akka Streams, Back Pressure, and Asynchronous Architectures
Functional Programming’s Toolkit: Fold

Có gì hot trong phiên bản JDK21 vừa được ra lò
