[ML – 12] Machine Learning Diagnostic P2
Tiếp nối nội dung của bài 11, trong bài này ta sẽ tìm hiểu cách lựa chọn λ cho Regularization, đồng thời quan sát một chút quá trình learning của mô hình.
5. Regularization & bias/variance:
Tình trạng bias và variance sẽ thay đổi như thế nào khi ta tác động vào phần Regularization? Tiếp tục trở lại với ví dụ trong bài trước, trong mô hình Linear Regression với số lượng feature x = 1, bậc mô hình d = 4:
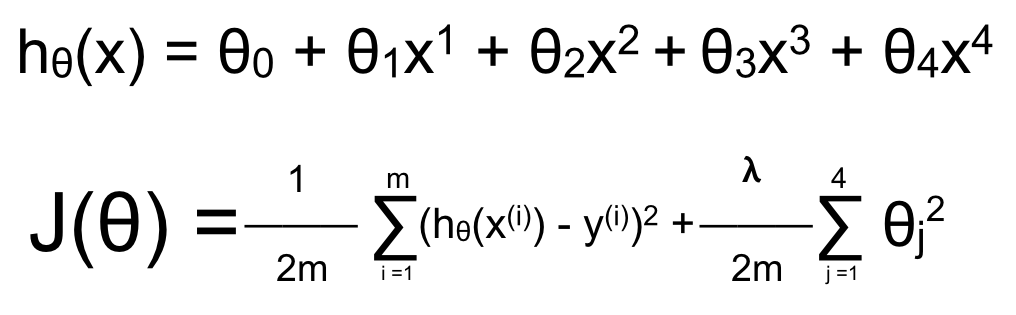
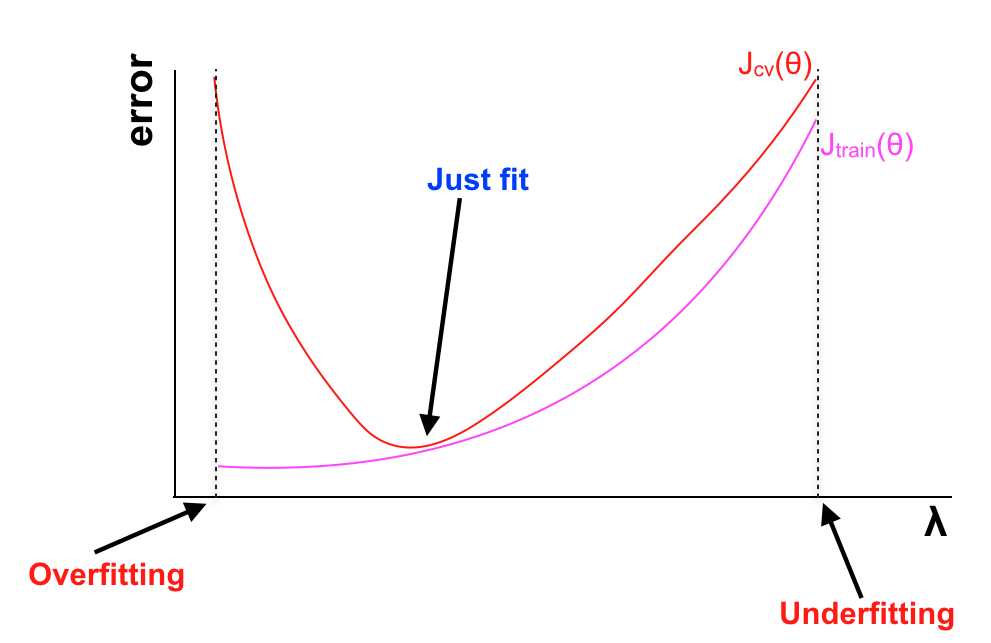
– Nếu λ quá lớn: giá trị của tất cả θ ngoại trừ θ0 đều giảm mạnh, xấp xỉ về 0. Khi đó giá trị của hàm hypothesis chỉ còn phụ thuộc vào θ0 -> Hight bias -> Underfitting ngay trong tập training.
Chẳng hạn λ = 100000, θ1 ≈ 0, θ2 ≈ 0… hθ(x) ≈ θ0
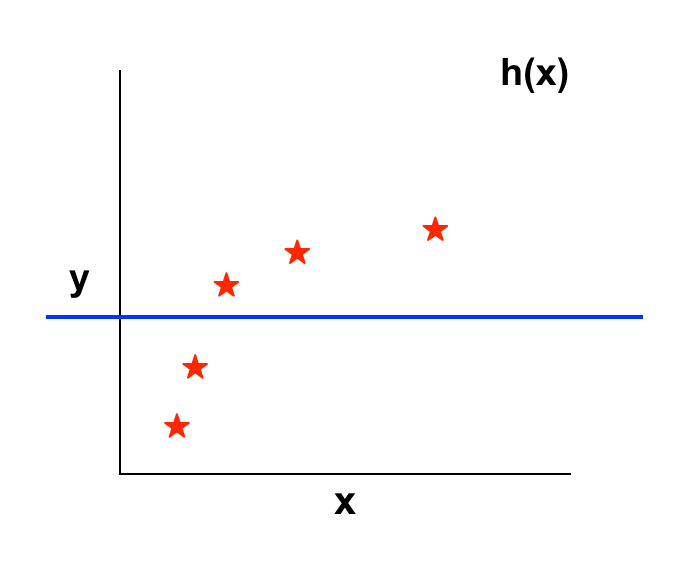
– Nếu λ phù hợp: Đây là giá trị λ ta mong muốn tìm kiếm.
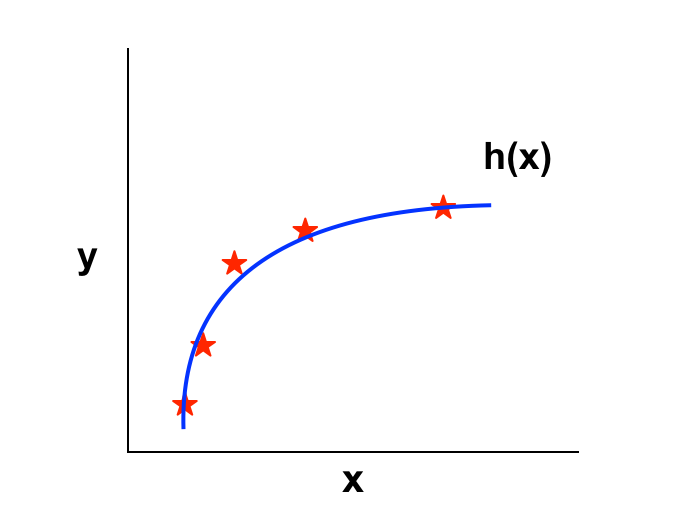
– Nếu λ nhỏ: xấp xỉ bằng 0, khiến cho phần Regularization nhỏ, gần với 0 hay nói cách khác là bỏ qua Regularization, khi bậc đẩy lên cao mô hình sẽ vướng vào High variance -> Overfitting
Vấn đề bây giờ là giá trị λ như thế nào thì được gọi là phù hợp, bản thân λ là số thực > 0 nên nó có thể là bất cứ giá trị dương nào, dù ta có một khoảng giới hạn nhất định (chẳng hạn 10 < λ < 100) ta cũng không thể xác định được giá trị chính xác của λ. Chính vì vậy ta chỉ có thể xác định λ thông qua việc lựa chọn những giá trị rời rạc, nhưng số lượng giá trị này sẽ khá lớn nên ta sẽ tìm cách để thực hiện việc này một cách tự động.
Chẳng hạn:
Ta xác định được λ nằm trong khoảng [0 ; 10] (Ở λ = 0, mô hình bị Overfitting còn ở λ = 10, mô hình bị Underfitting – cách kiểm tra Overfitting và Underfitting chúng ta đã đề cập đến trong các bài trước). Ta xác định model trên những giá trị của λ như sau:
– model(1): λ = 0
– model(2): λ = 0.1
– model(3): λ = 0.2
– model(4): λ = 0.4
– model(5): λ = 0.8
– …
– model(k): λ = 10
Model(k) sẽ có λk = 2λk-1 của model(k-1). Vì 0 * 2 = 0 nên ta tăng λ của model(2) lên 0.1
Lần lượt cho máy học với λ tương ứng, ta thu được k bộ tham số θ tương ứng với k model. Sau đó ta tính sai số trên tập CV của mỗi model và lựa chọn model có sai số thấp nhất, chẳng hạn λp. Cuối cùng là test trên tập test để đảm bảo kết quả mang tính tổng quát. Nếu bạn muốn tìm kiếm λ chính xác hơn, hãy tiếp tục chia nhỏ khoảng giá trị [λp-1 ; λp+1] và làm tương tự như trên. Chỉ với chút ít lập trình ta sẽ biến công việc trên thành tự động, tuy nhiên nếu cố tìm λ quá chính xác có thể sẽ khiến bạn đổ nhiều thời gian cho việc chờ đợi quá trình học của máy.
Bên cạnh đó ta cũng có thể đưa λ và sai số trên tập training, tập CV để có cái nhìn trực quan:
6. Learning curves:
Giờ chúng ta sẽ đi quan sát Learning curves để thấy được số lượng dữ liệu training ảnh hướng tới kết quả học của máy như thế nào ?
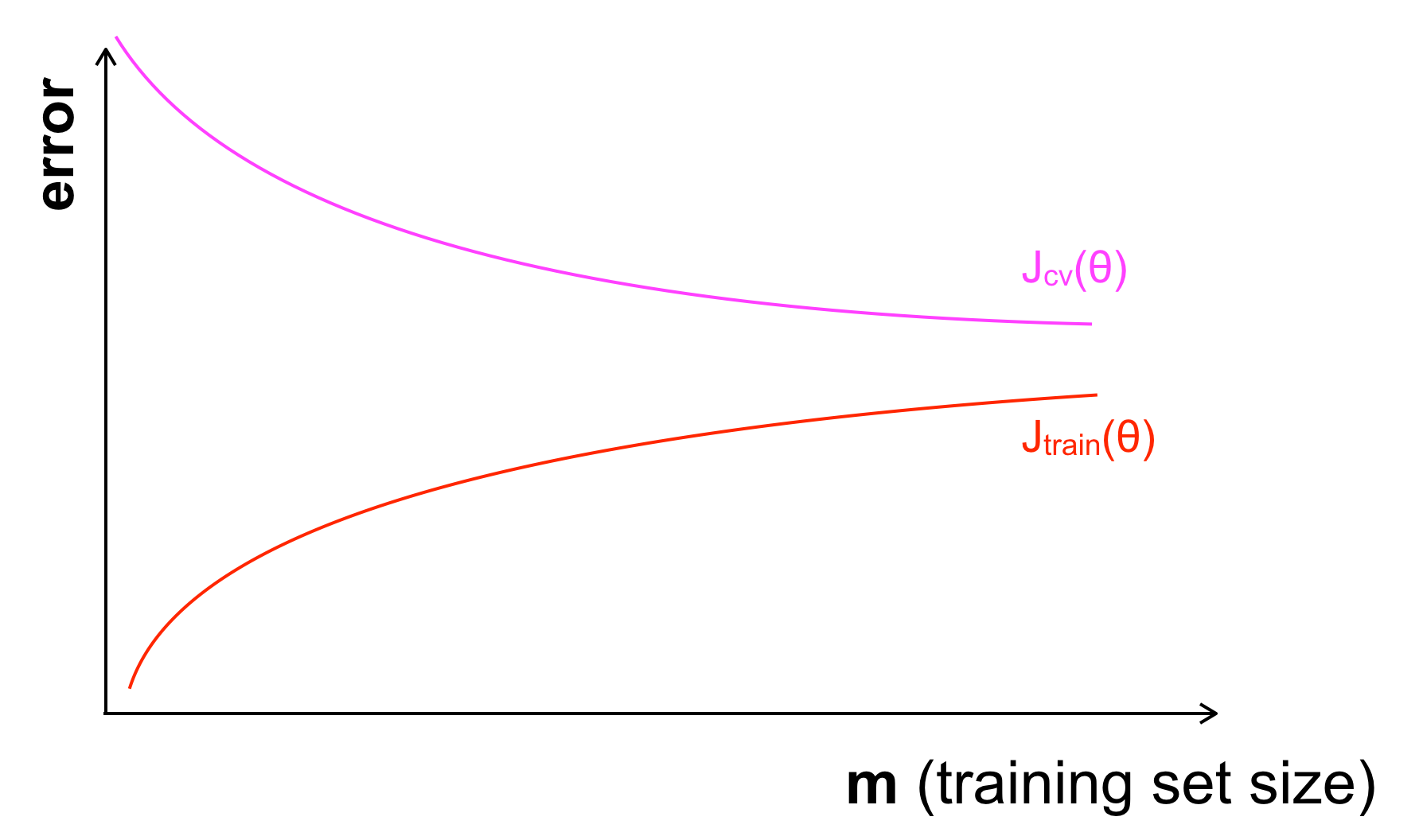
Ta đưa giá trị của Jtrain, Jcv và số lượng bộ dữ liệu training m vào đồ thị để quan sát xem m ảnh hưởng tới cost function J trên các tập dữ liệu ra sao:
Để ý một chút rằng:
– Với tập training, Jtrain sẽ nhỏ khi số lượng dữ liệu nhỏ (Với càng ít dữ liệu, mô hình của ta càng dễ dự đoán đúng nhiều trên tập training) và khi m Jtrain cũng tăng theo.
– Với tập CV, Jcv sẽ lớn khi số lượng dữ liệu training nhỏ (Với ít dữ liệu, mô hình của ta sẽ khó tổng quát hoá được để dự đoán xu hướng của dữ liệu nên khi test trên tập CV, sai số sẽ lớn) và ngược lại khi m tăng, Jcv sẽ giảm.
Hai điều trên có nghĩa sai số trên tập training và CV sẽ càng ngày càng tiến gần tới nhau. Giá trị của 2 giá trị này càng gần nhau, nghĩa là mô hình đang học một cách phù hợp.
Ngược lại khi gặp vấn đề Underfitting hay High Bias thì đồ thị sẽ trông giống như sau:
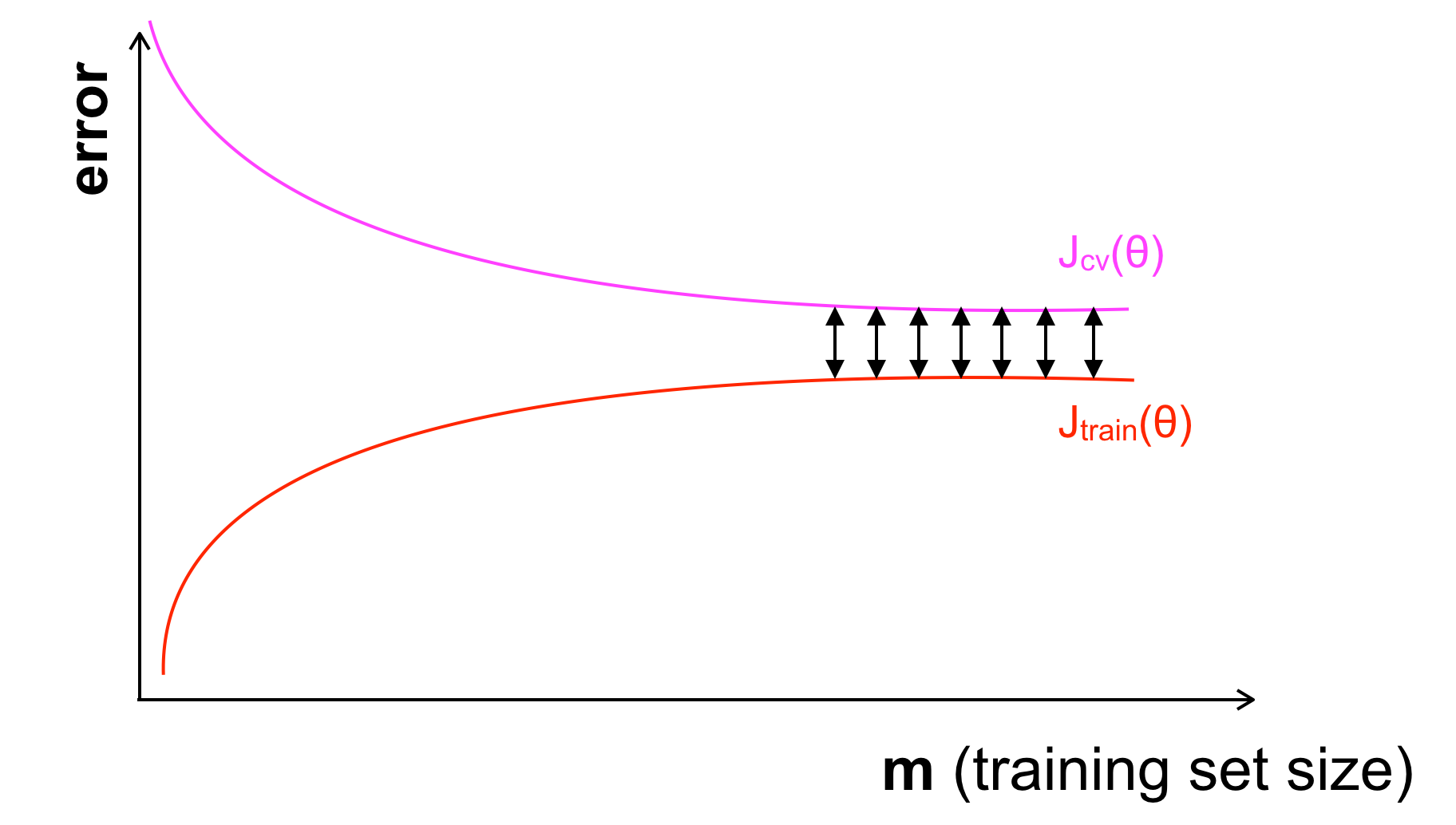
Khi vướng vào Underfitting (High Bias): Jtrain, Jcv đều lớn, mà Underfitting là khi mô hình của ta quá đơn giản hoặc không phù hợp nên khi lượng dữ liệu có tăng lên, sai số trên cả 2 tập cũng không thể giảm. Như trên đồ thị ta thấy, Jtrain và Jcv đạt ngưỡng và không tiến lại gần nhau nữa.
Khi gặp vấn đề Overfitting hay High Variance thì đồ thị lại khác:
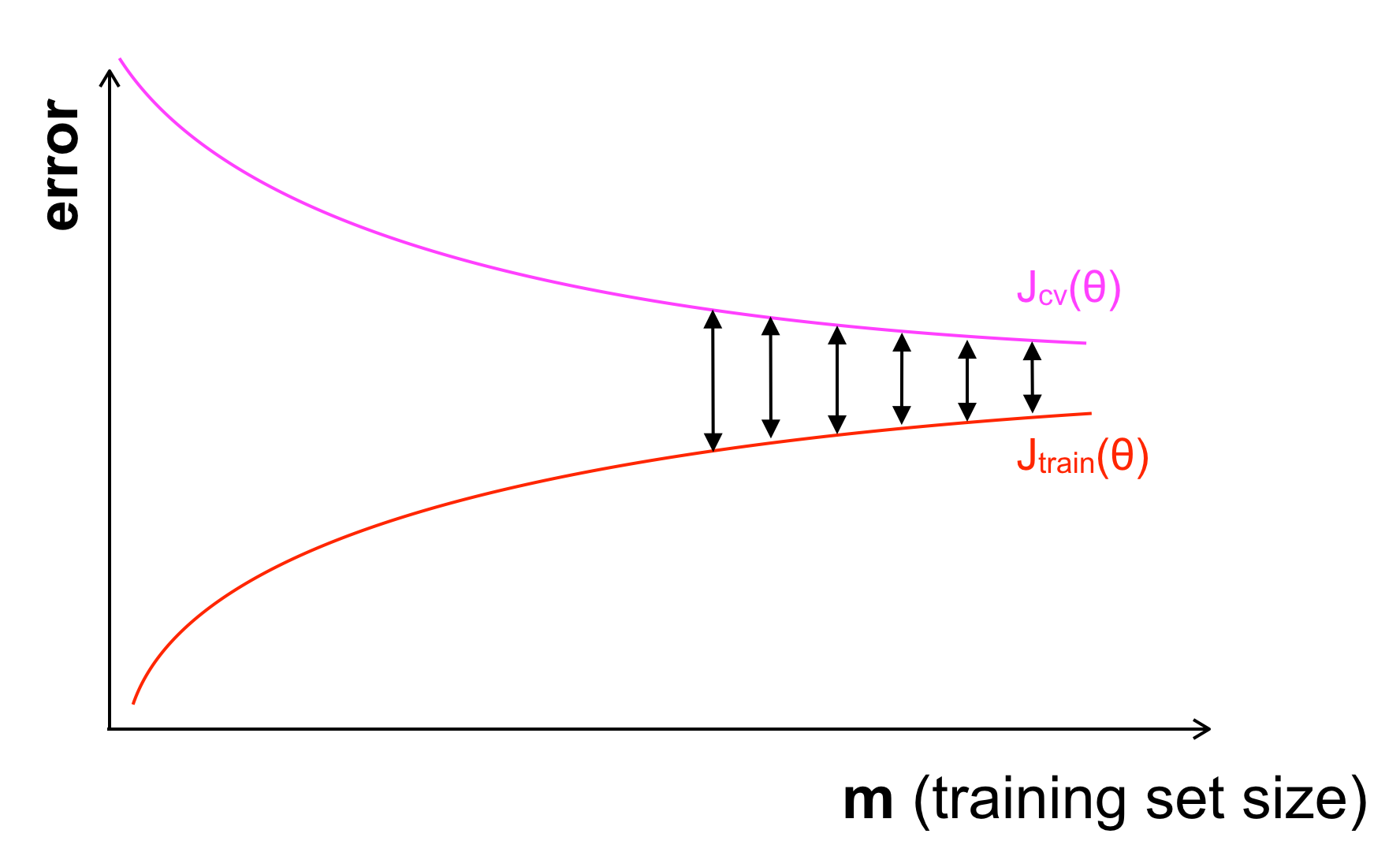
Khi gặp phải Overfitting (High Variance): Jtrain nhỏ nhưng Jcv lại lớn. Ở thời điểm hiện tại, mô hình của ta học tốt trên tập training, có thể dự đoán tốt trên tập training nhưng trên tập CV vẫn còn chưa tốt, tuy nhiên Jtrain và Jcv vẫn đang có xu hướng tiến lại gần nhau khi m tăng. Nghĩa là trong trường hợp này, khi tăng số lượng dữ liệu có lẽ sẽ giải quyết đc vấn đề. (Khi m đủ lớn, sai số trên 2 tập sẽ gần như bằng nhau). Tuy nhiên, khi tăng số lượng dữ liệu chỉ có thể có tác dụng chứ không chắc chắn vì ngoài ra ta còn gặp các vấn đề khác như Regularization quá nhỏ, bậc mô hình quá cao…
7. Recap:
Ta sẽ cùng tổng kết một số phương pháp và tác dụng của nó đối với High Bias & High Variance:
– Tăng số lượng dữ liệu: có thể giúp fix High Variance, nhưng không có ý nghĩa gì với High Bias
– Giảm số lượng feature: fix High Variance (như trong bài về Regularization ta đã đề cập)
– Tăng số lượng feature: fix High Bias (tăng số lượng feature giúp mô hình phức tạp hơn)
– Thêm thành phần đa thức: fix High Bias (thực tế là một hình thức tăng số lượng feature, và tăng độ phức tạp của mô hình)
– Giảm λ: fix High Bias (tránh việc Regularization triệt tiêu toàn bộ các feature)
– Tăng λ: fix Hight Variance (tránh việc bỏ qua Regularization)
Đối với ANN:
– Sử dụng NN nhỏ, ít layer, ít neurons – chi phí tính toán rẻ, dễ vướng vào Underfitting do sự đơn giản
– Sử dụng NN lớn, nhiều layer, nhiều neurons – dễ vướng vào Overfitting tuy nhiên có thể giải quyết bằng Regularization, chi phí tính toán lớn
Với những quan sát trên, chúng ta đã phần nào tự tin hơn vào khả năng “chẩn bệnh” cho mô hình của mình. Cảm ơn các bạn đã quan tâm theo dõi và hẹn gặp lại các bạn trong bài viết sau.
[ML – 14] Machine Learning long term and a Learning path