View source at here
Kết quả:

Vấn đề 2: Lấy tất cả các url của bài viết.
* Lấy các url tại 1 page
...
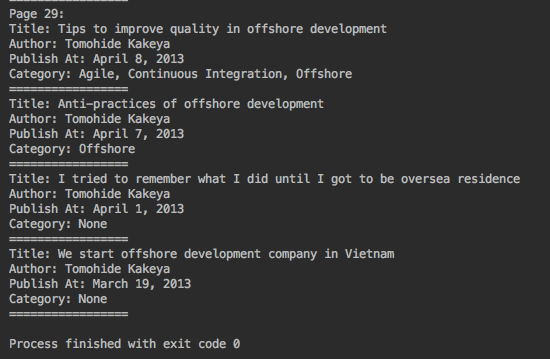
- Số lượng pages
29
Kết quả:
Xin chào, mình là Thắng
Hôm nay mình sẽ hướng dẫn các bạn dùng scala để crawler dữ liệu từ website, mà cụ thể ở đây, mình sẽ crawler dữ liệu của https://labs.flinters.vn/ 😀
Trước khi crawler, bạn hãy tham quan qua blog của SepTech nhé.
Ở blog này, mình sử dụng thư viện Jsoup
libraryDependencies += "org.jsoup" % "jsoup" % "1.10.3"Bây giờ muốn crawler toàn bộ các blog, chúng ta cần phải giải quyết được 2 vấn đề sau:
1. Lấy được nội dung của một bài viết
2. Lấy được tất cả các url của các bài viết (lấy tất cả các trang + lấy tất cả link bài viết trong 1 trang)
Vấn đề 1: Chúng ta sẽ truy cập vào bài viết cụ thể, ở đây mình vào bài viết mới nhất luôn
Bạn có thể quan sát bài viết, và sẽ lấy những thông tin cần thiết, như tiêu đề, tác giả, nội dung, category, ngày public,…
Tiếp theo, ta sẽ xác định vị trí của các thông tin ở trên. Có thể ấn chuột phải, rồi view-source, hoặc inspect. Ở đây mình chọn inspect vì nó khá là tiện lợi.
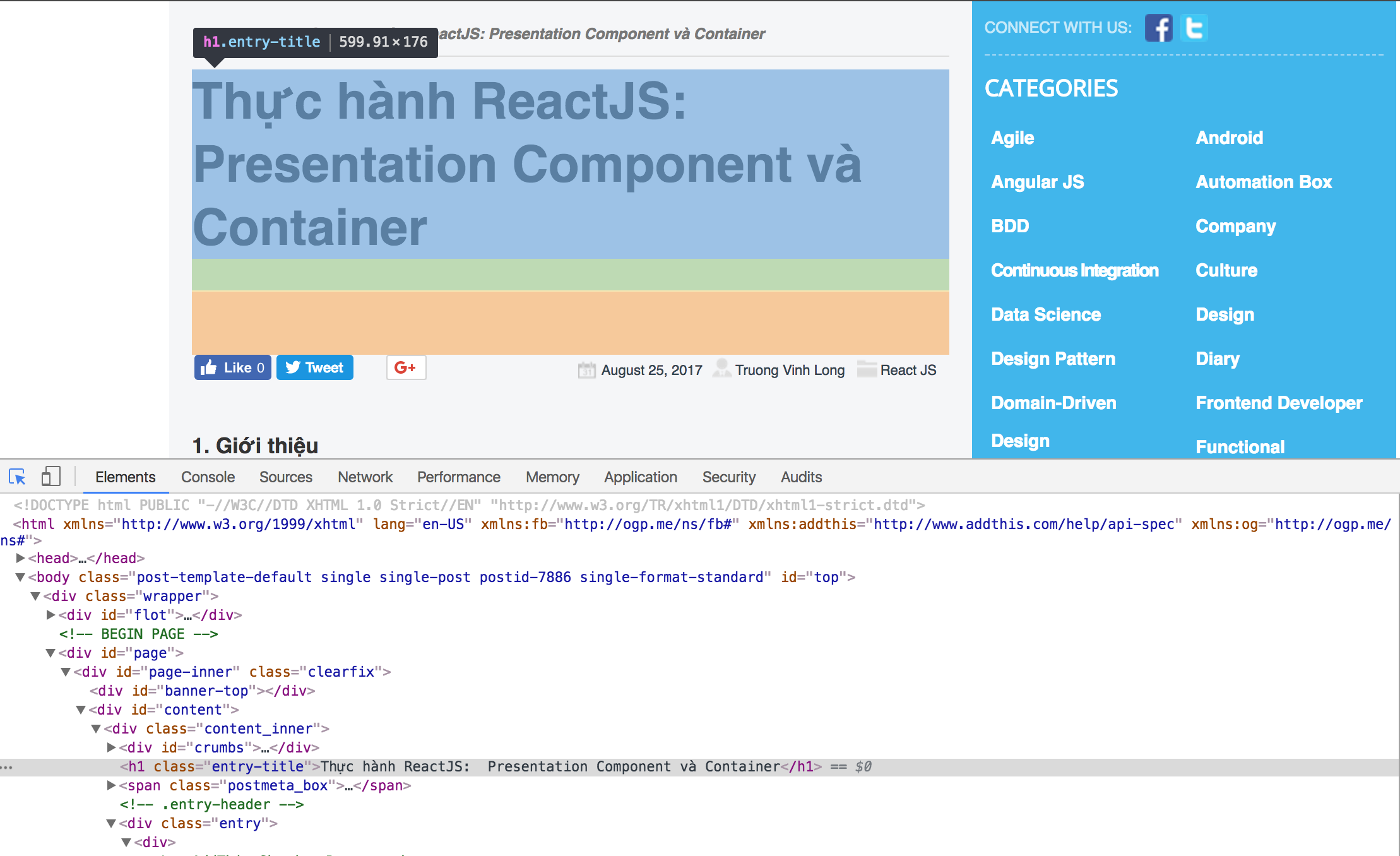
Sau một hồi thì ta có các thông tin sau
Tiêu đề
Category
Nội dung
View source at here
Kết quả:

Vấn đề 2: Lấy tất cả các url của bài viết.
* Lấy các url tại 1 page
...
- Số lượng pages
29
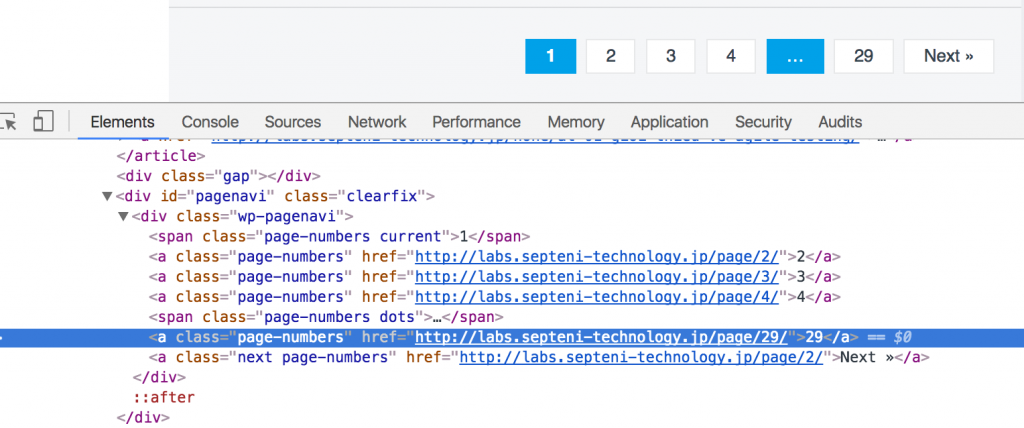

Kết quả:

Các hàm functional programming trong Scala : filter và partition

Remote profiling/monitoring with VisualVM on vagrant + play framework application.


7 phút để hiểu rõ Dependency Injection và ứng dụng nó trong Scala với Macwire
About The Author


Đỗ Xuân Thắng