Tools For Querying Semi-Structured Data
Context
Làm việc với các dữ liệu semi-structured data phổ biến như json và csv đôi khi chúng ta gặp phải vấn đề như: đếm số dòng đối với csv, đếm số bản ghi của json array hoặc kiểm tra xem field, cột này có rỗng, xuất hiện hay không hay thậm chí là tính tổng, đếm theo 1 key nhất định. Thông thường thì sẽ có cách làm như sau:
1. Sử dụng text editor để search, filter nhưng cách này chỉ thực hiện được với 1 vài files có dung lượng nhỏ và tốn công sức.
2. Viết 1 vài dòng code nhưng cũng khá khó khăn để đáp ứng tốc độ khi lượng files nhiều.
3. Import vào database và query. CSV khá nhiều loại database hỗ trợ, còn json thường chỉ có document datasbase hỗ trợ.
4. Dùng Athena, BigQuery. Thông thường sẽ phải tạo schema cho data trước và tốn chi phí, thích hợp cho lượng dữ liệu lớn.
5. Dùng các tools như spark, presto. Đáp ứng được với lượng dữ liệu vừa phải dùng trên máy cá nhân.
Example
Giả sử có 112 files được lấy từ API https://ads-developers.yahoo.co.jp/reference/ads-display-api/v8/AdGroupTargetService/get/en/
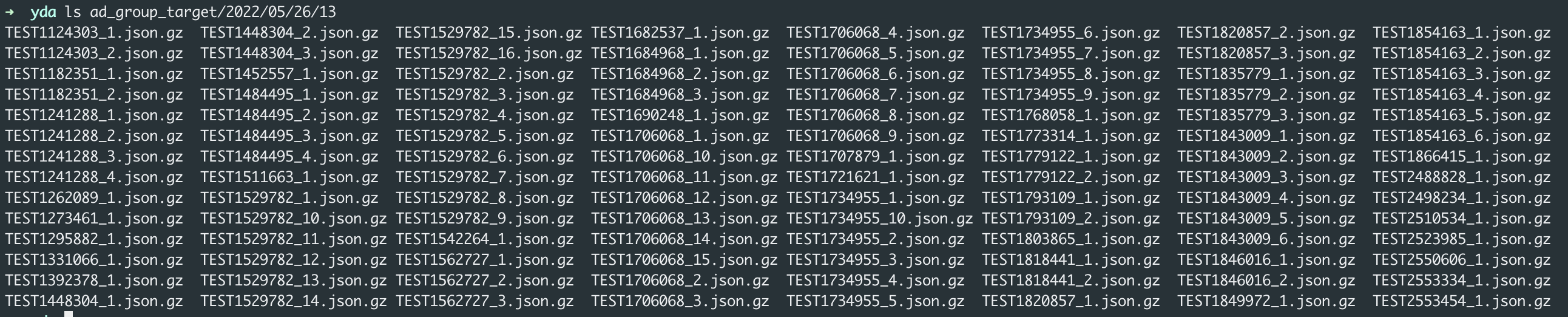
Cần đếm các số bản ghi theo rval.values[*].adGroupTargetList.target.targetType trên toàn bộ các file.
Đối với yêu cầu này dùng phương án 3 và 5 sẽ hiệu quả hơn vì chúng ta không query thường xuyên và lượng file không nhiều.
Dùng spark-sql hoặc dùng spark-shell với scala
- Tạo view cho toàn bộ data.
CREATE TEMPORARY VIEW ad_group_target
USING org.apache.spark.sql.json
OPTIONS(
path "/Users/huy_nq/yda/ad_group_target/2022/05/26/13"
);
DESCRIBE ad_group_target;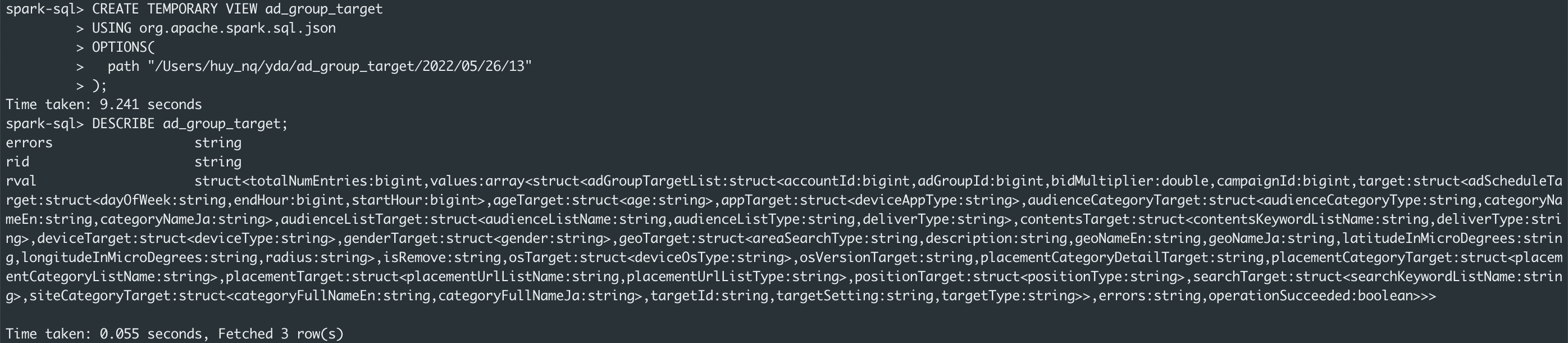
- Dùng hàm explode để đưa array
rval.valuesthành từng row
CREATE TEMPORARY VIEW ad_group_target_values
AS SELECT explode(rval.values) value FROM ad_group_target;- Đếm các số bản ghi theo
value.adGroupTargetList.target.targetType
SELECT value.adGroupTargetList.target.targetType targetType, COUNT(*) total
FROM ad_group_target_values
GROUP BY value.adGroupTargetList.target.targetType;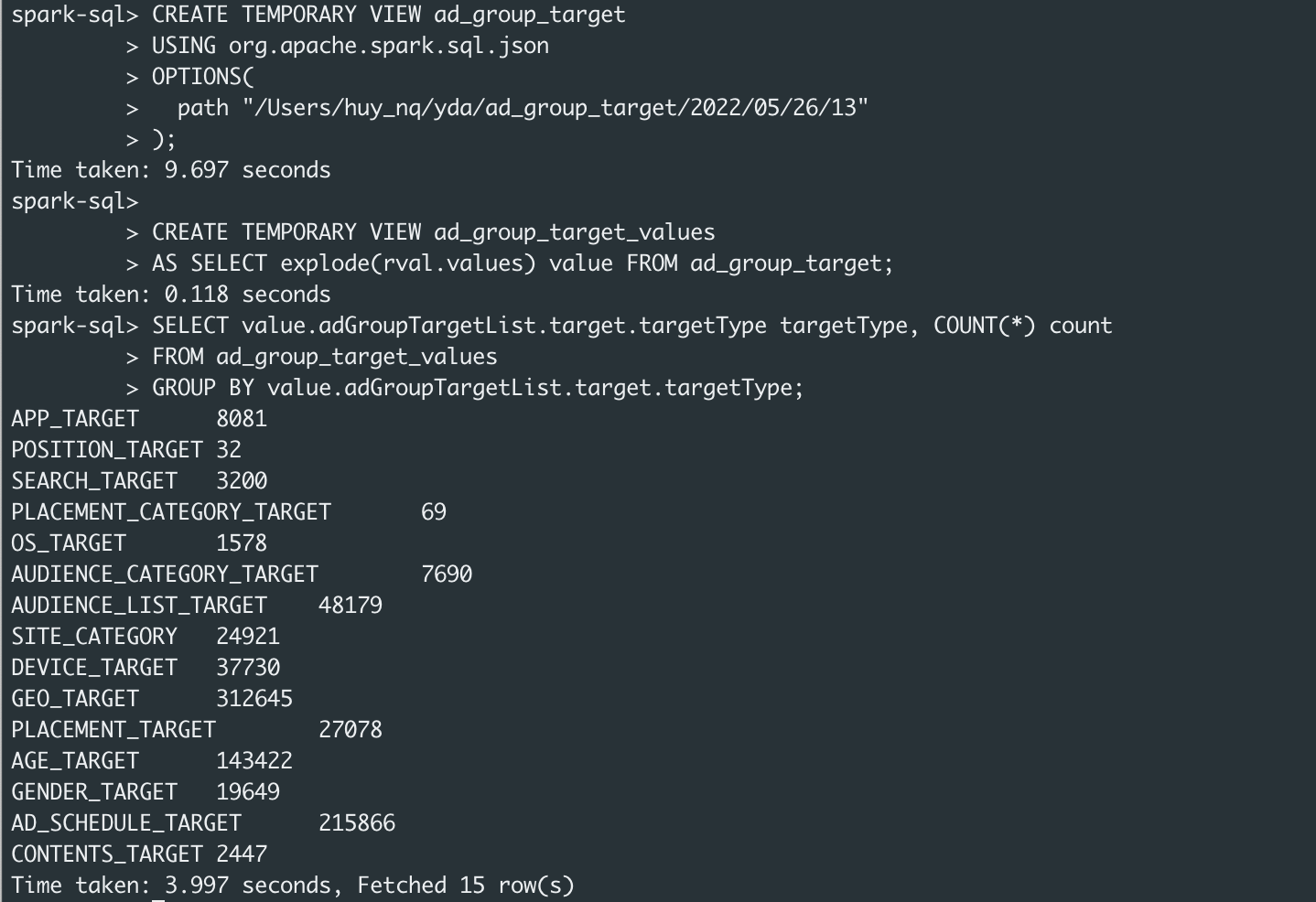
Ưu điểm
- SQL thân thiện với người dùng
- Đáp ứng được nhiều loại semi-structured data
- Tự động infer schema
Nhược điểm
- Giao diện cli. Có thể dùng kết hợp với jupyter notebook hoặc apache zepline
- Khi query cần LIMIT lại result nếu không có thể dẫn đến lỗi OutOfMemory.
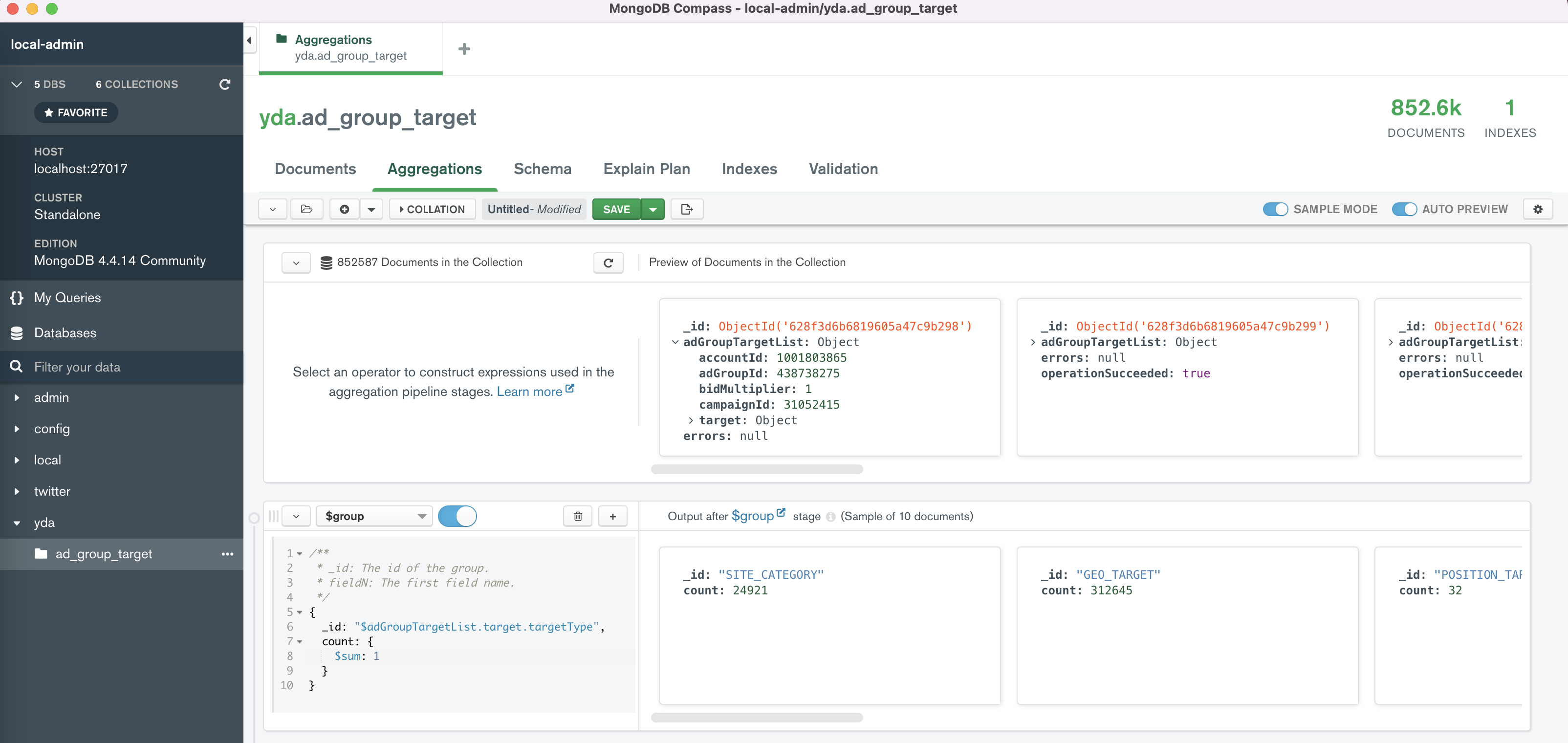
Dùng mongodb với mongodb compass
Do mongodb import chỉ hỗ trợ 1 file nên FDH đã phát triển 1 tool có thể import nhiều files gzipped json: https://github.com/FlintersVN/fdhutil
- Tạo database và collection.

- Import
rval.valuesvào db
./bin/fdhutil mongo-import --db yda \
--collection ad_group_target \
--username root --password example \
--dir /Users/huy_nq/yda/ad_group_target/2022/05/26/13 \
--json-path "$.rval.values[*]" -v --gunzip --drop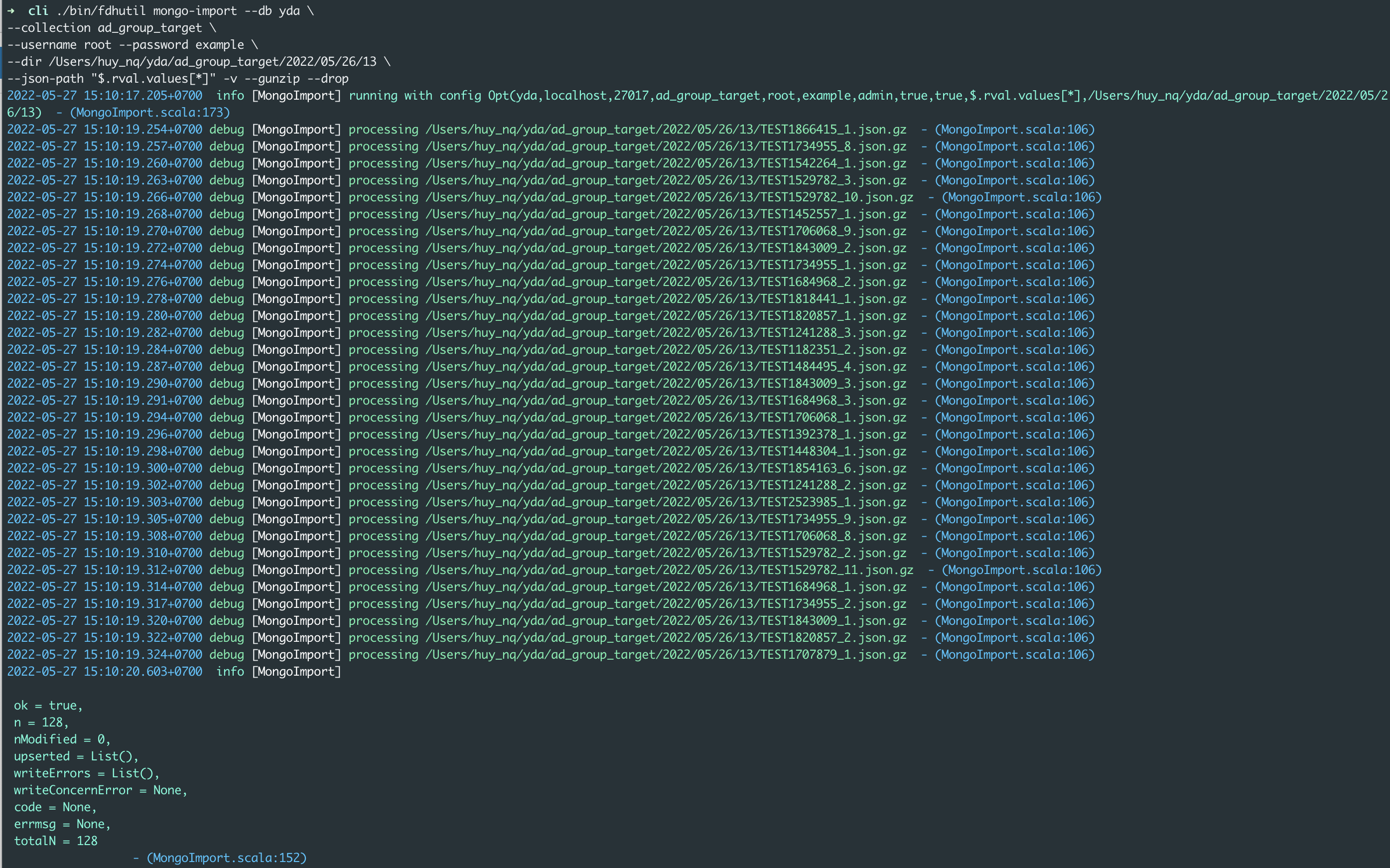
- Đếm các số bản ghi theo
value.adGroupTargetList.target.targetType
Ưu điểm
- Document database nên ko cần tạo schema
- Có thể index để tăng tốc độ query
Nhược điểm
- Phải học thêm mongodb query
- Setting mặc định của mongodb compass limit record là 10000, cần phải setting lại để có thể query trên toàn bộ data.
Hi vọng bài viết có thể mang lại những thông tin hữu ích để công việc có thể thực hiện được 1 cách dễ dàng hơn.
Điểm qua các công cụ vẽ biểu đồ bằng code phổ biến hiện nay
