Tìm kiếm trong không gian trạng thái và thuật toán Simulated Annealing
Trong bài này, mình sẽ giới thiệu về một giải thuật tìm kiếm cục bộ, thuật toán Simulated Annealing. Để đơn giản, mình sẽ giới thiệu về bài toán kinh điển, “Người bán hàng” – Bài toán tìm đường đi ngắn nhất đi qua tất cả các đỉnh, mỗi đỉnh đúng một lần, và trở về đỉnh xuất phát. Nhưng so với các giải thuật cổ điển như Dijkstra, Bellman-Ford, Floyd-Warshall, Johnson,.. nếu sử dụng giải thuật tìm kiếm cục bộ, sẽ cho phép ta tìm được đường đi ngắn nhất với 1 triệu đỉnh, mà với các thuật toán cổ điển sẽ không thể thực hiện nổi. Ta sẽ coi mỗi một lựa chọn đường đi như một trạng thái, thay vì xét từng đỉnh như trong các bài toán đồ thị.

Đối với các bài toán AI, thực tế có thể thấy rằng có một số lượng lớn các bài toán liên quan đến tìm kiếm hay hay đúng hơn là tìm ra những trạng thái, tính chất hoặc những hành động thoả mãn một điều kiện cho trước. Ví dụ:
- Làm thế nào để tim được nước cờ tối ưu mà vẫn tuân theo luật chơi, nhưng nước cờ đó phải tạo ưu thế cho mình
- Lập lịch, lập thời gian biểu để thoả mãn một tiêu chí nào đó
- Tìm đường đi sao cho thoả mãn các tiêu chí tối ưu
Có thể tóm lược tổng quát như sau. Tại một thời điểm, ta đang ở một trạng thái A0, tiếp theo ta muốn tìm một trạng thái A1 để sao cho trạng thái A1 đó là tốt nhất đối với mình ( ví dụ như khi đánh cờ, ta đang ở trạng thái thứ n, đến lượt tiếp theo, tại trạng thái n+1 ta muốn chọn ra nước cờ tối ưu để di chuyển, với con người điều đó có thể đơn giản, nhưng để máy tính tìm được thì hoàn toàn không dễ dàng). Với các bài toán tìm kiếm giải thuật tương ứng có thể chia làm 3 loại như sau: (1) Tìm kiếm mù, (2) Tìm kiếm có thông tin, (3) Tìm kiếm cục bộ
- Tìm kiếm mù: Với một trạng thái cho trước, để tìm ra trạng thái tiếp theo, hoàn toàn không có thông tin nên việc chọn ra trạng thái thường theo một thứ tự cho trước, nên phương pháp này chỉ phù hợp với những bài toán có ít trạng thái.
- Tìm kiếm có thông tin: So với tìm kiếm mù, giải thuật sẽ tìm kiếm những trạng thái tối ưu dựa trên những thông tin cho trước, nên việc tìm ra trạng thái tối ưu sẽ nhanh hơn.
- Tìm kiếm cục bộ: Đối với giải thuật này thường không càn thiết phải lưu lại các trạng thái, thích hợp hơn so với tìm kiếm có thông tin đối với các bài có số lượng trạng thái cực lớn trong thực tế.
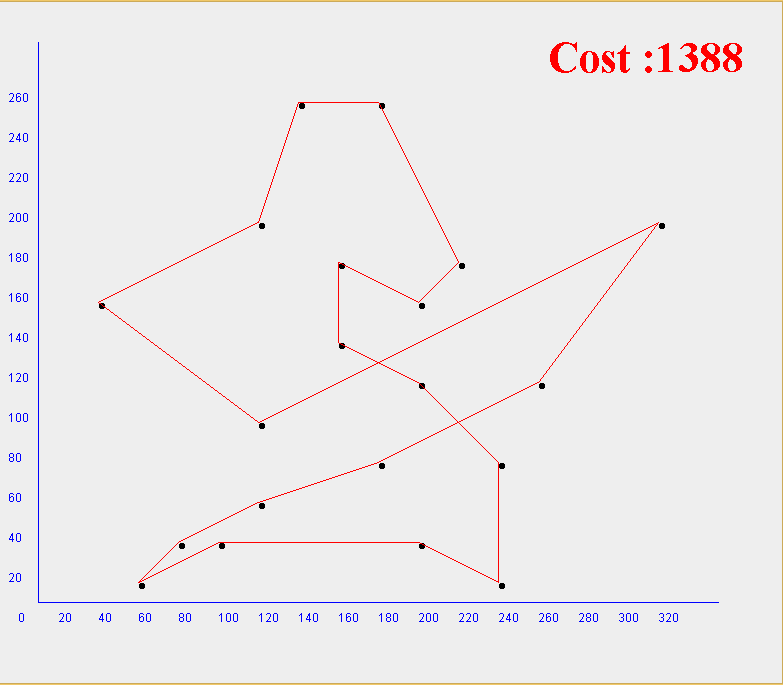
Ví dụ có n thành phố : A = {0,1,2,3,…,n}
Thuật toán được trình bày như sau:
For t = 1 to m 1. chọn ngẫu nhiên y ∈ N(x) a) tính Δ(x,y) = Obj(y) – Obj(x) b) if Δ(x,y) < 0 then p = 1 c) else p = exp(−Δ(x,y)/T) d) if rand[0,1] < p then x ← y. // lời giải y tốt hơn x e) if Obj(x) < Obj(x*) then x* ← x // chuyển sang y với xác suất p. 2. giảm T theo sơ đồ C return x* //x* là trạng thái tốt nhất trong số những trạng thái đã xem xét
Có thể giải thích như sau:
- Việc chọn ra trạng thái y là một các ngẫu nhiên (Đối với bài toán Người bán hàng, trạng thái y chính là chi phí cho 1 tổ hợp bất kì được chọn ra từ A, ví dụ: A0 = {3,6,9,2,…n, n-3, n-9}, chi phí Obj = 100)
// Creates a random individual
public void generateIndividual() {
// Loop through all our destination cities and add them to our tour
for (int cityIndex = 0; cityIndex < TourManager.numberOfCities(); cityIndex++) {
setCity(cityIndex, TourManager.getCity(cityIndex));
}
// Randomly reorder the tour
Collections.shuffle(tour);
}- Việc tính Δ(x,y) = Obj(y) – Obj(x) . Tại bước này ta so sánh trạng thái trước và trạng thái vừa sinh ra (Giả sử Obj(n+1) = 90, Obj(n) = 92. Vậy Δ(x,y) = 90 – 92 = 2 )
- if Δ(x,y) < 0 then p = 1. Tại bước này, ta kiếm tra, nếu Δ(x,y) < 0 điều đó có nghĩa là trạng thái sau tốt hơn trạng thái trước. ta sẽ xét xác suất p = 1
- Giả sử nếu Δ(x,y) > 0, thì điều đó có nghĩa là trạng thái sau tồi hơn trạng thái trước. Thì ta sẽ xét trạng thái p = exp(−Δ(x,y)/T). Tại bước này là bước quan trọng nhất, vì thay vì lựa chọn phương án tối ưu hơn, với thuật toán này sẵn sàng chọn một phương án tồi hơn, hoàn toàn phụ thuộc vào xác suất p được sinh ra. Tại sao lại vậy ? Vì nếu ta chỉ lựa chọn các phương án tối ưu hơn, đôi khi ta sẽ chỉ tìm được các trạng thái tối ưu cục bộ, mà bỏ qua trạng thái tối ưu toàn cục ( giống như việc tìm min, max trong bài toán giải đồ thị, điều kiện cần để một điểm m(x,y) là min hoặc max, thì điểm m phải là điểm cực trị, nhưng chưa chắc đó là điểm min, max). T là số lần lặp, exp(−Δ(x,y)/T) công thức này phụ thuộc vào T, tức là khi T càng nhỏ, thì p sẽ càng nhỏ và tiến tới 0, điều đó có nghĩa là khi bắt đầu chạy thuật toán, ta sẵn sàng lựa chọn các phương án ít tối ưu hơn, nhưng càng về cuối vòng lặp, ta sẽ hạn chế dần việc chọn các phương án tồi, vì khi đó các trạng thái tốt đã dần được tìm ra.
// Calculate the acceptance probability
public static double acceptanceProbability(int energy, int newEnergy, double temperature) {
// If the new solution is better, accept it
if (newEnergy < energy) {
return 1.0;
}
// If the new solution is worse, calculate an acceptance probability
return Math.exp((energy - newEnergy) / temperature);
}- if rand[0,1] < p then x ← y. Ta sẽ random một số bất kỳ từ 0 -> 1, nếu số đó nhỏ hơn p thì ta sẽ lưu trạng thái mới đó
- if Obj(x) < Obj(x*) then x* ← x. Nếu trạng thái hiện tại tối ưu nhất thì ta sẽ lưu lại trạng thái đó.
// Keep track of the best solution found
if (currentSolution.getDistance() < best.getDistance()) {
best = new Tour(currentSolution.getTour());
}- Giảm T
// Cool system temp *= 1 - coolingRate;
Đặc điểm của thuật toán này luôn cho ta trạng thái tốt, mặc dù chưa phải trạng thái tốt nhất nhưng luôn là trạng thái có thể chấp nhận nếu T đủ lớn.
[ML – 18] Convolution Neural Network – Part 1
[ML – 03] Minimize cost function with Gradient descent algorithm